A survey and taxonomy of methods interpreting random forest models

0
❗
Sign in to get full access
Overview
- Random Forest (RF) models are widely used in machine learning due to their predictive power, flexibility, and ease of use.
- However, RF models are often considered "black boxes" because their inner workings are difficult to interpret and understand.
- This paper provides an extensive review of methods used to interpret RF models, aiming to help users choose the most appropriate tools for their needs.
Plain English Explanation
Random Forest (RF) models are a type of machine learning algorithm that are known for their strong predictive performance, flexibility, and ease of use. These models work by creating an ensemble of decision trees, each of which makes its own predictions. When combined, these trees can make very accurate predictions.
The issue with RF models is that they can be difficult to interpret. Because they use many deep decision trees, it's hard to see the complete process that leads to the final predictions. This "black box" nature of RF models can limit their acceptance and implementation in certain fields.
To address this, researchers have developed various techniques to help interpret RF models. This paper reviews and analyzes these different interpretation methods, classifying them based on different criteria. While the review is not exhaustive, it provides a helpful taxonomy of interpretation techniques that can guide users in choosing the best tools for their needs.
The paper aims to make RF models more accessible and understandable, which could lead to wider adoption of these powerful machine learning tools. By shedding light on the inner workings of RF models, the research in this paper could also be valuable for interpreting other types of "black box" machine learning models.
Technical Explanation
The paper begins by acknowledging the growing interest in the interpretability of Random Forest (RF) models within the machine learning community. RF is considered a powerful learning ensemble due to its predictive performance, flexibility, and ease of use. The authors note that the inner workings of the RF model are relatively understandable, as it uses an intuitive and intelligible approach to build the decision tree ensemble.
However, the resulting RF model is still regarded as a "black box" due to the complexity of its numerous deep decision trees. Gaining visibility over the entire process that leads to the final decisions by exploring each decision tree is a complicated, if not impossible, task. This complexity limits the acceptance and implementation of RF models in various fields of application.
To address this, the paper aims to provide an extensive review of methods used in the literature to interpret RF resulting models. The authors have analyzed these methods and classified them based on different axes, such as the level of interpretability provided (global vs. local), the type of interpretation (e.g., feature importance, rule extraction), and the specific techniques employed (e.g., Integrating White- and Black-Box Techniques for Interpretable Machine Learning, VisRuler: Visual Analytics for Extracting Decision Rules from Tree Ensembles, Through the Thicket: Study of Number-Oriented LLMs Derived Qualitative Insights, Feature Graphs for Interpretable Unsupervised Tree Ensembles: Centrality, Data Selection as a General Principle for Building Small, Interpretable Models).
Although the review is not exhaustive, it provides a taxonomy of various techniques that should guide users in choosing the most appropriate tools for interpreting RF models, depending on the interpretability aspects sought. The paper also aims to be valuable for researchers who wish to focus their work on the interpretability of RF or machine learning black boxes in general.
Critical Analysis
The paper provides a comprehensive review of the methods used to interpret Random Forest (RF) models, which is a valuable contribution to the field of machine learning. By classifying the different interpretation techniques based on various criteria, the authors have created a useful taxonomy that can guide users in selecting the most appropriate tools for their needs.
One potential limitation of the paper is that the review is not exhaustive, as the authors acknowledge. While the taxonomy covers a wide range of interpretation methods, there may be additional techniques or approaches that are not included in the analysis. However, the authors have provided a solid foundation for further research in this area.
Additionally, the paper does not delve into the specific implementation details or performance comparisons of the different interpretation methods. While this may be beyond the scope of the review, providing more information on the practical aspects of these techniques could be helpful for users looking to apply them in their own work.
Overall, the paper is a well-executed and informative review that addresses an important issue in the field of machine learning. The insights and taxonomy presented in the paper can serve as a valuable resource for both users and researchers interested in improving the interpretability of RF and other "black box" models.
Conclusion
This paper provides an extensive review of methods used to interpret Random Forest (RF) models, a widely used machine learning algorithm that is often considered a "black box" due to the complexity of its decision tree ensemble.
The review analyzes and classifies various interpretation techniques based on different criteria, such as the level of interpretability, the type of interpretation, and the specific methods employed. While the review is not exhaustive, it offers a helpful taxonomy that can guide users in choosing the most appropriate tools for interpreting RF models, depending on their specific needs and interpretability aspects.
By shedding light on the inner workings of RF models, this research can contribute to the wider acceptance and implementation of these powerful machine learning tools. The insights and methods presented in the paper can also be valuable for interpreting other types of "black box" models, furthering the progress of interpretable and transparent machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
0
A survey and taxonomy of methods interpreting random forest models
Maissae Haddouchi, Abdelaziz Berrado
The interpretability of random forest (RF) models is a research topic of growing interest in the machine learning (ML) community. In the state of the art, RF is considered a powerful learning ensemble given its predictive performance, flexibility, and ease of use. Furthermore, the inner process of the RF model is understandable because it uses an intuitive and intelligible approach for building the RF decision tree ensemble. However, the RF resulting model is regarded as a black box because of its numerous deep decision trees. Gaining visibility over the entire process that induces the final decisions by exploring each decision tree is complicated, if not impossible. This complexity limits the acceptance and implementation of RF models in several fields of application. Several papers have tackled the interpretation of RF models. This paper aims to provide an extensive review of methods used in the literature to interpret RF resulting models. We have analyzed these methods and classified them based on different axes. Although this review is not exhaustive, it provides a taxonomy of various techniques that should guide users in choosing the most appropriate tools for interpreting RF models, depending on the interpretability aspects sought. It should also be valuable for researchers who aim to focus their work on the interpretability of RF or ML black boxes in general.
