Gradient Estimation and Variance Reduction in Stochastic and Deterministic Models
2405.08661
0
0
➖
Abstract
It seems that in the current age, computers, computation, and data have an increasingly important role to play in scientific research and discovery. This is reflected in part by the rise of machine learning and artificial intelligence, which have become great areas of interest not just for computer science but also for many other fields of study. More generally, there have been trends moving towards the use of bigger, more complex and higher capacity models. It also seems that stochastic models, and stochastic variants of existing deterministic models, have become important research directions in various fields. For all of these types of models, gradient-based optimization remains as the dominant paradigm for model fitting, control, and more. This dissertation considers unconstrained, nonlinear optimization problems, with a focus on the gradient itself, that key quantity which enables the solution of such problems. In chapter 1, we introduce the notion of reverse differentiation, a term which describes the body of techniques which enables the efficient computation of gradients. We cover relevant techniques both in the deterministic and stochastic cases. We present a new framework for calculating the gradient of problems which involve both deterministic and stochastic elements. In chapter 2, we analyze the properties of the gradient estimator, with a focus on those properties which are typically assumed in convergence proofs of optimization algorithms. Chapter 3 gives various examples of applying our new gradient estimator. We further explore the idea of working with piecewise continuous models, that is, models with distinct branches and if statements which define what specific branch to use.
Create account to get full access
Overview
- The paper discusses the increasing importance of computers, computation, and data in scientific research and discovery.
- It highlights the rise of machine learning and artificial intelligence as areas of interest across many fields.
- The paper focuses on the use of larger, more complex, and higher capacity models, as well as the growing importance of stochastic models and their variants.
- Gradient-based optimization is presented as the dominant paradigm for model fitting, control, and more.
- The dissertation examines unconstrained, nonlinear optimization problems, with a focus on the gradient itself.
Plain English Explanation
Computers, data, and computational power have become essential tools for scientific research and discovery. This is reflected in the growing popularity of machine learning and artificial intelligence, which are now being used in a wide range of fields beyond just computer science.
One trend the paper discusses is the move towards larger, more complex, and higher-capacity models. These models are often stochastic in nature, meaning they involve random elements, rather than being purely deterministic. Stochastic models and their variants have become an important area of research in various disciplines.
Regardless of the type of model, the paper shows that gradient-based optimization remains the dominant approach for fitting models, controlling systems, and solving other optimization problems. The dissertation focuses on understanding the gradient itself, which is a key quantity that enables the solution of these optimization problems.
Technical Explanation
The paper introduces the concept of reverse differentiation, a set of techniques that allow for the efficient computation of gradients. These techniques are applicable in both deterministic and stochastic settings.
The authors present a new framework for calculating the gradient of problems that involve both deterministic and stochastic elements. In Chapter 2, they analyze the properties of this gradient estimator, focusing on the characteristics that are typically assumed in the convergence proofs of optimization algorithms.
Chapter 3 provides various examples of applying the new gradient estimator, including exploring the idea of working with piecewise continuous models, which have distinct branches and if statements that define which specific branch to use.
Critical Analysis
The paper does not delve into the potential limitations or caveats of the proposed gradient estimation framework. It would be helpful to understand the scenarios in which the framework may not perform well or the types of optimization problems where it may be less applicable.
Additionally, the paper does not discuss the computational complexity or runtime performance of the gradient estimation approach compared to other methods. This information would be useful for researchers and practitioners to evaluate the practical feasibility of implementing the proposed techniques.
Further research could explore the performance of the gradient estimator on a broader range of optimization problems, including those encountered in cyber-physical and robotic systems, to assess its broader applicability and potential limitations.
Conclusion
This dissertation examines the increasing importance of computers, computation, and data in scientific research and discovery. It highlights the rise of machine learning, artificial intelligence, and the use of larger, more complex models, including stochastic models and their variants.
