Depth Estimation Based on 3D Gaussian Splatting Siamese Defocus

0
Sign in to get full access
Overview
- This paper proposes a novel depth estimation method based on 3D Gaussian splatting and Siamese defocus.
- The key ideas are to use 3D Gaussian splatting to model the defocus blur and train a Siamese network to estimate depth from this defocus information.
- The method aims to enable high-quality monocular depth estimation without the need for additional depth sensors or complex training data.
Plain English Explanation
The paper introduces a new way to estimate the depth of objects in an image using just a single camera. The core idea is to model how the camera's lens blurs objects at different distances - this blurring effect, called "defocus", provides important cues about an object's distance from the camera.
The researchers train a neural network to learn the relationship between this defocus blur and the actual depth of objects in the image. They do this by using a "Siamese" network architecture, which compares the blur patterns of different image regions to infer the relative depths.
By modeling the defocus blur with 3D Gaussian splatting, the method can capture the complex 3D nature of blur, allowing for more accurate depth estimation compared to simpler 2D blur models. The end result is a depth estimation system that works from a single camera, without needing additional depth sensors or extensive training data.
Technical Explanation
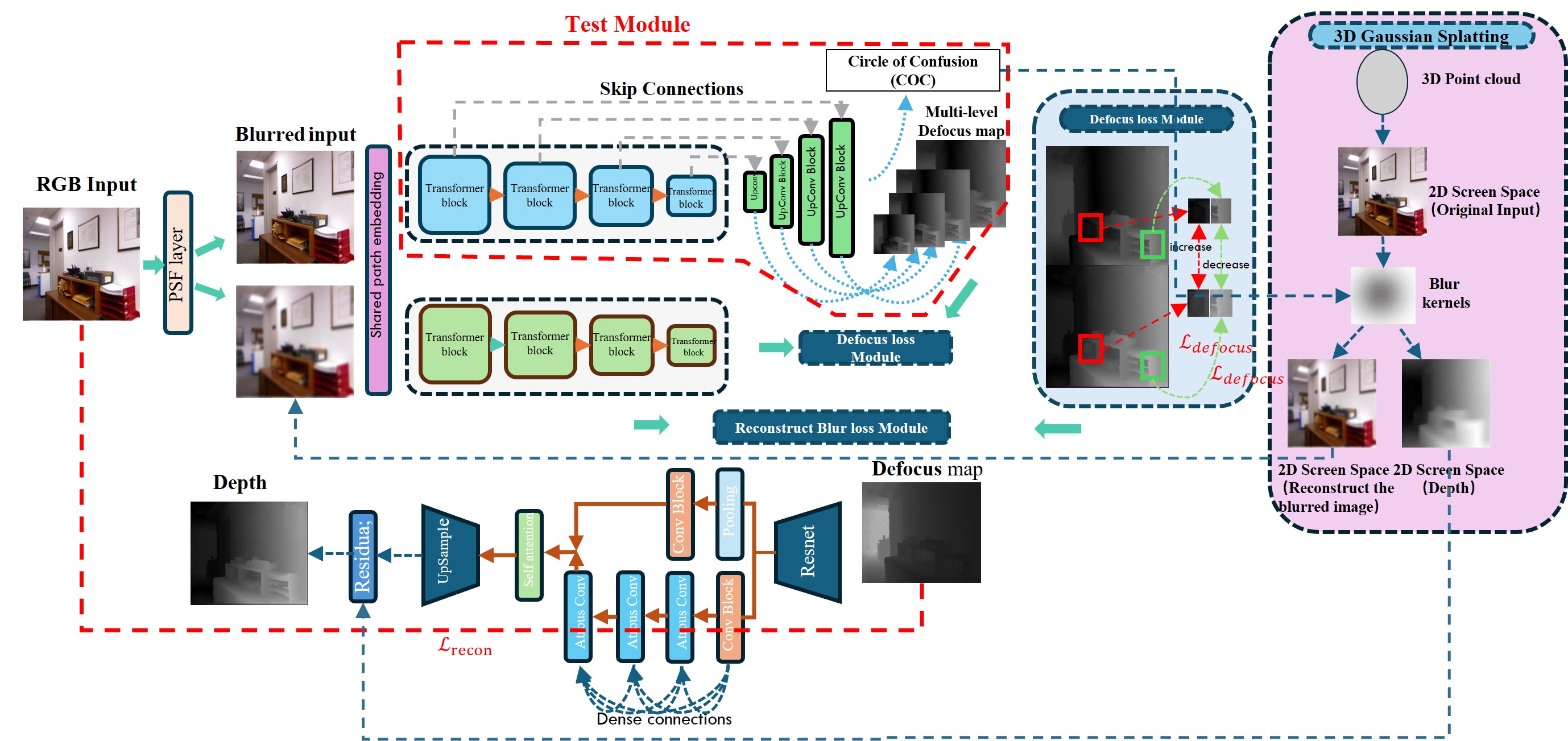
The paper proposes a novel monocular depth estimation method based on 3D Gaussian splatting and a Siamese network architecture. The key technical components are:
-
3D Gaussian Splatting: The researchers model the defocus blur in the image using a 3D Gaussian splat, which can capture the complex 3D nature of the blur more accurately than previous 2D blur models. This 3D splat is parameterized by the depth of the object.
