Demystifying Object-based Big Data Storage Systems

0

Sign in to get full access
Overview
- This paper explores the design and implementation of object-based big data storage systems, which are a type of distributed storage system used to manage large volumes of unstructured data.
- The authors provide a comprehensive overview of the key concepts, architecture, and design principles underlying these systems, as well as the advantages and challenges they present.
- The paper is intended to serve as a guide for researchers and practitioners working in the field of big data management and distributed storage systems.
Plain English Explanation
Object-based big data storage systems are a way of storing and managing large amounts of data that don't fit neatly into traditional database tables or files. Instead, the data is broken down into small, self-contained "objects" that can be easily distributed across many different computer systems.
This approach has several advantages over more traditional data storage methods. For example, object-based systems can scale up to handle massive amounts of data without getting bogged down, and they're designed to be highly available and fault-tolerant, so the data is less likely to be lost or become inaccessible.
However, these systems also come with their own set of challenges. Figuring out how to efficiently store, retrieve, and manage all of those tiny data objects can be complex, and the distributed nature of the systems means that there are tricky coordination and consistency issues to deal with as well.
The paper provides a detailed look at how these object-based big data storage systems work under the hood, explaining the key architectural components and design principles that underpin them. It also covers some of the real-world use cases and applications where these systems are being used, as well as the ongoing research and development efforts aimed at making them even more powerful and practical.
Technical Explanation
The paper begins by providing some background knowledge on the challenges of managing big data and the limitations of traditional storage approaches. It then introduces the concept of object-based storage, which organizes data into discrete, self-contained units called "objects" that can be distributed across a network of storage nodes.
The authors describe the typical architecture of an object-based storage system, including the roles of the object storage devices (OSDs), metadata servers, and client interfaces. They also discuss the key design principles behind these systems, such as scalability, fault tolerance, and consistency.
To illustrate the concepts, the paper includes several case studies of real-world object-based storage systems, including the Google File System, Ceph, and Swift. These examples highlight how the technology is being applied to tackle challenging big data workloads in areas like web services, scientific computing, and machine learning.
Critical Analysis
The paper provides a thorough and well-researched overview of object-based big data storage systems, but it does acknowledge some of the key limitations and challenges associated with this approach. For example, the authors note that the distributed and decentralized nature of these systems can make it difficult to ensure data consistency and coherence, particularly in the face of failures or network partitions.
Additionally, the paper identifies scalability as a critical concern, as the need to manage and coordinate large numbers of individual storage objects can become a performance bottleneck. The authors suggest that ongoing research into areas like object metadata management and object placement algorithms will be crucial for addressing these challenges.
One potential area for further exploration highlighted in the paper is the intersection of object-based storage with emerging technologies like serverless computing and edge/fog computing. As data-intensive workloads become more distributed and ephemeral, the ability to efficiently manage and access data objects across a wide range of cloud and edge resources may become increasingly important.
Overall, the paper provides a comprehensive and insightful look at the current state of object-based big data storage, while also identifying some of the key technical and operational hurdles that researchers and practitioners will need to overcome in the years to come.
Conclusion
This paper offers a detailed and accessible overview of the design and implementation of object-based big data storage systems. It covers the key architectural components, design principles, and real-world use cases for this emerging technology, providing a valuable resource for researchers and practitioners working in the field of distributed data management.
