Measuring Stochastic Data Complexity with Boltzmann Influence Functions
2406.02745
0
0
📊
Abstract
Estimating the uncertainty of a model's prediction on a test point is a crucial part of ensuring reliability and calibration under distribution shifts. A minimum description length approach to this problem uses the predictive normalized maximum likelihood (pNML) distribution, which considers every possible label for a data point, and decreases confidence in a prediction if other labels are also consistent with the model and training data. In this work we propose IF-COMP, a scalable and efficient approximation of the pNML distribution that linearizes the model with a temperature-scaled Boltzmann influence function. IF-COMP can be used to produce well-calibrated predictions on test points as well as measure complexity in both labelled and unlabelled settings. We experimentally validate IF-COMP on uncertainty calibration, mislabel detection, and OOD detection tasks, where it consistently matches or beats strong baseline methods.
Create account to get full access
Overview
- Estimating uncertainty in model predictions is crucial for reliability and calibration under distribution shifts
- This paper proposes a new approach called IF-COMP that approximates the predictive normalized maximum likelihood (pNML) distribution for efficient uncertainty estimation
- IF-COMP uses a temperature-scaled Boltzmann influence function to linearize the model and produce well-calibrated predictions on test points
- The method can also be used to measure complexity in both labeled and unlabeled settings
- Experiments show IF-COMP matches or exceeds strong baseline methods for uncertainty calibration, mislabel detection, and out-of-distribution (OOD) detection
Plain English Explanation
When a machine learning model makes a prediction, it's important to understand how certain or uncertain the model is about that prediction. This is crucial for ensuring the model is reliable, especially when the data it's tested on is different from the data it was trained on.
The approach proposed in this paper, called IF-COMP, tries to estimate the uncertainty of a model's predictions in a clever way. It looks at all the possible labels the model could assign to a data point, and decreases the confidence in the predicted label if other labels also seem plausible based on the model and the training data. This is similar to how a deeper understanding of black box predictions can provide more insight.
The key innovation in IF-COMP is that it can do this uncertainty estimation efficiently, by simplifying the model using a mathematical trick called a "temperature-scaled Boltzmann influence function". This allows IF-COMP to not only produce well-calibrated predictions, but also measure the complexity of the model in both labeled and unlabeled settings, similar to how density softmax can efficiently estimate model uncertainty.
The paper shows through experiments that IF-COMP performs as well as or better than other strong methods for tasks like detecting when a model is making mistakes or detecting when the test data is very different from the training data.
Technical Explanation
The key idea behind the IF-COMP method is to approximate the predictive normalized maximum likelihood (pNML) distribution, which considers all possible labels for a data point and decreases confidence in the predicted label if other labels are also consistent with the model and training data. This is similar to the approach used in measuring calibration of discrete probabilistic neural networks.
To do this efficiently, IF-COMP linearizes the model using a temperature-scaled Boltzmann influence function. This allows it to compute the pNML distribution in a scalable way, rather than having to consider every possible label. The temperature parameter controls the trade-off between accuracy and efficiency.
Experimentally, the authors validate IF-COMP on three tasks: uncertainty calibration, mislabel detection, and out-of-distribution (OOD) detection. They show that IF-COMP can produce well-calibrated predictions and effectively detect mislabeled examples and OOD data, matching or exceeding the performance of strong baseline methods.
The approach is related to ideas from information bottleneck analysis of deep neural networks and sample complexity for parameter estimation in logistic regression, but applies them in a novel way to the problem of uncertainty estimation.
Critical Analysis
The paper presents a thorough experimental evaluation of the IF-COMP method, but there are a few potential limitations and areas for further research:
- The method relies on a temperature parameter that needs to be tuned, which could make it more challenging to apply in practice without careful hyperparameter optimization.
- The authors only evaluate IF-COMP on image classification tasks, so it's unclear how well the method would generalize to other problem domains.
- The paper does not address potential biases or fairness issues that could arise from the uncertainty estimates produced by IF-COMP, which is an important consideration for real-world applications.
Additionally, while the authors claim that IF-COMP can be used to measure complexity in both labeled and unlabeled settings, the paper does not provide a detailed explanation or evaluation of this capability.
Overall, the IF-COMP method seems promising for improving the reliability and calibration of model predictions, but further research is needed to fully understand its limitations and broader applicability.
Conclusion
This paper introduces a novel approach called IF-COMP for efficiently estimating the uncertainty of a model's predictions on test data. By approximating the predictive normalized maximum likelihood (pNML) distribution, IF-COMP can produce well-calibrated predictions and detect mislabeled examples and out-of-distribution data.
