Demystifying SGD with Doubly Stochastic Gradients

0
📶
Sign in to get full access
Overview
- Optimization problems with intractable expectations, such as those found in diffusion models, variational autoencoders, and many other machine learning models, are becoming increasingly important.
- A popular strategy for addressing these problems is to use stochastic gradient descent (SGD) with "doubly stochastic gradients" (doubly SGD), which estimates the expectations using gradient estimators and the sum using subsampling.
- Despite the widespread use of doubly SGD, its convergence properties were not well understood, especially under more general conditions such as dependent gradient estimators.
Plain English Explanation
Many machine learning models, like diffusion models and variational autoencoders, have optimization objectives that are difficult to calculate exactly. Instead, these objectives are expressed as a sum of many smaller, hard-to-compute parts.
To train these models, researchers often use a technique called "stochastic gradient descent with doubly stochastic gradients" (or "doubly SGD" for short). Doubly SGD works by first estimating the individual, hard-to-compute parts using a technique called a "gradient estimator." Then, it estimates the overall sum by randomly selecting and averaging a few of these gradient estimators.
Despite the popularity of doubly SGD, scientists didn't fully understand how it behaves, especially when the gradient estimators are dependent on each other (which is often the case in real-world models). This paper aims to provide a better understanding of how doubly SGD converges under more general conditions.
Technical Explanation
The paper establishes the convergence of doubly SGD with independent minibatching and random reshuffling, even when the component gradient estimators are dependent. This extends previous analyses that relied on stronger assumptions, such as bounded variance of the gradient estimators.
The key insights from the analysis are:
-
For a fixed computational budget (i.e., a certain number of gradient evaluations per iteration), the analysis suggests how to best allocate the budget between the minibatch size and the number of Monte Carlo samples used to estimate the gradients. This can lead to more efficient implementations of doubly SGD.
-
The paper proves that random reshuffling (RR) of the data can improve the complexity dependence on the subsampling noise, compared to using independent minibatches. This suggests that RR may be a valuable technique for improving the performance of doubly SGD.
The analysis encompasses a broad class of problems where the optimization objective is expressed as a sum of intractable expectations, including diffusion models, variational autoencoders, and many others.
Critical Analysis
The paper provides a rigorous theoretical analysis of doubly SGD under more general conditions than previous work. However, the analysis still relies on some assumptions, such as the gradients having a certain degree of smoothness and the gradient estimators having bounded higher-order moments.
Additionally, the paper does not explore the practical implications of the analysis in depth. While the insights about budget allocation and the benefits of random reshuffling are valuable, the paper does not include detailed experiments or comparisons to other optimization methods for these types of problems.
It would be interesting to see future work that bridges the gap between the theoretical analysis and practical performance, perhaps by applying the insights to specific machine learning models and comparing the empirical results to the theoretical predictions.
Conclusion
This paper advances the understanding of the convergence properties of doubly SGD, a popular optimization technique for machine learning models with intractable expectations in their objective functions. By providing a comprehensive analysis under more general conditions, the paper offers insights that can help researchers and practitioners design more efficient and effective optimization algorithms for these types of problems.
The theoretical guarantees and practical recommendations from this work have the potential to contribute to the continued development and improvement of advanced machine learning models, with applications in areas like generative modeling, unsupervised learning, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Demystifying SGD with Doubly Stochastic Gradients
Kyurae Kim, Joohwan Ko, Yi-An Ma, Jacob R. Gardner
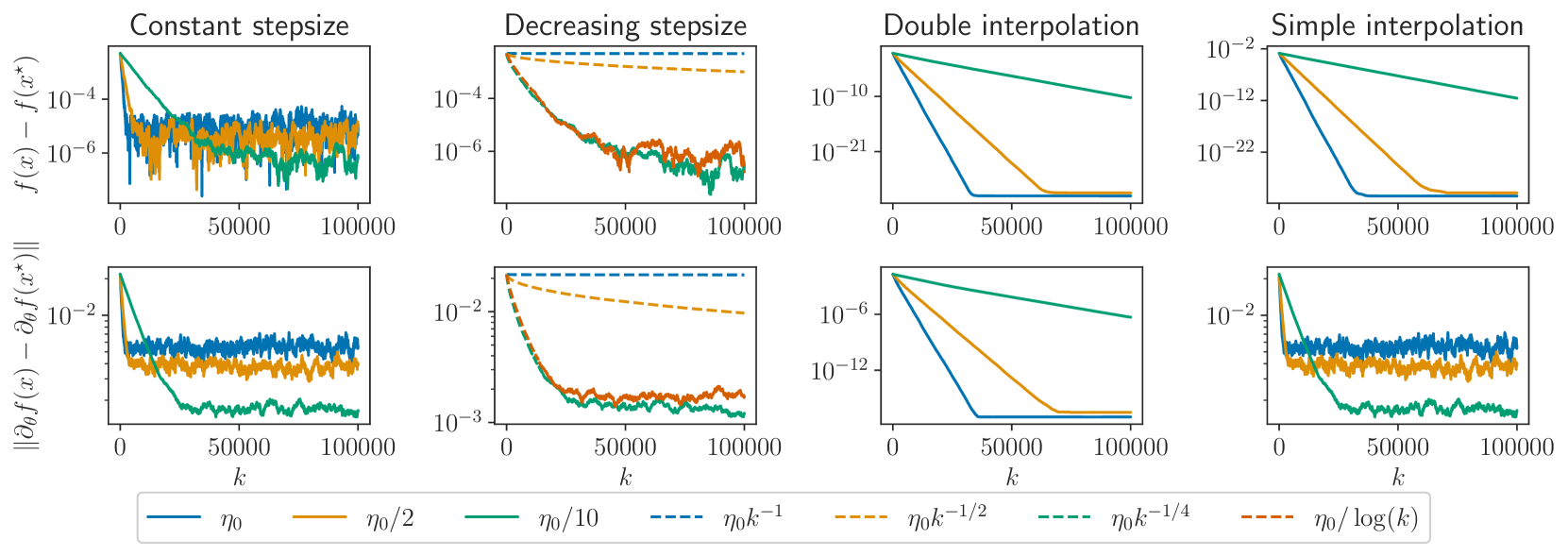