While object-based storage systems offer significant advantages in terms of scalability, fault tolerance, and flexibility, the authors also acknowledge the challenges associated with ensuring data consistency and efficient object metadata management at scale. Ongoing research and development in areas like serverless and edge computing may help to further expand the capabilities and applications of these powerful distributed storage systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Demystifying Object-based Big Data Storage Systems
Anindita Sarkar Mondal, Madhupa Sanyal, Ari Kusumastuti, Hrishav Bakul Barua, Kartick Chandra Mondal
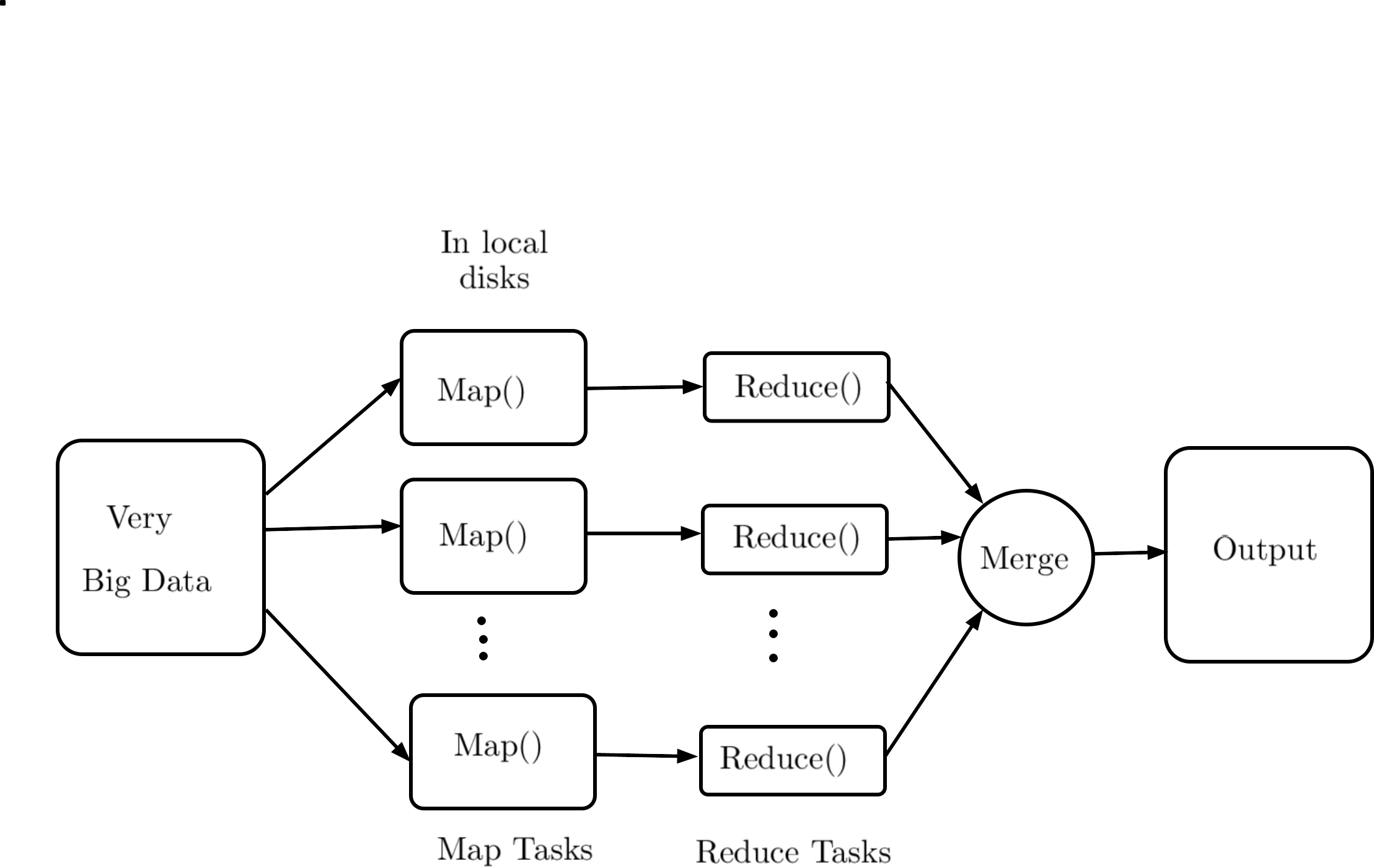
Today's era is the digitized era. Managing such generated big data is an important factor for data scientists. Day by day, it increases the demand for big data storage systems. Different organizations are involved in providing storage-related services. They follow the different architectures or storage models for storing big data. In this survey paper, our target is to highlight such storage architectures which provided by different renowned storage service providers. On an architectural basis, we divide the big data storage systems into five parts, Distributed file systems (DFS), Clustered File Systems (CFS), Cloud Storage, Archive Storage, and Object Storage Systems (OSS). Also, we reveal a detailed architectural view of the big data storage systems provided by the different organizations under these parts.
Read more6/4/2024
0
Analysis of Distributed Algorithms for Big-data
Rajendra Purohit, K R Chowdhary, S D Purohit
The parallel and distributed processing are becoming de facto industry standard, and a large part of the current research is targeted on how to make computing scalable and distributed, dynamically, without allocating the resources on permanent basis. The present article focuses on the study and performance of distributed and parallel algorithms their file systems, to achieve scalability at local level (OpenMP platform), and at global level where computing and file systems are distributed. Various applications, algorithms,file systems have been used to demonstrate the areas, and their performance studies have been presented. The systems and applications chosen here are of open-source nature, due to their wider applicability.
Read more4/10/2024
0
Efficient Distributed Data Structures for Future Many-core Architectures
Panagiota Fatourou, Nikolaos D. Kallimanis, Eleni Kanellou, Odysseas Makridakis, Christi Symeonidou
We study general techniques for implementing distributed data structures on top of future many-core architectures with non cache-coherent or partially cache-coherent memory. With the goal of contributing towards what might become, in the future, the concurrency utilities package in Java collections for such architectures, we end up with a comprehensive collection of data structures by considering different variants of these techniques. To achieve scalability, we study a generic scheme which makes all our implementations hierarchical. We consider a collection of known techniques for improving the scalability of concurrent data structures and we adjust them to work in our setting. We have performed experiments which illustrate that some of these techniques have indeed high impact on achieving scalability. Our experiments also reveal the performance and scalability power of the hierarchical approach. We finally present experiments to study energy consumption aspects of the proposed techniques by using an energy model recently proposed for such architectures.
Read more4/9/2024
📊
0
Application of cloud computing platform in industrial big data processing
Ziyan Yao
With the rapid growth and increasing complexity of industrial big data, traditional data processing methods are facing many challenges. This article takes an in-depth look at the application of cloud computing technology in industrial big data processing and explores its potential impact on improving data processing efficiency, security, and cost-effectiveness. The article first reviews the basic principles and key characteristics of cloud computing technology, and then analyzes the characteristics and processing requirements of industrial big data. In particular, this study focuses on the application of cloud computing in real-time data processing, predictive maintenance, and optimization, and demonstrates its practical effects through case studies. At the same time, this article also discusses the main challenges encountered during the implementation process, such as data security, privacy protection, performance and scalability issues, and proposes corresponding solution strategies. Finally, this article looks forward to the future trends of the integration of cloud computing and industrial big data, as well as the application prospects of emerging technologies such as artificial intelligence and machine learning in this field. The results of this study not only provide practical guidance for cloud computing applications in the industry, but also provide a basis for further research in academia.
Read more7/16/2024