The key innovation is the use of a temperature-scaled Boltzmann influence function to linearize the model, allowing for scalable computation of the pNML distribution. Experiments show IF-COMP performing as well as or better than strong baseline methods on a range of uncertainty-related tasks.
While the paper raises a few limitations and areas for further research, the IF-COMP method represents a significant advancement in the field of uncertainty estimation for machine learning models. Its ability to provide reliable and interpretable uncertainty estimates could have important implications for the safe and responsible deployment of AI systems in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
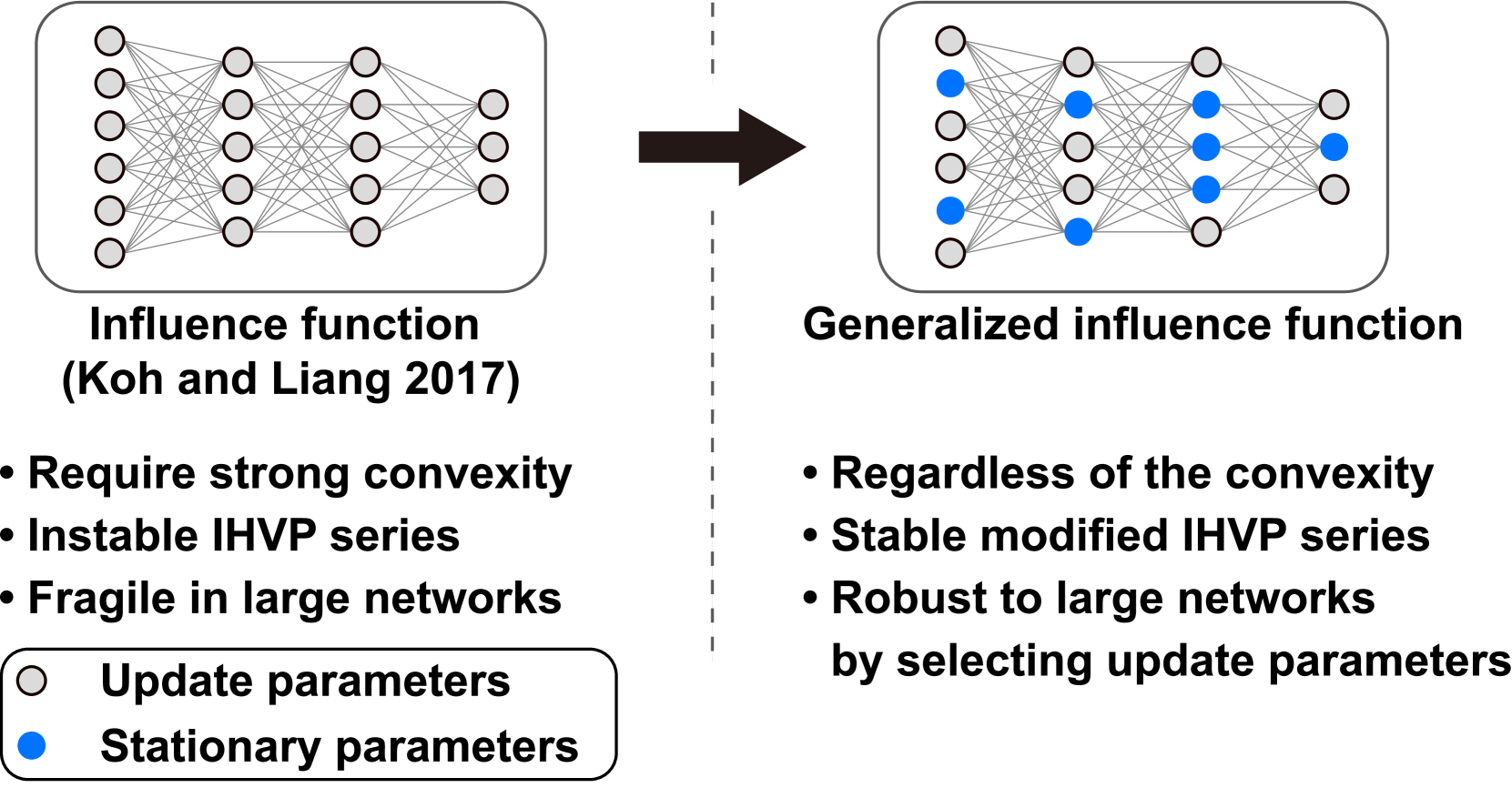
Deeper Understanding of Black-box Predictions via Generalized Influence Functions
Hyeonsu Lyu, Jonggyu Jang, Sehyun Ryu, Hyun Jong Yang
0
0
Influence functions (IFs) elucidate how training data changes model behavior. However, the increasing size and non-convexity in large-scale models make IFs inaccurate. We suspect that the fragility comes from the first-order approximation which may cause nuisance changes in parameters irrelevant to the examined data. However, simply computing influence from the chosen parameters can be misleading, as it fails to nullify the hidden effects of unselected parameters on the analyzed data. Thus, our approach introduces generalized IFs, precisely estimating target parameters' influence while nullifying nuisance gradient changes on fixed parameters. We identify target update parameters closely associated with the input data by the output- and gradient-based parameter selection methods. We verify the generalized IFs with various alternatives of IFs on the class removal and label change tasks. The experiments align with the less is more philosophy, demonstrating that updating only 5% of the model produces more accurate results than other influence functions across all tasks. We believe our proposal works as a foundational tool for optimizing models, conducting data analysis, and enhancing AI interpretability beyond the limitation of IFs. Codes are available at https://github.com/hslyu/GIF.