Optimization objectives in the form of a sum of intractable expectations are rising in importance (e.g., diffusion models, variational autoencoders, and many more), a setting also known as finite sum with infinite data. For these problems, a popular strategy is to employ SGD with doubly stochastic gradients (doubly SGD): the expectations are estimated using the gradient estimator of each component, while the sum is estimated by subsampling over these estimators. Despite its popularity, little is known about the convergence properties of doubly SGD, except under strong assumptions such as bounded variance. In this work, we establish the convergence of doubly SGD with independent minibatching and random reshuffling under general conditions, which encompasses dependent component gradient estimators. In particular, for dependent estimators, our analysis allows fined-grained analysis of the effect correlations. As a result, under a per-iteration computational budget of $b times m$, where $b$ is the minibatch size and $m$ is the number of Monte Carlo samples, our analysis suggests where one should invest most of the budget in general. Furthermore, we prove that random reshuffling (RR) improves the complexity dependence on the subsampling noise.
Read more6/4/2024
0
Derivatives of Stochastic Gradient Descent
Franck Iutzeler, Edouard Pauwels, Samuel Vaiter
We consider stochastic optimization problems where the objective depends on some parameter, as commonly found in hyperparameter optimization for instance. We investigate the behavior of the derivatives of the iterates of Stochastic Gradient Descent (SGD) with respect to that parameter and show that they are driven by an inexact SGD recursion on a different objective function, perturbed by the convergence of the original SGD. This enables us to establish that the derivatives of SGD converge to the derivative of the solution mapping in terms of mean squared error whenever the objective is strongly convex. Specifically, we demonstrate that with constant step-sizes, these derivatives stabilize within a noise ball centered at the solution derivative, and that with vanishing step-sizes they exhibit $O(log(k)^2 / k)$ convergence rates. Additionally, we prove exponential convergence in the interpolation regime. Our theoretical findings are illustrated by numerical experiments on synthetic tasks.
Read more5/28/2024

0
The Sample Complexity of Gradient Descent in Stochastic Convex Optimization
Roi Livni
We analyze the sample complexity of full-batch Gradient Descent (GD) in the setup of non-smooth Stochastic Convex Optimization. We show that the generalization error of GD, with common choice of hyper-parameters, can be $tilde Theta(d/m + 1/sqrt{m})$, where $d$ is the dimension and $m$ is the sample size. This matches the sample complexity of emph{worst-case} empirical risk minimizers. That means that, in contrast with other algorithms, GD has no advantage over naive ERMs. Our bound follows from a new generalization bound that depends on both the dimension as well as the learning rate and number of iterations. Our bound also shows that, for general hyper-parameters, when the dimension is strictly larger than number of samples, $T=Omega(1/epsilon^4)$ iterations are necessary to avoid overfitting. This resolves an open problem by Schlisserman et al.23 and Amir er Al.21, and improves over previous lower bounds that demonstrated that the sample size must be at least square root of the dimension.
Read more4/12/2024
🎲
0
Convergence Rates for Stochastic Approximation: Biased Noise with Unbounded Variance, and Applications
Rajeeva L. Karandikar, M. Vidyasagar
In this paper, we study the convergence properties of the Stochastic Gradient Descent (SGD) method for finding a stationary point of a given objective function $J(cdot)$. The objective function is not required to be convex. Rather, our results apply to a class of ``invex'' functions, which have the property that every stationary point is also a global minimizer. First, it is assumed that $J(cdot)$ satisfies a property that is slightly weaker than the Kurdyka-Lojasiewicz (KL) condition, denoted here as (KL'). It is shown that the iterations $J({boldsymbol theta}_t)$ converge almost surely to the global minimum of $J(cdot)$. Next, the hypothesis on $J(cdot)$ is strengthened from (KL') to the Polyak-Lojasiewicz (PL) condition. With this stronger hypothesis, we derive estimates on the rate of convergence of $J({boldsymbol theta}_t)$ to its limit. Using these results, we show that for functions satisfying the PL property, the convergence rate of SGD is the same as the best-possible rate for convex functions. While some results along these lines have been published in the past, our contributions contain two distinct improvements. First, the assumptions on the stochastic gradient are more general than elsewhere, and second, our convergence is almost sure, and not in expectation. We also study SGD when only function evaluations are permitted. In this setting, we determine the ``optimal'' increments or the size of the perturbations. Using the same set of ideas, we establish the global convergence of the Stochastic Approximation (SA) algorithm under more general assumptions on the measurement error, compared to the existing literature. We also derive bounds on the rate of convergence of the SA algorithm under appropriate assumptions.
Read more5/14/2024