Dependency Annotation of Ottoman Turkish with Multilingual BERT

0

Sign in to get full access
Overview
- Examines the use of multilingual BERT for dependency annotation of Ottoman Turkish, an under-resourced language.
- Develops a dataset and models for dependency parsing of Ottoman Turkish.
- Explores the challenges and opportunities of applying modern NLP techniques to historical languages.
Plain English Explanation
This research paper looks at using a popular AI language model called Multilingual BERT to analyze the grammatical structure of Ottoman Turkish, an historical language that is not as widely studied as modern languages.
The researchers created a dataset of Ottoman Turkish text and used it to train dependency parsing models - systems that can identify the relationships between the words in a sentence. This allows for a deeper understanding of the language's grammatical structure.
The key findings are that Multilingual BERT, despite being trained on a wide range of languages, can be effectively fine-tuned to handle the unique challenges of Ottoman Turkish. This demonstrates the potential for applying modern AI techniques to study historical languages that have fewer available resources. However, the researchers also highlight areas that require further research, such as handling the complex vocabulary and morphology of Ottoman Turkish.
Technical Explanation
The paper first provides background on the Ottoman Turkish language and its importance as a historical and cultural artifact. It then reviews related work on dependency parsing for other under-resourced languages.
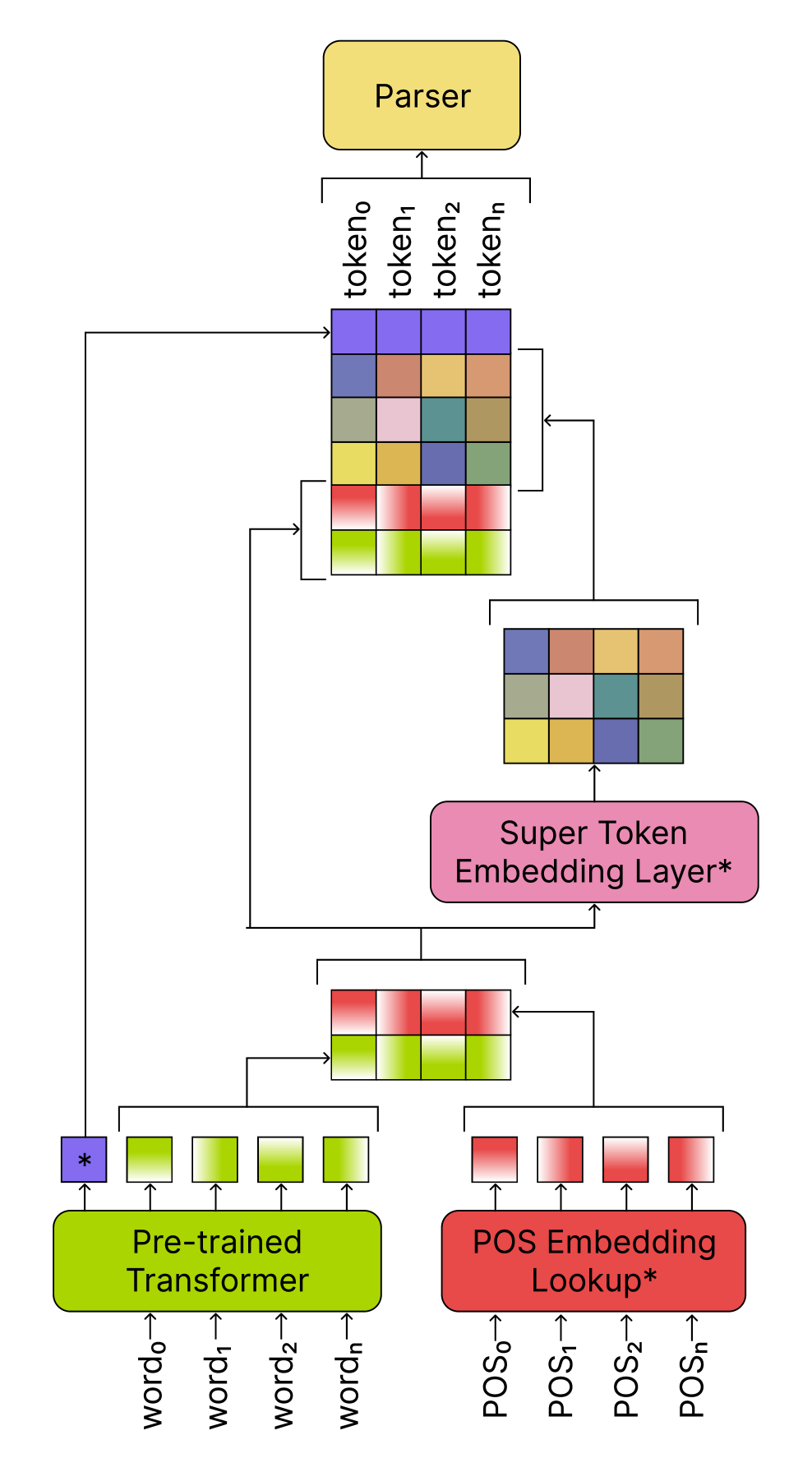
The core of the paper describes the creation of a new dataset for dependency annotation of Ottoman Turkish texts. The researchers collected a diverse corpus of Ottoman Turkish documents and manually annotated the grammatical dependencies between words. This resulted in the OttomanUD dataset, which the authors release publicly.
Using this dataset, the paper then presents experiments training Multilingual BERT models for dependency parsing of Ottoman Turkish. The models are evaluated on standard parsing metrics, and the results show that Multilingual BERT can be effectively fine-tuned to handle the unique linguistic properties of Ottoman Turkish despite its historical nature.
Critical Analysis
The researchers acknowledge several limitations and areas for further work. For example, the dataset size is relatively small, which may constrain model performance. Additionally, the complex morphology and vocabulary of Ottoman Turkish pose ongoing challenges that require more research.
While the results demonstrate the potential of Multilingual BERT, there are open questions about how well the approach would generalize to other historical languages with fewer available resources. The paper also does not deeply examine potential biases or errors in the manual annotation process.
Overall, this work provides a valuable contribution by applying modern NLP techniques to an under-studied historical language. The dataset and models released by the authors can facilitate further research in this important area.
Conclusion
This paper explores the use of Multilingual BERT for dependency annotation of Ottoman Turkish, an under-resourced historical language. The researchers developed a new dataset and demonstrated the effectiveness of fine-tuning Multilingual BERT for this task, despite the linguistic complexities involved.
The findings highlight the potential for applying advanced AI models to study historical languages, which can yield important insights into cultural heritage and linguistic evolution. However, the work also identifies areas requiring further research, such as handling complex morphology and expanding dataset size.
Overall, this paper makes a valuable contribution to the field of historical NLP by showcasing how modern techniques can be leveraged to unlock the secrets of under-studied languages like Ottoman Turkish.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dependency Annotation of Ottoman Turkish with Multilingual BERT
c{S}aziye Betul Ozatec{s}, Tar{i}k Emre T{i}rac{s}, Efe Eren Genc{c}, Esma Fat{i}ma Bilgin Tac{s}demir
This study introduces a pretrained large language model-based annotation methodology for the first de dency treebank in Ottoman Turkish. Our experimental results show that, iteratively, i) pseudo-annotating data using a multilingual BERT-based parsing model, ii) manually correcting the pseudo-annotations, and iii) fine-tuning the parsing model with the corrected annotations, we speed up and simplify the challenging dependency annotation process. The resulting treebank, that will be a part of the Universal Dependencies (UD) project, will facilitate automated analysis of Ottoman Turkish documents, unlocking the linguistic richness embedded in this historical heritage.
Read more8/23/2024
0
Thai Universal Dependency Treebank
Panyur Sriwirote, Wei Qi Leong, Charin Polpanumas, Santhawat Thanyawong, William Chandra Tjhi, Wirote Aroonmanakun, Attapol T. Rutherford
Automatic dependency parsing of Thai sentences has been underexplored, as evidenced by the lack of large Thai dependency treebanks with complete dependency structures and the lack of a published systematic evaluation of state-of-the-art models, especially transformer-based parsers. In this work, we address these problems by introducing Thai Universal Dependency Treebank (TUD), a new largest Thai treebank consisting of 3,627 trees annotated in accordance with the Universal Dependencies (UD) framework. We then benchmark dependency parsing models that incorporate pretrained transformers as encoders and train them on Thai-PUD and our TUD. The evaluation results show that most of our models can outperform other models reported in previous papers and provide insight into the optimal choices of components to include in Thai dependency parsers. The new treebank and every model's full prediction generated in our experiment are made available on a GitHub repository for further study.
Read more5/14/2024

