MetaStackVis: Visually-Assisted Performance Evaluation of Metamodels
2212.03539
0
0
🚀
Abstract
Stacking (or stacked generalization) is an ensemble learning method with one main distinctiveness from the rest: even though several base models are trained on the original data set, their predictions are further used as input data for one or more metamodels arranged in at least one extra layer. Composing a stack of models can produce high-performance outcomes, but it usually involves a trial-and-error process. Therefore, our previously developed visual analytics system, StackGenVis, was mainly designed to assist users in choosing a set of top-performing and diverse models by measuring their predictive performance. However, it only employs a single logistic regression metamodel. In this paper, we investigate the impact of alternative metamodels on the performance of stacking ensembles using a novel visualization tool, called MetaStackVis. Our interactive tool helps users to visually explore different singular and pairs of metamodels according to their predictive probabilities and multiple validation metrics, as well as their ability to predict specific problematic data instances. MetaStackVis was evaluated with a usage scenario based on a medical data set and via expert interviews.
Create account to get full access
Overview
- Stacking is a type of ensemble machine learning technique where multiple base models are trained on the original data, and their predictions are then used as input for a metamodel.
- Composing a stack of models can produce high-performance results, but it often requires a trial-and-error process to find the right combination of models.
- The authors previously developed StackGenVis, a visual analytics system to help users choose top-performing and diverse base models.
- However, StackGenVis only used a single logistic regression metamodel, so the authors investigate the impact of alternative metamodels in this paper.
Plain English Explanation
Stacking is a way to combine multiple machine learning models to get better predictions. In a stacking system, the original data is used to train several base models. Then, the predictions from these base models are used as input for a metamodel, which makes the final prediction.
Stacking can lead to high-performance results, but finding the right combination of base and metamodels can be tricky. The authors previously created a tool called StackGenVis to help users choose a good set of base models. However, StackGenVis only used one type of metamodel, a logistic regression model.
In this paper, the authors investigate how using different types of metamodels impacts the performance of stacking ensembles. They developed a new visualization tool called MetaStackVis to help users explore different metamodel options and compare their performance.
Technical Explanation
The authors' previous work, StackGenVis, focused on helping users choose a set of diverse and high-performing base models for a stacking ensemble. However, StackGenVis only used a single logistic regression metamodel.
In this paper, the authors present a new tool called MetaStackVis that allows users to visually explore the impact of different singular and paired metamodels on the predictive performance of stacking ensembles. MetaStackVis provides various visualizations to compare metamodels based on their predictive probabilities, multiple validation metrics, and their ability to correctly predict specific problematic data instances.
The authors evaluate MetaStackVis through a usage scenario on a medical dataset and expert interviews. The results show that MetaStackVis can help users gain insights into how different metamodels affect the overall performance of stacking ensembles, beyond what was possible with the previous StackGenVis tool.
Critical Analysis
The paper provides a valuable contribution by investigating the impact of metamodels on the performance of stacking ensembles, which is an important aspect of this ensemble learning technique that has not been widely explored. The authors' development of MetaStackVis, a novel visualization tool, is a significant step forward in supporting users in the model selection process for stacking.
However, the paper does not delve into the potential limitations of the MetaStackVis tool or the stacking approach itself. For example, the authors do not discuss the computational complexity or scalability of the tool as the number of base and metamodels increases, or the interpretability of the final stacked model.
Additionally, the paper could have benefited from a more comprehensive comparison of MetaStackVis to other visual analytics tools for model selection, such as DeforestVis, VisEvol, or VisRuler, to better situate the contributions of this work within the broader landscape of visual analytics for machine learning model selection and interpretation.
Conclusion
This paper presents a novel visualization tool, MetaStackVis, that enables users to explore the impact of different metamodels on the performance of stacking ensembles. By providing a range of visualizations to compare metamodel performance, MetaStackVis expands upon the authors' previous work on StackGenVis and offers a more comprehensive approach to supporting users in the model selection process for stacking.