The core focus of the paper is on the gradient, a key quantity that enables the solution of unconstrained, nonlinear optimization problems. The authors present a new framework for calculating gradients in problems with both deterministic and stochastic elements, and they analyze the properties of this gradient estimator.
The insights and techniques discussed in this dissertation could have far-reaching implications for a wide range of fields that rely on optimization and modeling, potentially driving further advancements in scientific research and discovery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Towards Learning Stochastic Population Models by Gradient Descent
Justin N. Kreikemeyer, Philipp Andelfinger, Adelinde M. Uhrmacher
0
0
Increasing effort is put into the development of methods for learning mechanistic models from data. This task entails not only the accurate estimation of parameters but also a suitable model structure. Recent work on the discovery of dynamical systems formulates this problem as a linear equation system. Here, we explore several simulation-based optimization approaches, which allow much greater freedom in the objective formulation and weaker conditions on the available data. We show that even for relatively small stochastic population models, simultaneous estimation of parameters and structure poses major challenges for optimization procedures. Particularly, we investigate the application of the local stochastic gradient descent method, commonly used for training machine learning models. We demonstrate accurate estimation of models but find that enforcing the inference of parsimonious, interpretable models drastically increases the difficulty. We give an outlook on how this challenge can be overcome.
7/1/2024

A Guide to Stochastic Optimisation for Large-Scale Inverse Problems
Matthias J. Ehrhardt, Zeljko Kereta, Jingwei Liang, Junqi Tang
0
0
Stochastic optimisation algorithms are the de facto standard for machine learning with large amounts of data. Handling only a subset of available data in each optimisation step dramatically reduces the per-iteration computational costs, while still ensuring significant progress towards the solution. Driven by the need to solve large-scale optimisation problems as efficiently as possible, the last decade has witnessed an explosion of research in this area. Leveraging the parallels between machine learning and inverse problems has allowed harnessing the power of this research wave for solving inverse problems. In this survey, we provide a comprehensive account of the state-of-the-art in stochastic optimisation from the viewpoint of inverse problems. We present algorithms with diverse modalities of problem randomisation and discuss the roles of variance reduction, acceleration, higher-order