-
Siamese Network: The depth estimation network has a Siamese architecture, meaning it takes two image patches as input and compares their blur patterns to infer the relative depth between them. This Siamese design allows the network to learn the relationship between defocus blur and depth without requiring explicit depth supervision.
-
Self-Supervised Training: The network is trained in a self-supervised manner, meaning it learns to estimate depth without needing ground truth depth maps during training. Instead, the network is trained to minimize the difference between the predicted depth map and the one derived from the 3D Gaussian splatting model.
The researchers evaluate their method on several benchmark depth estimation datasets and show that it outperforms previous state-of-the-art monocular depth estimation techniques, especially in challenging scenarios with large depth variations and texture-less regions.
Critical Analysis
The paper presents a promising approach to monocular depth estimation that leverages the defocus blur cue in a novel way. The use of 3D Gaussian splatting to model the blur is an interesting technical contribution, as it can capture the true 3D nature of the blur more accurately than previous 2D models.
However, the paper does not discuss potential limitations or failure cases of the method. For example, it's not clear how the method would perform in low-light conditions or with very small/large objects, where the defocus blur may be less prominent or more challenging to model. Additionally, the self-supervised training approach, while appealing, may be sensitive to biases in the training data.
Further research would be needed to better understand the robustness and generalization capabilities of this depth estimation approach. Comparisons to other self-supervised or semi-supervised depth estimation methods would also help contextualize the contributions of this work.
Conclusion
This paper presents a novel monocular depth estimation method based on 3D Gaussian splatting and a Siamese network architecture. By modeling the defocus blur in a more accurate 3D manner and learning the relationship between blur and depth in a self-supervised way, the researchers have developed a depth estimation system that can work with a single camera, without requiring additional depth sensors or extensive training data.
While the technical approach is promising, further research is needed to fully understand the method's limitations and generalization capabilities. If these challenges can be addressed, this work could contribute to the development of more robust and accessible depth estimation solutions for a variety of applications, from augmented reality to autonomous navigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Depth Estimation Based on 3D Gaussian Splatting Siamese Defocus
Jinchang Zhang, Ningning Xu, Hao Zhang, Guoyu Lu
Depth estimation is a fundamental task in 3D geometry. While stereo depth estimation can be achieved through triangulation methods, it is not as straightforward for monocular methods, which require the integration of global and local information. The Depth from Defocus (DFD) method utilizes camera lens models and parameters to recover depth information from blurred images and has been proven to perform well. However, these methods rely on All-In-Focus (AIF) images for depth estimation, which is nearly impossible to obtain in real-world applications. To address this issue, we propose a self-supervised framework based on 3D Gaussian splatting and Siamese networks. By learning the blur levels at different focal distances of the same scene in the focal stack, the framework predicts the defocus map and Circle of Confusion (CoC) from a single defocused image, using the defocus map as input to DepthNet for monocular depth estimation. The 3D Gaussian splatting model renders defocused images using the predicted CoC, and the differences between these and the real defocused images provide additional supervision signals for the Siamese Defocus self-supervised network. This framework has been validated on both artificially synthesized and real blurred datasets. Subsequent quantitative and visualization experiments demonstrate that our proposed framework is highly effective as a DFD method.
