A density ratio framework for evaluating the utility of synthetic data

0
📊
Sign in to get full access
Overview
- Synthetic data generation is a promising technique to use sensitive data while reducing privacy risks.
- For synthetic data to be useful, it needs to be high-quality.
- Existing methods for evaluating synthetic data quality are often incomplete or misleading.
- This paper proposes using density ratio estimation to improve synthetic data quality evaluation.
Plain English Explanation
Synthetic data is information that is artificially created, rather than collected from real-world sources. Generating synthetic data can be helpful when working with sensitive or private information, as it allows you to use similar data without the same privacy concerns.
However, for synthetic data to be useful in further analysis or applications, it needs to closely match the characteristics of the original data. The quality of the synthetic data is crucial. This paper explores a new way to evaluate the quality of synthetic datasets, using a technique called density ratio estimation.
Density ratio estimation allows you to compare the distribution of the synthetic data to the distribution of the original data. This gives you a clear, quantitative measure of how well the synthetic data matches the original. The authors show that this approach provides more accurate and informative quality assessments than previous methods.
By using density ratio estimation, researchers and data practitioners can better understand the strengths and limitations of their synthetic data. This can guide them in refining their data generation models to produce higher-quality synthetic data that is more faithful to the original. Ultimately, this helps unlock the benefits of synthetic data while mitigating privacy risks.
Technical Explanation
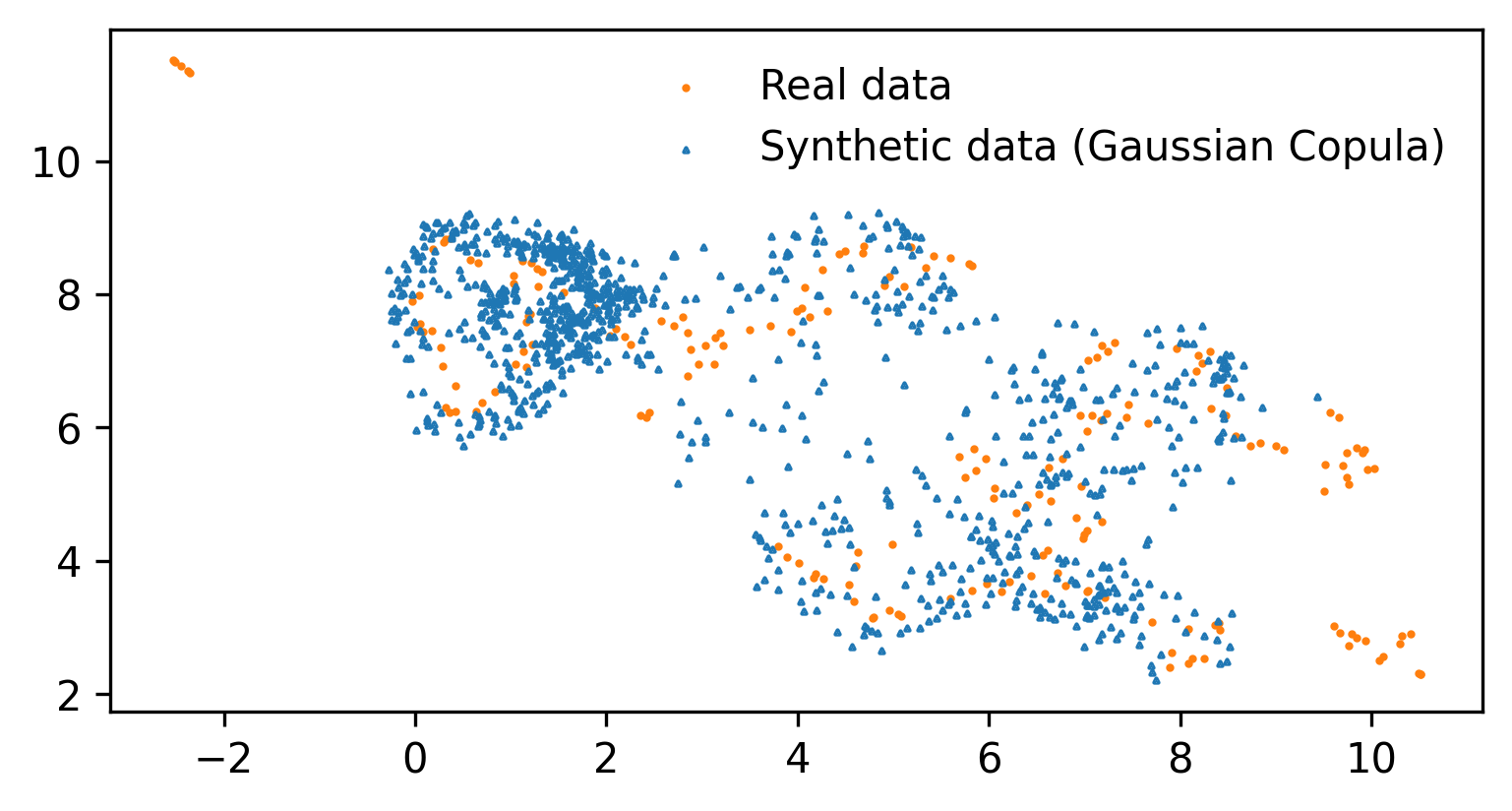
The paper proposes using density ratio estimation as a framework for evaluating the quality of synthetic data. Density ratio estimation compares the distribution of the synthetic data to the distribution of the original data, providing a global measure of how well the synthetic data matches.
The authors develop an estimator that automatically selects an appropriate non-parametric density ratio model, requiring little manual tuning. Through simulations, they demonstrate that this density ratio-based approach yields more accurate estimates of global data utility than established evaluation procedures.
