Demystifying Functional Random Forests: Novel Explainability Tools for Model Transparency in High-Dimensional Spaces

0

Sign in to get full access
Overview
- This paper presents novel explainability tools for functional random forest models in high-dimensional spaces.
- The tools aim to improve model transparency and interpretability.
- Key techniques include prototype-based explanations, counterfactual analysis, and functional decomposition.
Plain English Explanation
Random forests are powerful machine learning models that can handle complex, high-dimensional data. However, they can be difficult to interpret, especially when dealing with large feature spaces. This paper introduces several new techniques to make random forest models more transparent and understandable.
One approach is prototype-based explanations, which identify representative examples (prototypes) that characterize how the model makes predictions. This allows users to see the "typical" cases the model is basing its decisions on.
Another technique is counterfactual analysis, which shows how changing certain input features would change the model's output. This can help explain the model's reasoning and identify the most important factors driving its predictions.
The paper also explores functional decomposition, which breaks down the model's predictions into interpretable components related to different input features or combinations of features. This provides a more detailed understanding of how the model is using the available information.
Overall, these techniques aim to make random forest models more transparent and trustworthy, especially when working with complex, high-dimensional data. By giving users a better understanding of how the models work, it can help build confidence in their outputs and enable more informed decision-making.
Technical Explanation
The paper introduces several novel explainability tools for functional random forest models in high-dimensional spaces.
First, it presents a prototype-based explanation approach, which identifies representative examples (prototypes) that characterize how the model makes predictions. This allows users to see the "typical" cases the model is basing its decisions on. The paper also describes how to identify "critics" - examples that deviate from the prototypes and reveal the model's limitations.
Next, the paper explores counterfactual analysis for random forests. This technique shows how changing certain input features would change the model's output, helping to explain the model's reasoning and identify the most important factors driving its predictions.
Finally, the paper introduces a functional decomposition approach for random forests. This breaks down the model's predictions into interpretable components related to different input features or combinations of features, providing a more detailed understanding of how the model is using the available information.
The authors evaluate these techniques on several high-dimensional datasets, demonstrating their ability to improve model transparency and interpretability. They also discuss how the tools can be used to build trust in the model's outputs and enable more informed decision-making.
Critical Analysis
The paper presents a comprehensive set of novel explainability tools for functional random forest models, addressing an important challenge in the field of interpretable machine learning. The techniques introduced, such as prototype-based explanations, counterfactual analysis, and functional decomposition, provide valuable insights into how the models are making predictions, which can be crucial for building trust and understanding in high-stakes applications.
One potential limitation of the study is the reliance on specific high-dimensional datasets, which may limit the generalizability of the findings. It would be helpful to see the techniques applied to a wider range of datasets and problem domains to further demonstrate their versatility and effectiveness.
Additionally, the paper does not provide a detailed discussion of the computational complexity or scalability of the proposed methods, which could be an important consideration when working with very large or rapidly changing datasets. Further research into the efficiency and real-world practicality of these tools would be valuable.
Overall, the paper makes a significant contribution to the field of interpretable machine learning and provides a solid foundation for future work in this area. The novel explainability tools presented have the potential to greatly enhance the transparency and trust in functional random forest models, especially in high-dimensional, high-stakes applications.
Conclusion
This paper introduces several novel explainability tools for functional random forest models in high-dimensional spaces, addressing a key challenge in the field of interpretable machine learning. The techniques, including prototype-based explanations, counterfactual analysis, and functional decomposition, aim to improve model transparency and enable more informed decision-making.
By providing users with a better understanding of how the models are making predictions, these tools can help build trust in the model outputs and support their use in high-stakes applications. While the paper focuses on specific high-dimensional datasets, the techniques have the potential to be applied more broadly, offering a valuable contribution to the ongoing effort to make complex machine learning models more interpretable and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Demystifying Functional Random Forests: Novel Explainability Tools for Model Transparency in High-Dimensional Spaces
Fabrizio Maturo, Annamaria Porreca
The advent of big data has raised significant challenges in analysing high-dimensional datasets across various domains such as medicine, ecology, and economics. Functional Data Analysis (FDA) has proven to be a robust framework for addressing these challenges, enabling the transformation of high-dimensional data into functional forms that capture intricate temporal and spatial patterns. However, despite advancements in functional classification methods and very high performance demonstrated by combining FDA and ensemble methods, a critical gap persists in the literature concerning the transparency and interpretability of black-box models, e.g. Functional Random Forests (FRF). In response to this need, this paper introduces a novel suite of explainability tools to illuminate the inner mechanisms of FRF. We propose using Functional Partial Dependence Plots (FPDPs), Functional Principal Component (FPC) Probability Heatmaps, various model-specific and model-agnostic FPCs' importance metrics, and the FPC Internal-External Importance and Explained Variance Bubble Plot. These tools collectively enhance the transparency of FRF models by providing a detailed analysis of how individual FPCs contribute to model predictions. By applying these methods to an ECG dataset, we demonstrate the effectiveness of these tools in revealing critical patterns and improving the explainability of FRF.
Read more8/23/2024