methods, and other algorithmic modifications, and compare theoretical results with practical behaviour. We focus on the potential and the challenges for stochastic optimisation that are unique to inverse imaging problems and are not commonly encountered in machine learning. We conclude the survey with illustrative examples from imaging problems to examine the advantages and disadvantages that this new generation of algorithms bring to the field of inverse problems.
6/11/2024
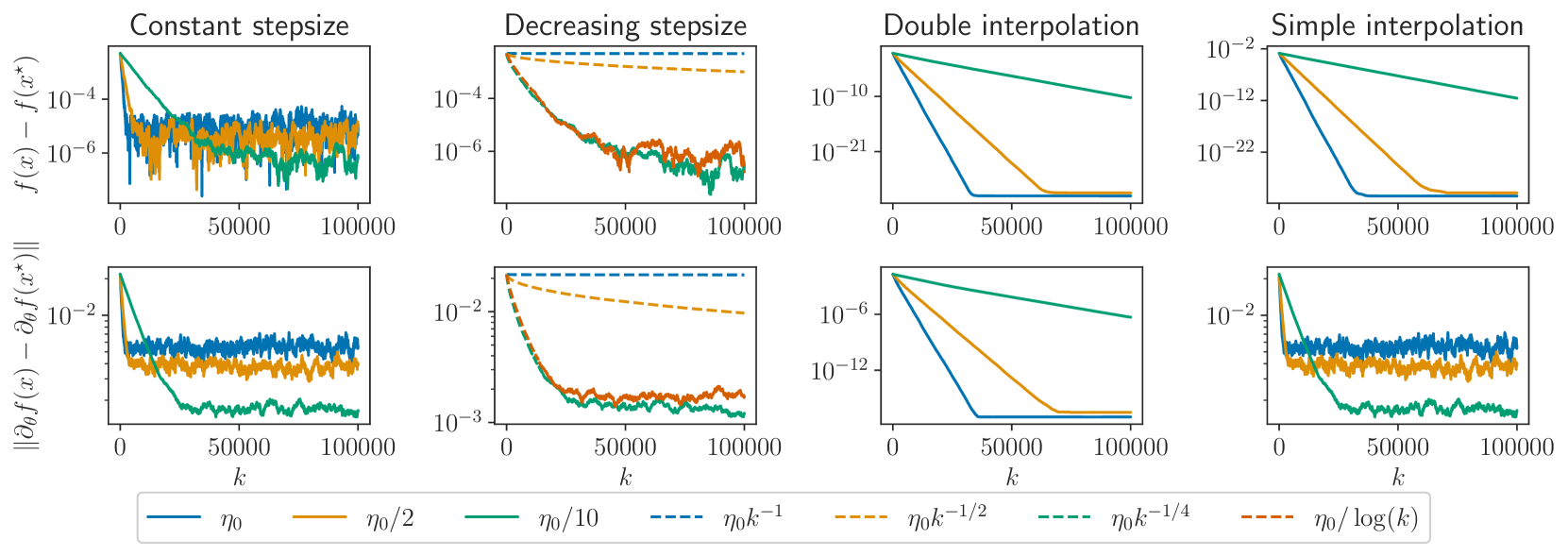
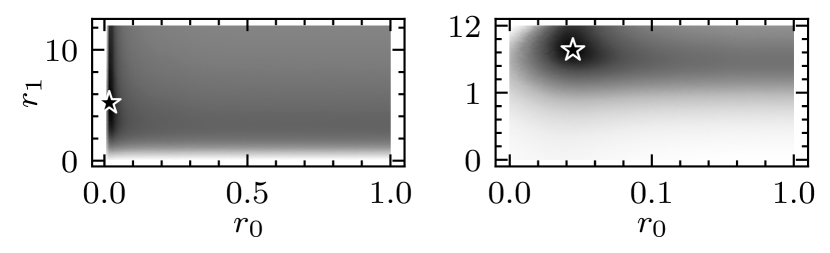
Derivatives of Stochastic Gradient Descent
Franck Iutzeler, Edouard Pauwels, Samuel Vaiter
0
0
We consider stochastic optimization problems where the objective depends on some parameter, as commonly found in hyperparameter optimization for instance. We investigate the behavior of the derivatives of the iterates of Stochastic Gradient Descent (SGD) with respect to that parameter and show that they are driven by an inexact SGD recursion on a different objective function, perturbed by the convergence of the original SGD. This enables us to establish that the derivatives of SGD converge to the derivative of the solution mapping in terms of mean squared error whenever the objective is strongly convex. Specifically, we demonstrate that with constant step-sizes, these derivatives stabilize within a noise ball centered at the solution derivative, and that with vanishing step-sizes they exhibit $O(log(k)^2 / k)$ convergence rates. Additionally, we prove exponential convergence in the interpolation regime. Our theoretical findings are illustrated by numerical experiments on synthetic tasks.
5/28/2024

Learning to optimize with convergence guarantees using nonlinear system theory
Andrea Martin, Luca Furieri
0
0
The increasing reliance on numerical methods for controlling dynamical systems and training machine learning models underscores the need to devise algorithms that dependably and efficiently navigate complex optimization landscapes. Classical gradient descent methods offer strong theoretical guarantees for convex problems; however, they demand meticulous hyperparameter tuning for non-convex ones. The emerging paradigm of learning to optimize (L2O) automates the discovery of algorithms with optimized performance leveraging learning models and data - yet, it lacks a theoretical framework to analyze convergence of the learned algorithms. In this paper, we fill this gap by harnessing nonlinear system theory. Specifically, we propose an unconstrained parametrization of all convergent algorithms for smooth non-convex objective functions. Notably, our framework is directly compatible with automatic differentiation tools, ensuring convergence by design while learning to optimize.
6/4/2024