The paper also shows how the density ratio framework can provide local utility measures, highlighting specific regions where the synthetic data deviates from the original. This granular feedback can guide refinements to the data synthesis models.
The authors apply their density ratio estimation approach to a real-world dataset, illustrating how it can be used to assess and improve synthetic data quality. They provide the methods in an open-source R package, making them accessible to the research community.
Critical Analysis
The paper makes a compelling case for using density ratio estimation to evaluate synthetic data quality. The proposed approach appears to offer significant advantages over existing methods, providing more accurate and informative assessments.
However, the paper does not delve into potential limitations or caveats of the density ratio estimation technique. For example, it is unclear how the method would perform on high-dimensional or complex data distributions, or how sensitive it is to the choice of non-parametric density model.
Additionally, the paper focuses on global and local utility measures derived from the density ratio, but does not explore how these metrics relate to downstream task performance. Further research may be needed to understand the connection between density ratio-based quality evaluation and the suitability of synthetic data for specific analytical tasks.
Overall, the density ratio estimation framework presented in this paper seems like a valuable addition to the toolkit for synthetic data quality assessment. However, as with any new methodology, ongoing research and real-world applications will be crucial to fully understand its strengths, limitations, and appropriate use cases.
Conclusion
This paper introduces density ratio estimation as a promising approach for evaluating the quality of synthetic data. By comparing the distribution of synthetic data to the original data, density ratio estimation provides a clear, quantitative measure of how well the synthetic data matches the real-world information.
The authors demonstrate that this framework offers more accurate and informative quality assessments than previous methods. They also show how density ratio estimation can guide refinements to data synthesis models, helping to improve the overall quality of synthetic datasets.
The potential benefits of this technique are significant, as high-quality synthetic data can unlock the use of sensitive information while mitigating privacy risks. By making their methods available in an open-source package, the authors have taken an important step towards enabling broader adoption and further development of density ratio-based synthetic data evaluation.
As researchers and practitioners continue to explore the frontiers of synthetic data generation, tools like the one presented in this paper will be invaluable in ensuring the integrity and utility of the resulting datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
A density ratio framework for evaluating the utility of synthetic data
Thom Benjamin Volker, Peter-Paul de Wolf, Erik-Jan van Kesteren
Synthetic data generation is a promising technique to facilitate the use of sensitive data while mitigating the risk of privacy breaches. However, for synthetic data to be useful in downstream analysis tasks, it needs to be of sufficient quality. Various methods have been proposed to measure the utility of synthetic data, but their results are often incomplete or even misleading. In this paper, we propose using density ratio estimation to improve quality evaluation for synthetic data, and thereby the quality of synthesized datasets. We show how this framework relates to and builds on existing measures, yielding global and local utility measures that are informative and easy to interpret. We develop an estimator which requires little to no manual tuning due to automatic selection of a nonparametric density ratio model. Through simulations, we find that density ratio estimation yields more accurate estimates of global utility than established procedures. A real-world data application demonstrates how the density ratio can guide refinements of synthesis models and can be used to improve downstream analyses. We conclude that density ratio estimation is a valuable tool in synthetic data generation workflows and provide these methods in the accessible open source R-package densityratio.
Read more8/26/2024
0
Advancing Retail Data Science: Comprehensive Evaluation of Synthetic Data
Yu Xia, Chi-Hua Wang, Joshua Mabry, Guang Cheng
The evaluation of synthetic data generation is crucial, especially in the retail sector where data accuracy is paramount. This paper introduces a comprehensive framework for assessing synthetic retail data, focusing on fidelity, utility, and privacy. Our approach differentiates between continuous and discrete data attributes, providing precise evaluation criteria. Fidelity is measured through stability and generalizability. Stability ensures synthetic data accurately replicates known data distributions, while generalizability confirms its robustness in novel scenarios. Utility is demonstrated through the synthetic data's effectiveness in critical retail tasks such as demand forecasting and dynamic pricing, proving its value in predictive analytics and strategic planning. Privacy is safeguarded using Differential Privacy, ensuring synthetic data maintains a perfect balance between resembling training and holdout datasets without compromising security. Our findings validate that this framework provides reliable and scalable evaluation for synthetic retail data. It ensures high fidelity, utility, and privacy, making it an essential tool for advancing retail data science. This framework meets the evolving needs of the retail industry with precision and confidence, paving the way for future advancements in synthetic data methodologies.
Read more6/21/2024
0
An evaluation framework for synthetic data generation models
Ioannis E. Livieris, Nikos Alimpertis, George Domalis, Dimitris Tsakalidis
Nowadays, the use of synthetic data has gained popularity as a cost-efficient strategy for enhancing data augmentation for improving machine learning models performance as well as addressing concerns related to sensitive data privacy. Therefore, the necessity of ensuring quality of generated synthetic data, in terms of accurate representation of real data, consists of primary importance. In this work, we present a new framework for evaluating synthetic data generation models' ability for developing high-quality synthetic data. The proposed approach is able to provide strong statistical and theoretical information about the evaluation framework and the compared models' ranking. Two use case scenarios demonstrate the applicability of the proposed framework for evaluating the ability of synthetic data generation models to generated high quality data. The implementation code can be found in https://github.com/novelcore/synthetic_data_evaluation_framework.
Read more4/16/2024

0
A Density Ratio Super Learner
Wencheng Wu, David Benkeser
The estimation of the ratio of two density probability functions is of great interest in many statistics fields, including causal inference. In this study, we develop an ensemble estimator of density ratios with a novel loss function based on super learning. We show that this novel loss function is qualified for building super learners. Two simulations corresponding to mediation analysis and longitudinal modified treatment policy in causal inference, where density ratios are nuisance parameters, are conducted to show our density ratio super learner's performance empirically.
Read more8/12/2024