Thai Universal Dependency Treebank

0
Sign in to get full access
Overview
- This paper introduces the Thai Universal Dependency Treebank, a dataset for dependency parsing of Thai language text.
- The treebank contains manually annotated Thai sentences following the Universal Dependencies (UD) annotation guidelines, which provide a consistent framework for representing grammatical relations across languages.
- The authors describe the process of creating the treebank, including data collection, annotation guidelines, and quality assurance measures.
- Experiments are conducted to establish baseline performance for dependency parsing on the Thai UD treebank using state-of-the-art neural network models.
Plain English Explanation
The paper presents a new dataset called the Thai Universal Dependency Treebank, which is designed to help machines better understand the Thai language. This treebank contains a large collection of Thai sentences that have been manually labeled with information about the grammatical structure and relationships between the words.
The labeling follows a standardized system called Universal Dependencies, which aims to represent language structure in a consistent way across different languages. By creating this treebank, the researchers have provided a valuable resource for training and testing natural language processing models on Thai text.
The paper describes how the treebank was built, including how the sentences were selected and annotated by human experts. It also presents the results of experiments that used advanced neural network models to automatically parse the grammatical structure of the Thai sentences in the treebank. These baseline results provide a starting point for future research and development of Thai language understanding capabilities.
Overall, this work contributes an important dataset and benchmarks to advance the state of the art in Thai natural language processing, which has applications in areas like language translation, question answering, and text analysis.
Technical Explanation
The authors introduce the Thai Universal Dependency Treebank, a new dataset for dependency parsing of Thai language text. The treebank contains over 20,000 manually annotated Thai sentences following the Universal Dependencies (UD) annotation guidelines, which provide a consistent framework for representing grammatical relations across languages.
The paper describes the data collection and annotation process in detail. Sentences were sourced from various Thai web domains and manually annotated by linguists following UD guidelines. Quality assurance measures were employed, including inter-annotator agreement checks and validation by a team of experts.