Read more9/20/2024

0
DOF-GS: Adjustable Depth-of-Field 3D Gaussian Splatting for Refocusing,Defocus Rendering and Blur Removal
Yujie Wang, Praneeth Chakravarthula, Baoquan Chen
3D Gaussian Splatting-based techniques have recently advanced 3D scene reconstruction and novel view synthesis, achieving high-quality real-time rendering. However, these approaches are inherently limited by the underlying pinhole camera assumption in modeling the images and hence only work for All-in-Focus (AiF) sharp image inputs. This severely affects their applicability in real-world scenarios where images often exhibit defocus blur due to the limited depth-of-field (DOF) of imaging devices. Additionally, existing 3D Gaussian Splatting (3DGS) methods also do not support rendering of DOF effects. To address these challenges, we introduce DOF-GS that allows for rendering adjustable DOF effects, removing defocus blur as well as refocusing of 3D scenes, all from multi-view images degraded by defocus blur. To this end, we re-imagine the traditional Gaussian Splatting pipeline by employing a finite aperture camera model coupled with explicit, differentiable defocus rendering guided by the Circle-of-Confusion (CoC). The proposed framework provides for dynamic adjustment of DOF effects by changing the aperture and focal distance of the underlying camera model on-demand. It also enables rendering varying DOF effects of 3D scenes post-optimization, and generating AiF images from defocused training images. Furthermore, we devise a joint optimization strategy to further enhance details in the reconstructed scenes by jointly optimizing rendered defocused and AiF images. Our experimental results indicate that DOF-GS produces high-quality sharp all-in-focus renderings conditioned on inputs compromised by defocus blur, with the training process incurring only a modest increase in GPU memory consumption. We further demonstrate the applications of the proposed method for adjustable defocus rendering and refocusing of the 3D scene from input images degraded by defocus blur.
Read more5/28/2024
0
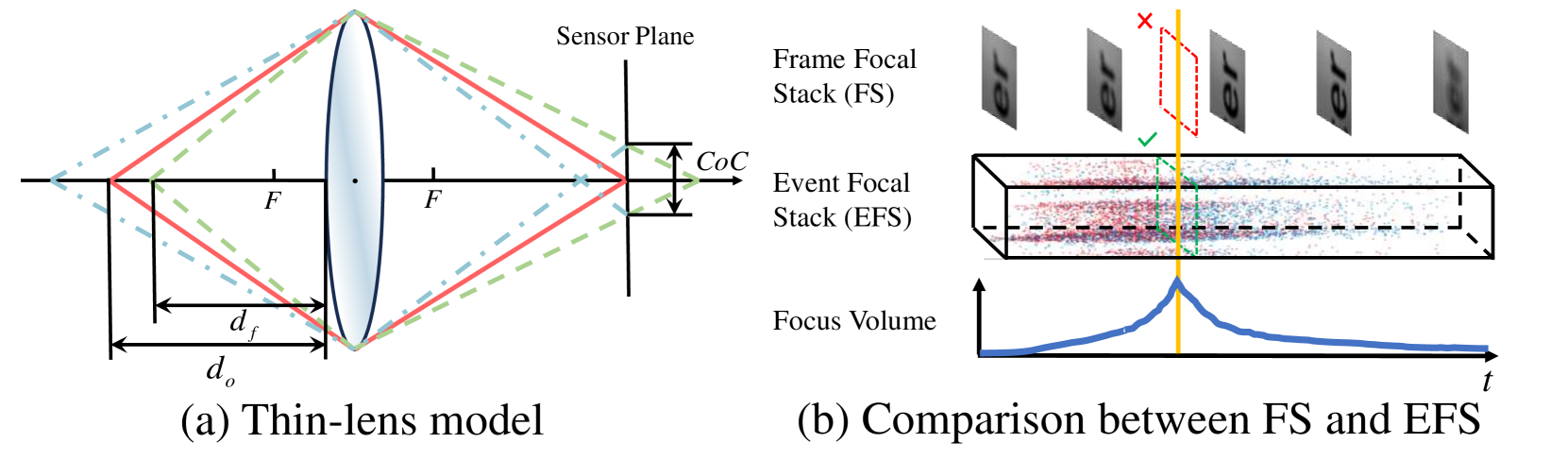
Learning Monocular Depth from Focus with Event Focal Stack
Chenxu Jiang, Mingyuan Lin, Chi Zhang, Zhenghai Wang, Lei Yu
Depth from Focus estimates depth by determining the moment of maximum focus from multiple shots at different focal distances, i.e. the Focal Stack. However, the limited sampling rate of conventional optical cameras makes it difficult to obtain sufficient focus cues during the focal sweep. Inspired by biological vision, the event camera records intensity changes over time in extremely low latency, which provides more temporal information for focus time acquisition. In this study, we propose the EDFF Network to estimate sparse depth from the Event Focal Stack. Specifically, we utilize the event voxel grid to encode intensity change information and project event time surface into the depth domain to preserve per-pixel focal distance information. A Focal-Distance-guided Cross-Modal Attention Module is presented to fuse the information mentioned above. Additionally, we propose a Multi-level Depth Fusion Block designed to integrate results from each level of a UNet-like architecture and produce the final output. Extensive experiments validate that our method outperforms existing state-of-the-art approaches.