The evaluation of MetaStackVis suggests that it can help users gain valuable insights into how the choice of metamodel affects the overall predictive performance of stacking ensembles, which is an important consideration for practitioners seeking to leverage the power of ensemble learning techniques. As the field of machine learning continues to evolve, tools like MetaStackVis will become increasingly valuable in empowering users to make informed decisions about their model architectures and configurations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
View selection in multi-view stacking: Choosing the meta-learner
Wouter van Loon, Marjolein Fokkema, Botond Szabo, Mark de Rooij
0
0
Multi-view stacking is a framework for combining information from different views (i.e. different feature sets) describing the same set of objects. In this framework, a base-learner algorithm is trained on each view separately, and their predictions are then combined by a meta-learner algorithm. In a previous study, stacked penalized logistic regression, a special case of multi-view stacking, has been shown to be useful in identifying which views are most important for prediction. In this article we expand this research by considering seven different algorithms to use as the meta-learner, and evaluating their view selection and classification performance in simulations and two applications on real gene-expression data sets. Our results suggest that if both view selection and classification accuracy are important to the research at hand, then the nonnegative lasso, nonnegative adaptive lasso and nonnegative elastic net are suitable meta-learners. Exactly which among these three is to be preferred depends on the research context. The remaining four meta-learners, namely nonnegative ridge regression, nonnegative forward selection, stability selection and the interpolating predictor, show little advantages in order to be preferred over the other three.
4/16/2024
DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs
Lingchen Meng, Jianwei Yang, Rui Tian, Xiyang Dai, Zuxuan Wu, Jianfeng Gao, Yu-Gang Jiang
0
0
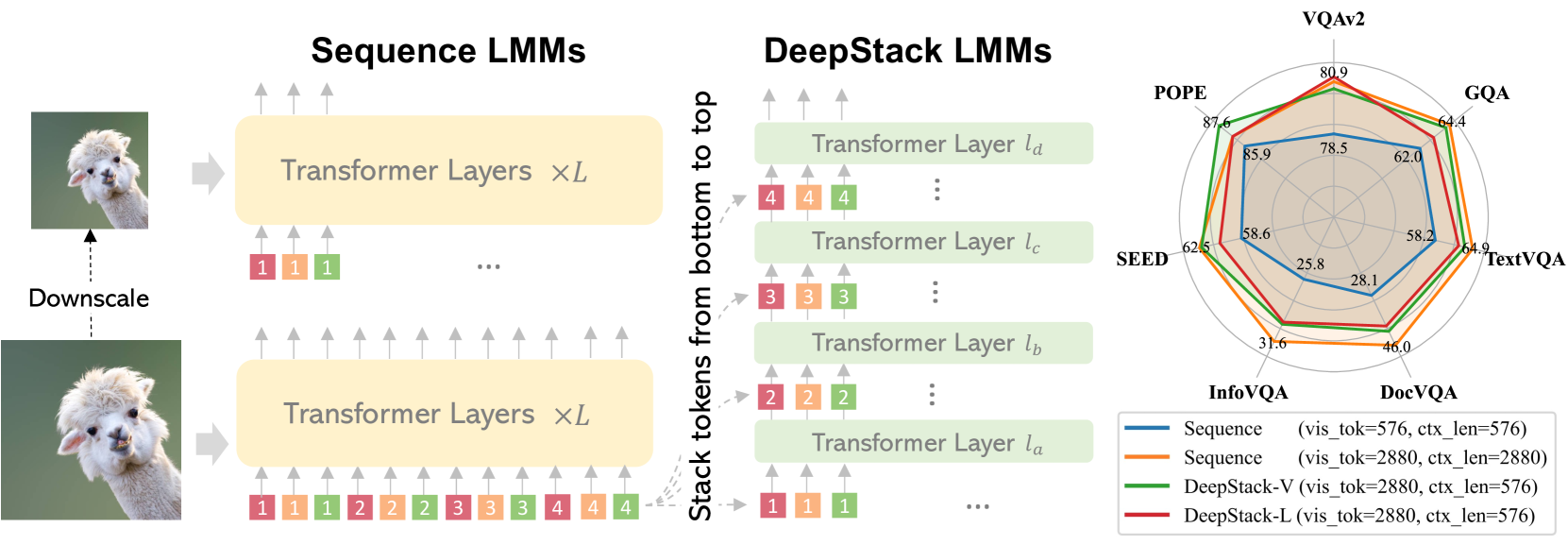
Most large multimodal models (LMMs) are implemented by feeding visual tokens as a sequence into the first layer of a large language model (LLM). The resulting architecture is simple but significantly increases computation and memory costs, as it has to handle a large number of additional tokens in its input layer. This paper presents a new architecture DeepStack for LMMs. Considering $N$ layers in the language and vision transformer of LMMs, we stack the visual tokens into $N$ groups and feed each group to its aligned transformer layer textit{from bottom to top}. Surprisingly, this simple method greatly enhances the power of LMMs to model interactions among visual tokens across layers but with minimal additional cost. We apply DeepStack to both language and vision transformer in LMMs, and validate the effectiveness of DeepStack LMMs with extensive empirical results. Using the same context length, our DeepStack 7B and 13B