0
A multi-level multi-label text classification dataset of 19th century Ottoman and Russian literary and critical texts
Gokcen Gokceoglu, Devrim Cavusoglu, Emre Akbas, Ozen Nergis Dolcerocca
This paper introduces a multi-level, multi-label text classification dataset comprising over 3000 documents. The dataset features literary and critical texts from 19th-century Ottoman Turkish and Russian. It is the first study to apply large language models (LLMs) to this dataset, sourced from prominent literary periodicals of the era. The texts have been meticulously organized and labeled. This was done according to a taxonomic framework that takes into account both their structural and semantic attributes. Articles are categorized and tagged with bibliometric metadata by human experts. We present baseline classification results using a classical bag-of-words (BoW) naive Bayes model and three modern LLMs: multilingual BERT, Falcon, and Llama-v2. We found that in certain cases, Bag of Words (BoW) outperforms Large Language Models (LLMs), emphasizing the need for additional research, especially in low-resource language settings. This dataset is expected to be a valuable resource for researchers in natural language processing and machine learning, especially for historical and low-resource languages. The dataset is publicly available^1.
Read more7/23/2024

0
LegalTurk Optimized BERT for Multi-Label Text Classification and NER
Farnaz Zeidi, Mehmet Fatih Amasyali, c{C}iu{g}dem Erol
The introduction of the Transformer neural network, along with techniques like self-supervised pre-training and transfer learning, has paved the way for advanced models like BERT. Despite BERT's impressive performance, opportunities for further enhancement exist. To our knowledge, most efforts are focusing on improving BERT's performance in English and in general domains, with no study specifically addressing the legal Turkish domain. Our study is primarily dedicated to enhancing the BERT model within the legal Turkish domain through modifications in the pre-training phase. In this work, we introduce our innovative modified pre-training approach by combining diverse masking strategies. In the fine-tuning task, we focus on two essential downstream tasks in the legal domain: name entity recognition and multi-label text classification. To evaluate our modified pre-training approach, we fine-tuned all customized models alongside the original BERT models to compare their performance. Our modified approach demonstrated significant improvements in both NER and multi-label text classification tasks compared to the original BERT model. Finally, to showcase the impact of our proposed models, we trained our best models with different corpus sizes and compared them with BERTurk models. The experimental results demonstrate that our innovative approach, despite being pre-trained on a smaller corpus, competes with BERTurk.
Read more7/2/2024