DeforestVis: Behavior Analysis of Machine Learning Models with Surrogate Decision Stumps
2304.00133
0
0
📈
Abstract
As the complexity of machine learning (ML) models increases and their application in different (and critical) domains grows, there is a strong demand for more interpretable and trustworthy ML. A direct, model-agnostic, way to interpret such models is to train surrogate models-such as rule sets and decision trees-that sufficiently approximate the original ones while being simpler and easier-to-explain. Yet, rule sets can become very lengthy, with many if-else statements, and decision tree depth grows rapidly when accurately emulating complex ML models. In such cases, both approaches can fail to meet their core goal-providing users with model interpretability. To tackle this, we propose DeforestVis, a visual analytics tool that offers summarization of the behaviour of complex ML models by providing surrogate decision stumps (one-level decision trees) generated with the Adaptive Boosting (AdaBoost) technique. DeforestVis helps users to explore the complexity versus fidelity trade-off by incrementally generating more stumps, creating attribute-based explanations with weighted stumps to justify decision making, and analysing the impact of rule overriding on training instance allocation between one or more stumps. An independent test set allows users to monitor the effectiveness of manual rule changes and form hypotheses based on case-by-case analyses. We show the applicability and usefulness of DeforestVis with two use cases and expert interviews with data analysts and model developers.
Create account to get full access
Overview
- As machine learning models become more complex and are used in critical domains, there is a growing need for interpretable and trustworthy models.
- Surrogate models like rule sets and decision trees can approximate complex models, but they can also become very lengthy and difficult to interpret.
- To address this, the researchers propose DeforestVis, a visual analytics tool that generates simpler surrogate models using the Adaptive Boosting (AdaBoost) technique.
Plain English Explanation
Machine learning models are becoming increasingly sophisticated, and they're being used in more and more important areas of our lives. This means it's really important that we can understand how these models work and trust that they're making good decisions.
One way to make complex models more interpretable is to train simpler "surrogate" models, like decision trees or rule sets, that can approximate the behavior of the original model. But the problem is that these surrogate models can end up being really complicated, with tons of if-then statements or super deep decision trees. So they end up being just as hard to understand as the original model.
The researchers in this paper came up with a tool called DeforestVis that tries to solve this problem. DeforestVis uses a technique called Adaptive Boosting (AdaBoost) to generate simpler "decision stumps" - one-level decision trees - that can still capture the key decisions made by the original complex model.
The tool lets users explore the trade-off between the complexity of the surrogate model and how well it matches the original. Users can also see explanations for the model's decisions, and analyze how changing the rules impacts the training data. This can help users build trust in the model and make informed decisions about how to use it.
Technical Explanation
The researchers propose DeforestVis, a visual analytics tool that addresses the challenge of interpreting complex machine learning models. DeforestVis uses the Adaptive Boosting (AdaBoost) technique to generate simple "decision stumps" (one-level decision trees) that can approximate the behavior of the original complex model.
The tool allows users to explore the trade-off between the complexity and fidelity of the surrogate model. Users can incrementally generate more decision stumps, and the tool provides weighted explanations for the model's decisions based on the stumps. Users can also analyze how changes to the decision rules impact the allocation of training instances between stumps.
An independent test set enables users to monitor the effectiveness of manual rule changes and form hypotheses based on case-by-case analyses. The researchers demonstrate the applicability and usefulness of DeforestVis through two use cases and expert interviews with data analysts and model developers.
This approach contrasts with other efforts to interpret complex models, such as MetaStackVis, interpretable client decision tree aggregation, and DimVis, which focus on different aspects of model interpretation and transparency.
Critical Analysis
The researchers acknowledge that while DeforestVis can generate simpler surrogate models, the decision stumps may still not be as simple or intuitive as users would like. There is also a risk that the weighted explanations provided by the tool could be misleading if the stumps do not fully capture the complexity of the original model.
Additionally, the paper does not discuss the potential for the decision stumps to be biased or discriminatory, which is an important consideration when using interpretable models in high-stakes domains. The researchers could have also explored ways to ensure the stability and robustness of the surrogate models, as changes to the original model could potentially lead to significant changes in the explanations.
Overall, DeforestVis represents an interesting approach to interpreting complex machine learning models, but there are still important considerations and limitations that could be addressed in future research.
Conclusion
The growing complexity of machine learning models, along with their increasing use in critical domains, has created a strong demand for more interpretable and trustworthy AI systems. The DeforestVis tool proposed in this paper represents an important step towards addressing this challenge by generating simple surrogate models that can approximate the behavior of complex machine learning models.