Read more5/14/2024
0
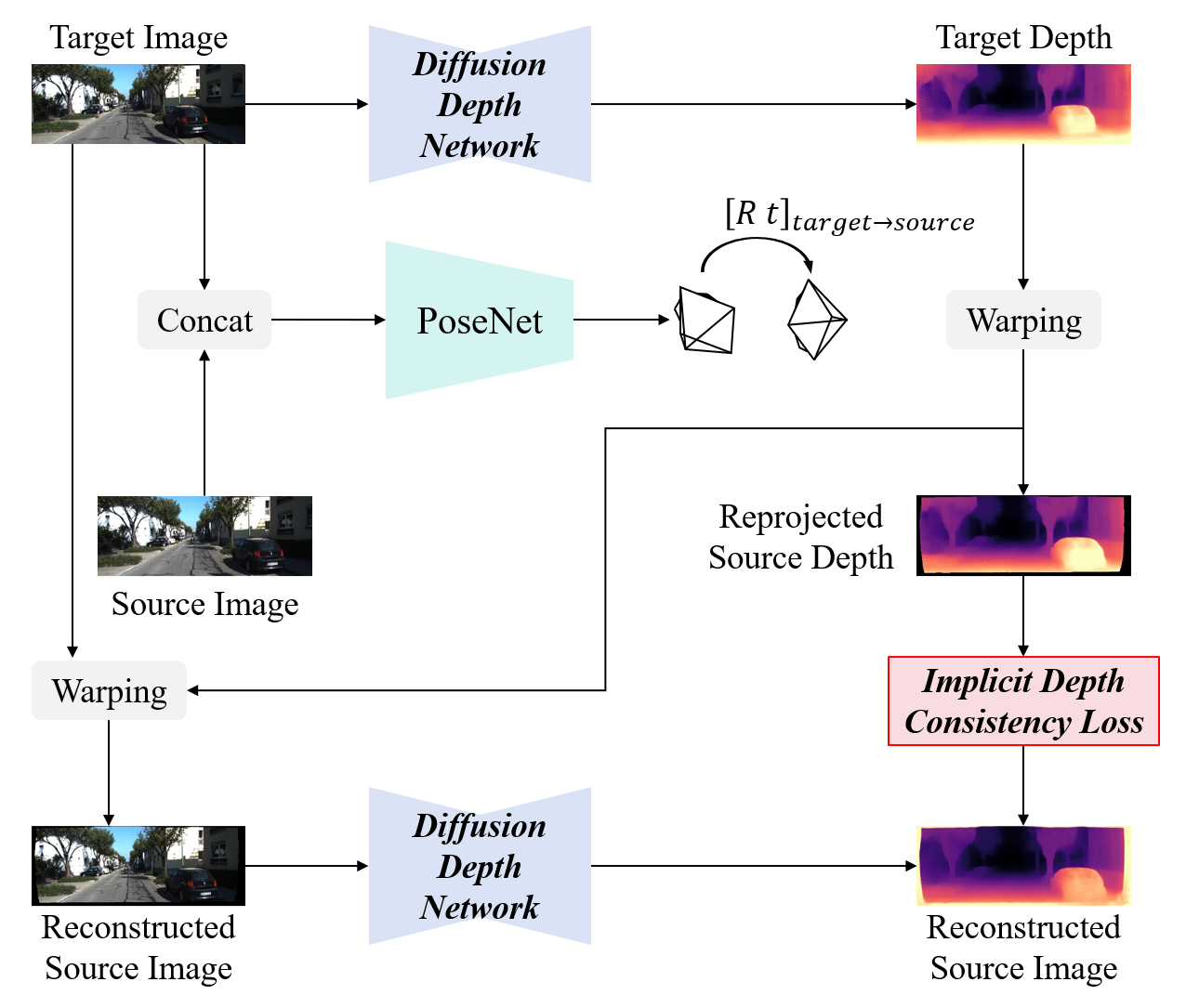
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
Read more6/17/2024