parameters surpass their counterparts by textbf{2.7} and textbf{2.9} on average across textbf{9} benchmarks, respectively. Using only one-fifth of the context length, DeepStack rivals closely to the counterparts that use the full context length. These gains are particularly pronounced on high-resolution tasks, e.g., textbf{4.2}, textbf{11.0}, and textbf{4.0} improvements on TextVQA, DocVQA, and InfoVQA compared to LLaVA-1.5-7B, respectively. We further apply DeepStack to vision transformer layers, which brings us a similar amount of improvements, textbf{3.8} on average compared with LLaVA-1.5-7B.
6/7/2024
Stacking for Probabilistic Short-term Load Forecasting
Grzegorz Dudek
0
0
In this study, we delve into the realm of meta-learning to combine point base forecasts for probabilistic short-term electricity demand forecasting. Our approach encompasses the utilization of quantile linear regression, quantile regression forest, and post-processing techniques involving residual simulation to generate quantile forecasts. Furthermore, we introduce both global and local variants of meta-learning. In the local-learning mode, the meta-model is trained using patterns most similar to the query pattern.Through extensive experimental studies across 35 forecasting scenarios and employing 16 base forecasting models, our findings underscored the superiority of quantile regression forest over its competitors
6/18/2024
📈
DeforestVis: Behavior Analysis of Machine Learning Models with Surrogate Decision Stumps
Angelos Chatzimparmpas, Rafael M. Martins, Alexandru C. Telea, Andreas Kerren
0
0
As the complexity of machine learning (ML) models increases and their application in different (and critical) domains grows, there is a strong demand for more interpretable and trustworthy ML. A direct, model-agnostic, way to interpret such models is to train surrogate models-such as rule sets and decision trees-that sufficiently approximate the original ones while being simpler and easier-to-explain. Yet, rule sets can become very lengthy, with many if-else statements, and decision tree depth grows rapidly when accurately emulating complex ML models. In such cases, both approaches can fail to meet their core goal-providing users with model interpretability. To tackle this, we propose DeforestVis, a visual analytics tool that offers summarization of the behaviour of complex ML models by providing surrogate decision stumps (one-level decision trees) generated with the Adaptive Boosting (AdaBoost) technique. DeforestVis helps users to explore the complexity versus fidelity trade-off by incrementally generating more stumps, creating attribute-based explanations with weighted stumps to justify decision making, and analysing the impact of rule overriding on training instance allocation between one or more stumps. An independent test set allows users to monitor the effectiveness of manual rule changes and form hypotheses based on case-by-case analyses. We show the applicability and usefulness of DeforestVis with two use cases and expert interviews with data analysts and model developers.
4/19/2024