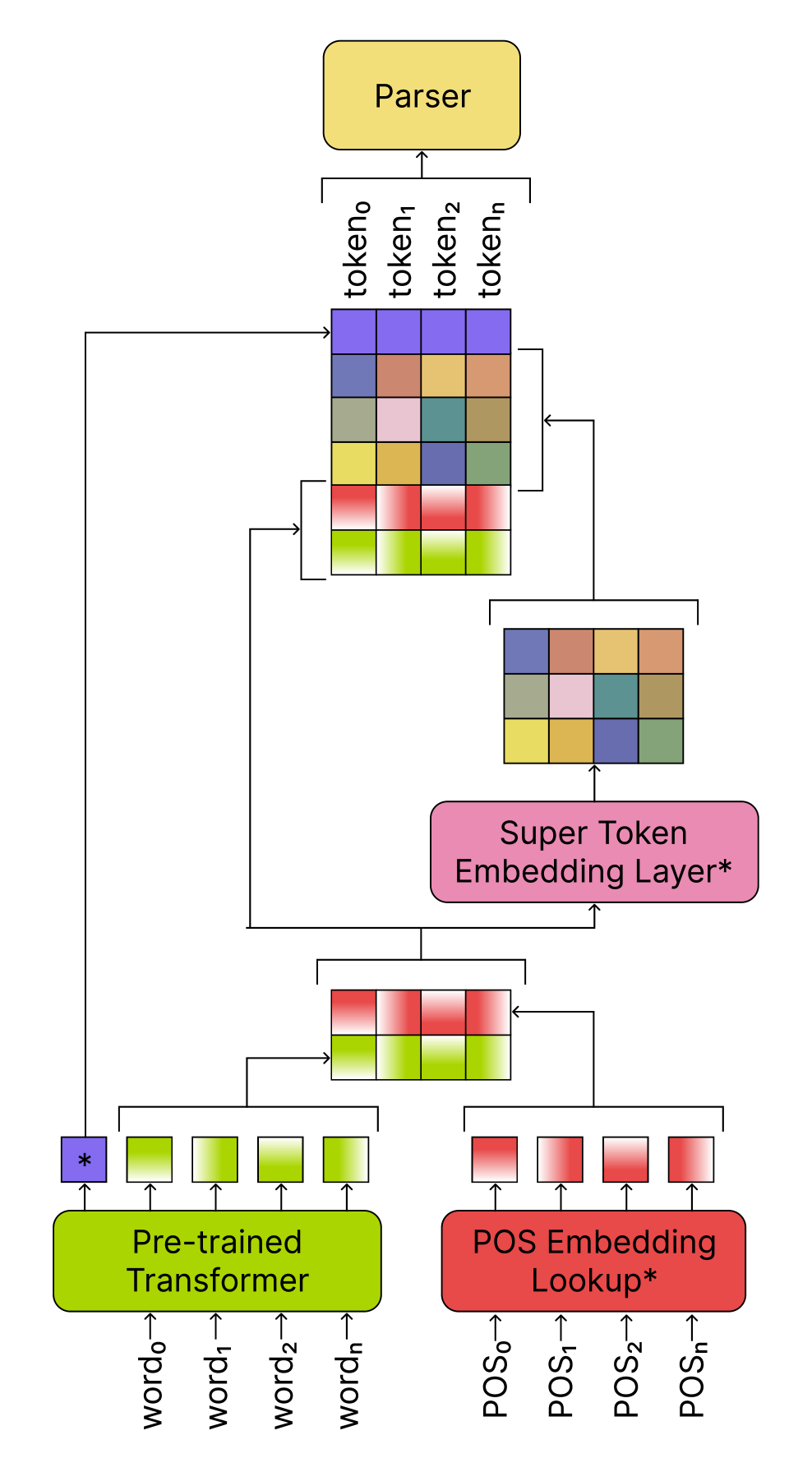
Baseline dependency parsing experiments were conducted on the Thai UD treebank using state-of-the-art neural network models, including SUTRA, a scalable multilingual language model. The results establish initial benchmarks for Thai dependency parsing performance, which can serve as a starting point for future research.
The creation of the Thai Universal Dependency Treebank represents an important contribution to the field of Thai natural language processing. This dataset enables the development and evaluation of more robust language understanding capabilities, with applications in areas like machine translation, question answering, and text analysis.
Critical Analysis
The authors have taken a rigorous approach to the creation of the Thai Universal Dependency Treebank, following established best practices for corpus development and annotation. The use of the Universal Dependencies framework ensures the treebank is aligned with international standards, facilitating cross-lingual comparisons and joint modeling efforts.
However, the paper does not provide much insight into the specific challenges encountered during the annotation process or the types of linguistic phenomena that proved most difficult to capture. Addressing these aspects could help guide future efforts to expand the treebank or apply it to more complex natural language processing tasks.
Additionally, while the baseline dependency parsing results provide a useful starting point, the paper does not explore the generalization capabilities of the models or their performance on real-world applications. Further investigation into the model's robustness, scalability, and interpretability would be valuable for understanding the practical implications of this work.
Overall, the Thai Universal Dependency Treebank represents an important step forward for Thai natural language processing research. Continued refinement and expansion of the dataset, along with more comprehensive model evaluations, could further strengthen its impact and utility for the broader community.
Conclusion
This paper introduces the Thai Universal Dependency Treebank, a valuable new resource for advancing Thai language understanding capabilities. By aligning the annotation with the Universal Dependencies framework, the treebank provides a consistent basis for developing and evaluating natural language processing models across languages.
The authors have described the rigorous process of data collection, annotation, and quality assurance, which has resulted in a high-quality dataset. Baseline dependency parsing experiments demonstrate the utility of the treebank for training and benchmarking Thai language models.