Read more7/18/2024

0
Integrating White and Black Box Techniques for Interpretable Machine Learning
Eric M. Vernon, Naoki Masuyama, Yusuke Nojima
In machine learning algorithm design, there exists a trade-off between the interpretability and performance of the algorithm. In general, algorithms which are simpler and easier for humans to comprehend tend to show worse performance than more complex, less transparent algorithms. For example, a random forest classifier is likely to be more accurate than a simple decision tree, but at the expense of interpretability. In this paper, we present an ensemble classifier design which classifies easier inputs using a highly-interpretable classifier (i.e., white box model), and more difficult inputs using a more powerful, but less interpretable classifier (i.e., black box model).
Read more7/15/2024
➖
0
Subgroup Analysis via Model-based Rule Forest
I-Ling Cheng, Chan Hsu, Chantung Ku, Pei-Ju Lee, Yihuang Kang
Machine learning models are often criticized for their black-box nature, raising concerns about their applicability in critical decision-making scenarios. Consequently, there is a growing demand for interpretable models in such contexts. In this study, we introduce Model-based Deep Rule Forests (mobDRF), an interpretable representation learning algorithm designed to extract transparent models from data. By leveraging IF-THEN rules with multi-level logic expressions, mobDRF enhances the interpretability of existing models without compromising accuracy. We apply mobDRF to identify key risk factors for cognitive decline in an elderly population, demonstrating its effectiveness in subgroup analysis and local model optimization. Our method offers a promising solution for developing trustworthy and interpretable machine learning models, particularly valuable in fields like healthcare, where understanding differential effects across patient subgroups can lead to more personalized and effective treatments.
Read more8/28/2024
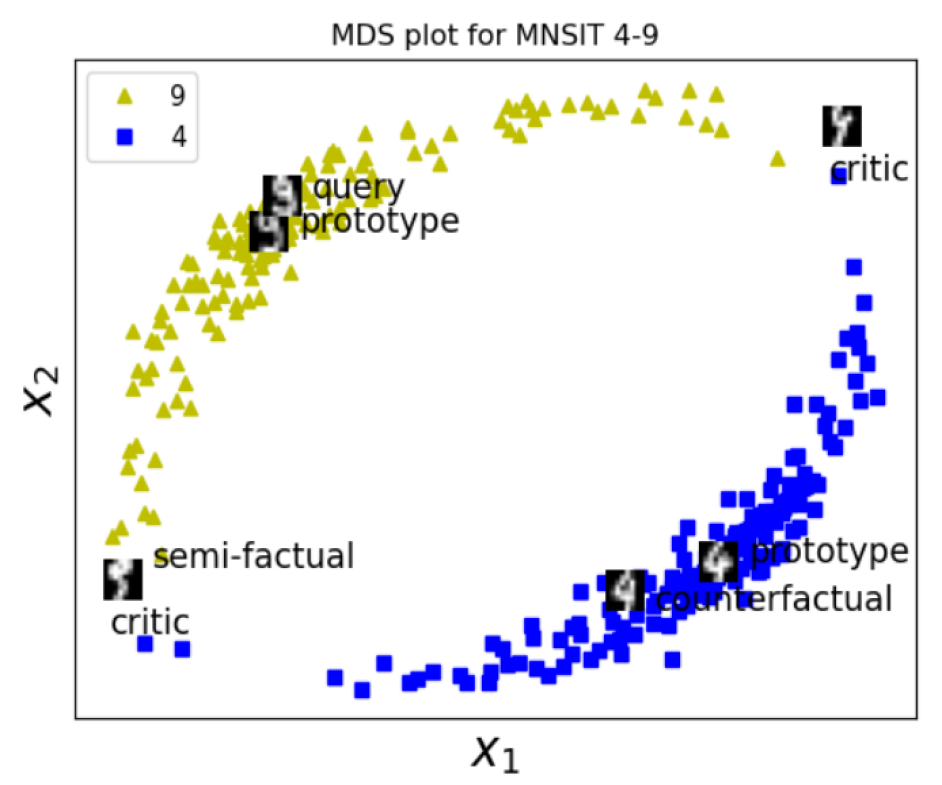
0
Case-based Explainability for Random Forest: Prototypes, Critics, Counter-factuals and Semi-factuals
Gregory Yampolsky, Dhruv Desai, Mingshu Li, Stefano Pasquali, Dhagash Mehta
The explainability of black-box machine learning algorithms, commonly known as Explainable Artificial Intelligence (XAI), has become crucial for financial and other regulated industrial applications due to regulatory requirements and the need for transparency in business practices. Among the various paradigms of XAI, Explainable Case-Based Reasoning (XCBR) stands out as a pragmatic approach that elucidates the output of a model by referencing actual examples from the data used to train or test the model. Despite its potential, XCBR has been relatively underexplored for many algorithms such as tree-based models until recently. We start by observing that most XCBR methods are defined based on the distance metric learned by the algorithm. By utilizing a recently proposed technique to extract the distance metric learned by Random Forests (RFs), which is both geometry- and accuracy-preserving, we investigate various XCBR methods. These methods amount to identify special points from the training datasets, such as prototypes, critics, counter-factuals, and semi-factuals, to explain the predictions for a given query of the RF. We evaluate these special points using various evaluation metrics to assess their explanatory power and effectiveness.
Read more8/14/2024