5/7/2024
🧠
On Measuring Calibration of Discrete Probabilistic Neural Networks
Spencer Young, Porter Jenkins
0
0
As machine learning systems become increasingly integrated into real-world applications, accurately representing uncertainty is crucial for enhancing their safety, robustness, and reliability. Training neural networks to fit high-dimensional probability distributions via maximum likelihood has become an effective method for uncertainty quantification. However, such models often exhibit poor calibration, leading to overconfident predictions. Traditional metrics like Expected Calibration Error (ECE) and Negative Log Likelihood (NLL) have limitations, including biases and parametric assumptions. This paper proposes a new approach using conditional kernel mean embeddings to measure calibration discrepancies without these biases and assumptions. Preliminary experiments on synthetic data demonstrate the method's potential, with future work planned for more complex applications.
5/22/2024
Invariant Probabilistic Prediction
Alexander Henzi, Xinwei Shen, Michael Law, Peter Buhlmann
0
0
In recent years, there has been a growing interest in statistical methods that exhibit robust performance under distribution changes between training and test data. While most of the related research focuses on point predictions with the squared error loss, this article turns the focus towards probabilistic predictions, which aim to comprehensively quantify the uncertainty of an outcome variable given covariates. Within a causality-inspired framework, we investigate the invariance and robustness of probabilistic predictions with respect to proper scoring rules. We show that arbitrary distribution shifts do not, in general, admit invariant and robust probabilistic predictions, in contrast to the setting of point prediction. We illustrate how to choose evaluation metrics and restrict the class of distribution shifts to allow for identifiability and invariance in the prototypical Gaussian heteroscedastic linear model. Motivated by these findings, we propose a method to yield invariant probabilistic predictions, called IPP, and study the consistency of the underlying parameters. Finally, we demonstrate the empirical performance of our proposed procedure on simulated as well as on single-cell data.
6/18/2024

A Geometric View of Data Complexity: Efficient Local Intrinsic Dimension Estimation with Diffusion Models
Hamidreza Kamkari, Brendan Leigh Ross, Rasa Hosseinzadeh, Jesse C. Cresswell, Gabriel Loaiza-Ganem
0
0
High-dimensional data commonly lies on low-dimensional submanifolds, and estimating the local intrinsic dimension (LID) of a datum -- i.e. the dimension of the submanifold it belongs to -- is a longstanding problem. LID can be understood as the number of local factors of variation: the more factors of variation a datum has, the more complex it tends to be. Estimating this quantity has proven useful in contexts ranging from generalization in neural networks to detection of out-of-distribution data, adversarial examples, and AI-generated text. The recent successes of deep generative models present an opportunity to leverage them for LID estimation, but current methods based on generative models produce inaccurate estimates, require more than a single pre-trained model, are computationally intensive, or do not exploit the best available deep generative models, i.e. diffusion models (DMs). In this work, we show that the Fokker-Planck equation associated with a DM can provide a LID estimator which addresses all the aforementioned deficiencies. Our estimator, called FLIPD, is compatible with all popular DMs, and outperforms existing baselines on LID estimation benchmarks. We also apply FLIPD on natural images where the true LID is unknown. Compared to competing estimators, FLIPD exhibits a higher correlation with non-LID measures of complexity, better matches a qualitative assessment of complexity, and is the only estimator to remain tractable with high-resolution images at the scale of Stable Diffusion.
6/7/2024