0
Augmented Functional Random Forests: Classifier Construction and Unbiased Functional Principal Components Importance through Ad-Hoc Conditional Permutations
Fabrizio Maturo, Annamaria Porreca
This paper introduces a novel supervised classification strategy that integrates functional data analysis (FDA) with tree-based methods, addressing the challenges of high-dimensional data and enhancing the classification performance of existing functional classifiers. Specifically, we propose augmented versions of functional classification trees and functional random forests, incorporating a new tool for assessing the importance of functional principal components. This tool provides an ad-hoc method for determining unbiased permutation feature importance in functional data, particularly when dealing with correlated features derived from successive derivatives. Our study demonstrates that these additional features can significantly enhance the predictive power of functional classifiers. Experimental evaluations on both real-world and simulated datasets showcase the effectiveness of the proposed methodology, yielding promising results compared to existing methods.
Read more8/26/2024
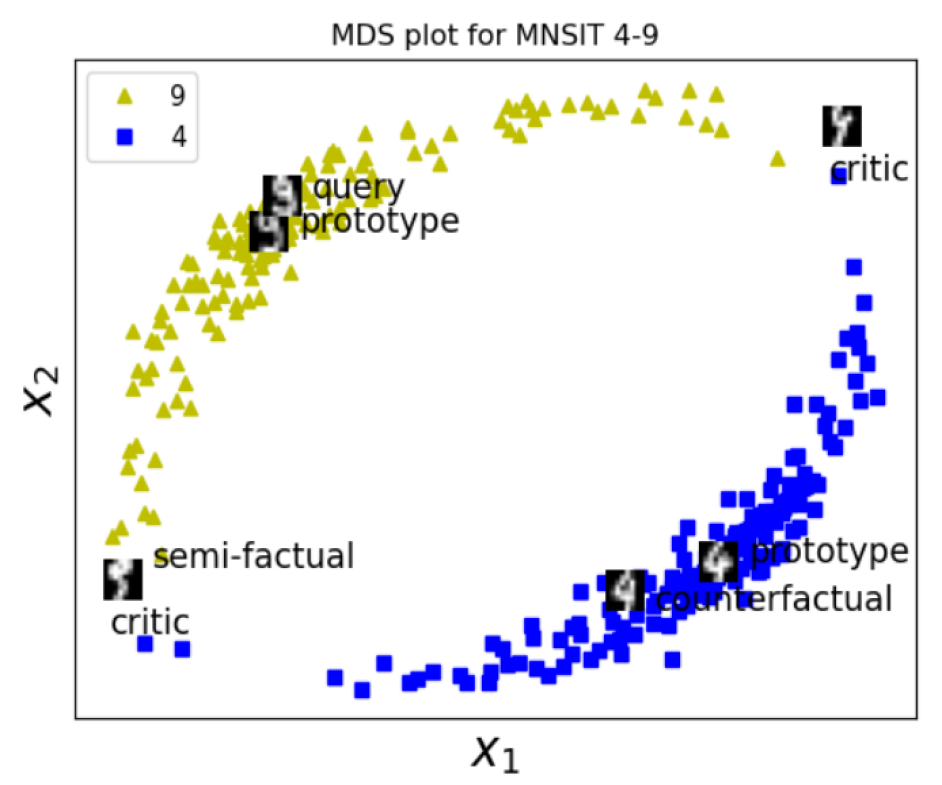
0
Case-based Explainability for Random Forest: Prototypes, Critics, Counter-factuals and Semi-factuals
Gregory Yampolsky, Dhruv Desai, Mingshu Li, Stefano Pasquali, Dhagash Mehta
The explainability of black-box machine learning algorithms, commonly known as Explainable Artificial Intelligence (XAI), has become crucial for financial and other regulated industrial applications due to regulatory requirements and the need for transparency in business practices. Among the various paradigms of XAI, Explainable Case-Based Reasoning (XCBR) stands out as a pragmatic approach that elucidates the output of a model by referencing actual examples from the data used to train or test the model. Despite its potential, XCBR has been relatively underexplored for many algorithms such as tree-based models until recently. We start by observing that most XCBR methods are defined based on the distance metric learned by the algorithm. By utilizing a recently proposed technique to extract the distance metric learned by Random Forests (RFs), which is both geometry- and accuracy-preserving, we investigate various XCBR methods. These methods amount to identify special points from the training datasets, such as prototypes, critics, counter-factuals, and semi-factuals, to explain the predictions for a given query of the RF. We evaluate these special points using various evaluation metrics to assess their explanatory power and effectiveness.
Read more8/14/2024

0
New!Enriched Functional Tree-Based Classifiers: A Novel Approach Leveraging Derivatives and Geometric Features
Fabrizio Maturo, Annamaria Porreca
The positioning of this research falls within the scalar-on-function classification literature, a field of significant interest across various domains, particularly in statistics, mathematics, and computer science. This study introduces an advanced methodology for supervised classification by integrating Functional Data Analysis (FDA) with tree-based ensemble techniques for classifying high-dimensional time series. The proposed framework, Enriched Functional Tree-Based Classifiers (EFTCs), leverages derivative and geometric features, benefiting from the diversity inherent in ensemble methods to further enhance predictive performance and reduce variance. While our approach has been tested on the enrichment of Functional Classification Trees (FCTs), Functional K-NN (FKNN), Functional Random Forest (FRF), Functional XGBoost (FXGB), and Functional LightGBM (FLGBM), it could be extended to other tree-based and non-tree-based classifiers, with appropriate considerations emerging from this investigation. Through extensive experimental evaluations on seven real-world datasets and six simulated scenarios, this proposal demonstrates fascinating improvements over traditional approaches, providing new insights into the application of FDA in complex, high-dimensional learning problems.
Read more9/27/2024