By allowing users to explore the trade-off between model complexity and fidelity, and providing explanations for the model's decisions, DeforestVis has the potential to help build trust and facilitate better decision-making in a wide range of applications. While the tool has some limitations, it serves as a valuable contribution to the ongoing efforts to make AI systems more transparent and accountable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
VisRuler: Visual Analytics for Extracting Decision Rules from Bagged and Boosted Decision Trees
Angelos Chatzimparmpas, Rafael M. Martins, Andreas Kerren
0
0
Bagging and boosting are two popular ensemble methods in machine learning (ML) that produce many individual decision trees. Due to the inherent ensemble characteristic of these methods, they typically outperform single decision trees or other ML models in predictive performance. However, numerous decision paths are generated for each decision tree, increasing the overall complexity of the model and hindering its use in domains that require trustworthy and explainable decisions, such as finance, social care, and health care. Thus, the interpretability of bagging and boosting algorithms, such as random forest and adaptive boosting, reduces as the number of decisions rises. In this paper, we propose a visual analytics tool that aims to assist users in extracting decisions from such ML models via a thorough visual inspection workflow that includes selecting a set of robust and diverse models (originating from different ensemble learning algorithms), choosing important features according to their global contribution, and deciding which decisions are essential for global explanation (or locally, for specific cases). The outcome is a final decision based on the class agreement of several models and the explored manual decisions exported by users. We evaluated the applicability and effectiveness of VisRuler via a use case, a usage scenario, and a user study. The evaluation revealed that most users managed to successfully use our system to explore decision rules visually, performing the proposed tasks and answering the given questions in a satisfying way.
4/19/2024
🚀
MetaStackVis: Visually-Assisted Performance Evaluation of Metamodels
Ilya Ploshchik, Angelos Chatzimparmpas, Andreas Kerren
0
0
Stacking (or stacked generalization) is an ensemble learning method with one main distinctiveness from the rest: even though several base models are trained on the original data set, their predictions are further used as input data for one or more metamodels arranged in at least one extra layer. Composing a stack of models can produce high-performance outcomes, but it usually involves a trial-and-error process. Therefore, our previously developed visual analytics system, StackGenVis, was mainly designed to assist users in choosing a set of top-performing and diverse models by measuring their predictive performance. However, it only employs a single logistic regression metamodel. In this paper, we investigate the impact of alternative metamodels on the performance of stacking ensembles using a novel visualization tool, called MetaStackVis. Our interactive tool helps users to visually explore different singular and pairs of metamodels according to their predictive probabilities and multiple validation metrics, as well as their ability to predict specific problematic data instances. MetaStackVis was evaluated with a usage scenario based on a medical data set and via expert interviews.
4/19/2024
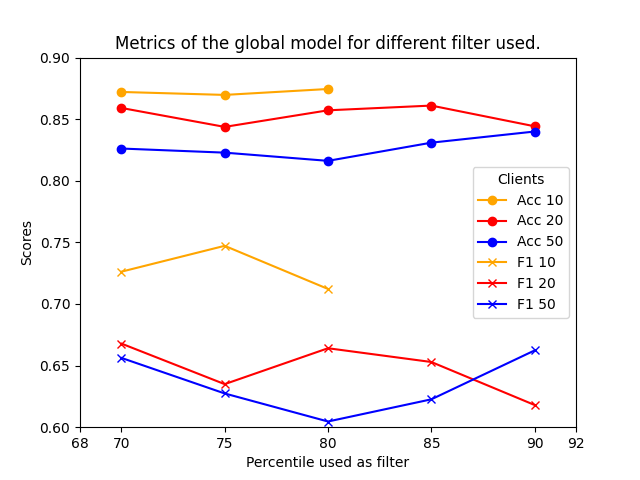
An Interpretable Client Decision Tree Aggregation process for Federated Learning
Alberto Argente-Garrido, Cristina Zuheros, M. Victoria Luz'on, Francisco Herrera
0
0
Trustworthy Artificial Intelligence solutions are essential in today's data-driven applications, prioritizing principles such as robustness, safety, transparency, explainability, and privacy among others. This has led to the emergence of Federated Learning as a solution for privacy and distributed machine learning. While decision trees, as self-explanatory models, are ideal for collaborative model training across multiple devices in resource-constrained environments such as federated learning environments for injecting interpretability in these models. Decision tree structure makes the aggregation in a federated learning environment not trivial. They require techniques that can merge their decision paths without introducing bias or overfitting while keeping the aggregated decision trees robust and generalizable. In this paper, we propose an Interpretable Client Decision Tree Aggregation process for Federated Learning scenarios that keeps the interpretability and the precision of the base decision trees used for the aggregation. This model is based on aggregating multiple decision paths of the decision trees and can be used on different decision tree types, such as ID3 and CART. We carry out the experiments within four datasets, and the analysis shows that the tree built with the model improves the local models, and outperforms the state-of-the-art.
4/4/2024

Learning accurate and interpretable decision trees
Maria-Florina Balcan, Dravyansh Sharma
0
0
Decision trees are a popular tool in machine learning and yield easy-to-understand models. Several techniques have been proposed in the literature for learning a decision tree classifier, with different techniques working well for data from different domains. In this work, we develop approaches to design decision tree learning algorithms given repeated access to data from the same domain. We propose novel parameterized classes of node splitting criteria in top-down algorithms, which interpolate between popularly used entropy and Gini impurity based criteria, and provide theoretical bounds on the number of samples needed to learn the splitting function appropriate for the data at hand. We also study the sample complexity of tuning prior parameters in Bayesian decision tree learning, and extend our results to decision tree regression. We further consider the problem of tuning hyperparameters in pruning the decision tree for classical pruning algorithms including min-cost complexity pruning. We also study the interpretability of the learned decision trees and introduce a data-driven approach for optimizing the explainability versus accuracy trade-off using decision trees. Finally, we demonstrate the significance of our approach on real world datasets by learning data-specific decision trees which are simultaneously more accurate and interpretable.
5/28/2024