The creation of the Thai Universal Dependency Treebank represents an important contribution to the field of Thai natural language processing, with potential applications in areas like machine translation, question answering, and text analysis. Continued research and development building upon this foundation can further unlock the potential of Thai language technologies and their societal impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Thai Universal Dependency Treebank
Panyur Sriwirote, Wei Qi Leong, Charin Polpanumas, Santhawat Thanyawong, William Chandra Tjhi, Wirote Aroonmanakun, Attapol T. Rutherford
Automatic dependency parsing of Thai sentences has been underexplored, as evidenced by the lack of large Thai dependency treebanks with complete dependency structures and the lack of a published systematic evaluation of state-of-the-art models, especially transformer-based parsers. In this work, we address these problems by introducing Thai Universal Dependency Treebank (TUD), a new largest Thai treebank consisting of 3,627 trees annotated in accordance with the Universal Dependencies (UD) framework. We then benchmark dependency parsing models that incorporate pretrained transformers as encoders and train them on Thai-PUD and our TUD. The evaluation results show that most of our models can outperform other models reported in previous papers and provide insight into the optimal choices of components to include in Thai dependency parsers. The new treebank and every model's full prediction generated in our experiment are made available on a GitHub repository for further study.
Read more5/14/2024

0
Dependency Annotation of Ottoman Turkish with Multilingual BERT
c{S}aziye Betul Ozatec{s}, Tar{i}k Emre T{i}rac{s}, Efe Eren Genc{c}, Esma Fat{i}ma Bilgin Tac{s}demir
This study introduces a pretrained large language model-based annotation methodology for the first de dency treebank in Ottoman Turkish. Our experimental results show that, iteratively, i) pseudo-annotating data using a multilingual BERT-based parsing model, ii) manually correcting the pseudo-annotations, and iii) fine-tuning the parsing model with the corrected annotations, we speed up and simplify the challenging dependency annotation process. The resulting treebank, that will be a part of the Universal Dependencies (UD) project, will facilitate automated analysis of Ottoman Turkish documents, unlocking the linguistic richness embedded in this historical heritage.
Read more8/23/2024
🤔
0
Multilingual Nonce Dependency Treebanks: Understanding how Language Models represent and process syntactic structure
David Arps, Laura Kallmeyer, Younes Samih, Hassan Sajjad
We introduce SPUD (Semantically Perturbed Universal Dependencies), a framework for creating nonce treebanks for the multilingual Universal Dependencies (UD) corpora. SPUD data satisfies syntactic argument structure, provides syntactic annotations, and ensures grammaticality via language-specific rules. We create nonce data in Arabic, English, French, German, and Russian, and demonstrate two use cases of SPUD treebanks. First, we investigate the effect of nonce data on word co-occurrence statistics, as measured by perplexity scores of autoregressive (ALM) and masked language models (MLM). We find that ALM scores are significantly more affected by nonce data than MLM scores. Second, we show how nonce data affects the performance of syntactic dependency probes. We replicate the findings of Muller-Eberstein et al. (2022) on nonce test data and show that the performance declines on both MLMs and ALMs wrt. original test data. However, a majority of the performance is kept, suggesting that the probe indeed learns syntax independently from semantics.
Read more6/13/2024

0
A Novel Dependency Framework for Enhancing Discourse Data Analysis
Kun Sun, Rong Wang
The development of different theories of discourse structure has led to the establishment of discourse corpora based on these theories. However, the existence of discourse corpora established on different theoretical bases creates challenges when it comes to exploring them in a consistent and cohesive way. This study has as its primary focus the conversion of PDTB annotations into dependency structures. It employs refined BERT-based discourse parsers to test the validity of the dependency data derived from the PDTB-style corpora in English, Chinese, and several other languages. By converting both PDTB and RST annotations for the same texts into dependencies, this study also applies ``dependency distance'' metrics to examine the correlation between RST dependencies and PDTB dependencies in English. The results show that the PDTB dependency data is valid and that there is a strong correlation between the two types of dependency distance. This study presents a comprehensive approach for analyzing and evaluating discourse corpora by employing discourse dependencies to achieve unified analysis. By applying dependency representations, we can extract data from PDTB, RST, and SDRT corpora in a coherent and unified manner. Moreover, the cross-linguistic validation establishes the framework's generalizability beyond English. The establishment of this comprehensive dependency framework overcomes limitations of existing discourse corpora, supporting a diverse range of algorithms and facilitating further studies in computational discourse analysis and language sciences.
Read more7/18/2024