Learning Monocular Depth from Focus with Event Focal Stack

0
Sign in to get full access
Overview
- This paper presents a novel method for monocular depth estimation using event cameras and deep learning.
- The key idea is to leverage the focal stack information captured by event cameras to learn depth from focus.
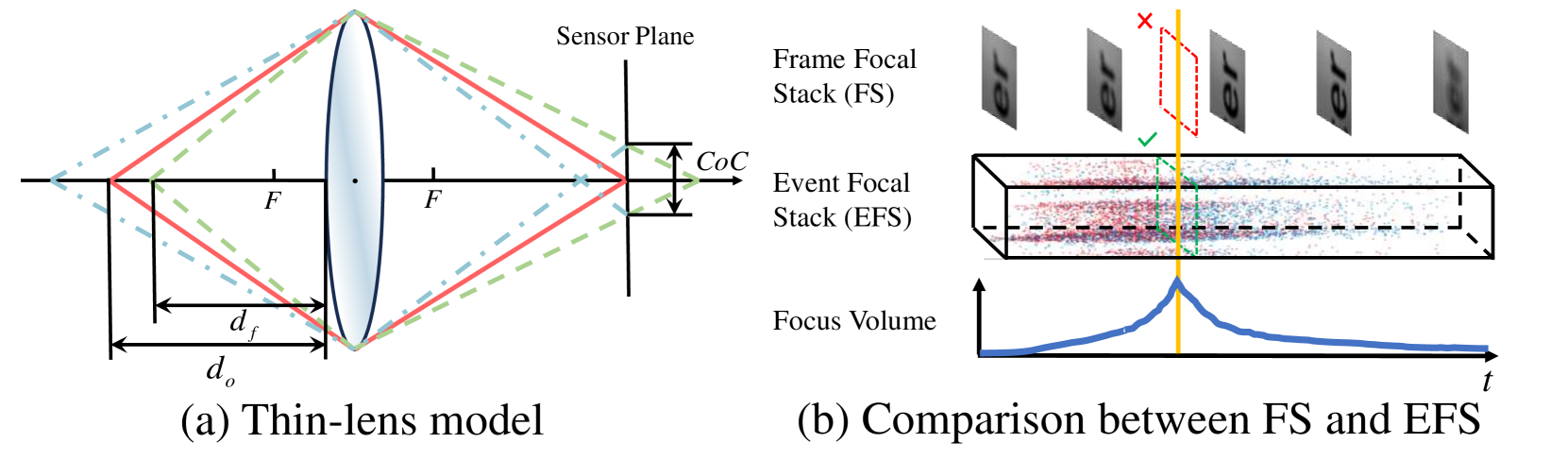
- The authors introduce an "Event Focal Stack" representation that captures the defocus blur in event data, which is then used to train a deep neural network for depth prediction.
- The proposed approach outperforms state-of-the-art monocular depth estimation methods on several benchmark datasets.
Plain English Explanation
The paper introduces a new way to estimate the depth of a scene using a single camera (called "monocular" depth estimation). The key insight is to use a specialized type of camera called an "event camera" that can capture information about the focus of the image.
Event cameras work differently than regular cameras. Instead of capturing a series of full frames, they only record changes in the brightness of individual pixels over time. This allows them to capture very fast motion and changes in the scene with high precision.
The authors realized that the way the image goes in and out of focus as the camera adjusts can provide valuable information about the depth of objects in the scene. They developed a way to represent this "focal stack" information from the event camera data and use it to train a deep learning model to predict the depth of the scene.
By using this novel event-based focal stack representation, the researchers were able to create a monocular depth estimation system that outperforms other state-of-the-art methods. This could be useful for applications like augmented reality, 3D reconstruction, and robotics that require accurate depth information from a single camera.
Technical Explanation
The key technical contributions of the paper are:
-
Event Focal Stack Representation: The authors introduce a new way to represent the defocus blur information captured by an event camera as an "Event Focal Stack". This is a multi-channel tensor that encodes the temporal dynamics of the event camera's focus over time.
-
Depth Estimation Network: The researchers train a deep neural network to predict monocular depth from the Event Focal Stack input. The network is based on a UNet-style architecture with several encoder-decoder blocks.
-
Evaluation: The proposed depth estimation system is evaluated on several standard benchmarks, including the MVOR and ScanNet datasets. The results show that it outperforms previous state-of-the-art monocular depth estimation methods.
The key insight behind the Event Focal Stack representation is that the temporal dynamics of focus blur captured by an event camera can provide valuable depth cues. By learning to map this representation to accurate depth predictions, the model can leverage this additional source of information beyond what is available in a single static image.
Critical Analysis
The paper presents a novel and promising approach to monocular depth estimation, but it also has some limitations and areas for further research:
-
Event Camera Availability: Event cameras are still a relatively niche and expensive technology compared to standard cameras. The widespread adoption of this method may be limited by the availability and cost of event camera hardware.
-
Sensitivity to Camera Motion: The method relies on the camera's focus changing over time to capture the focal stack information. This means it may be sensitive to camera motion and could perform poorly in situations with a static camera.
-
Comparison to Other Depth Cues: The paper does not compare the performance of the Event Focal Stack representation to other depth cues, such as stereo disparity or learned image features. It would be interesting to see how the different approaches complement each other.
-
Application-Specific Evaluation: The evaluation focuses on general benchmarks, but it would be valuable to assess the method's performance in specific application domains, such as AR/VR or robotics, where accurate monocular depth estimation is particularly important.
Overall, the paper presents a novel and promising approach to monocular depth estimation that leverages the unique properties of event cameras. Further research and evaluation in real-world application scenarios could help to better understand the strengths and limitations of this method.
Conclusion
This paper introduces a new method for monocular depth estimation that uses the focal stack information captured by event cameras. By representing this data as an "Event Focal Stack" and training a deep neural network to predict depth from it, the researchers were able to outperform state-of-the-art monocular depth estimation techniques on several benchmark datasets.
The key innovation is the use of the event camera's ability to capture the temporal dynamics of focus blur, which provides valuable depth cues beyond what is available in a single static image. While the method has some limitations, such as the current niche status of event cameras, it represents an exciting step forward in the field of monocular depth estimation with potential applications in areas like augmented reality, 3D reconstruction, and robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Monocular Depth from Focus with Event Focal Stack
Chenxu Jiang, Mingyuan Lin, Chi Zhang, Zhenghai Wang, Lei Yu
Depth from Focus estimates depth by determining the moment of maximum focus from multiple shots at different focal distances, i.e. the Focal Stack. However, the limited sampling rate of conventional optical cameras makes it difficult to obtain sufficient focus cues during the focal sweep. Inspired by biological vision, the event camera records intensity changes over time in extremely low latency, which provides more temporal information for focus time acquisition. In this study, we propose the EDFF Network to estimate sparse depth from the Event Focal Stack. Specifically, we utilize the event voxel grid to encode intensity change information and project event time surface into the depth domain to preserve per-pixel focal distance information. A Focal-Distance-guided Cross-Modal Attention Module is presented to fuse the information mentioned above. Additionally, we propose a Multi-level Depth Fusion Block designed to integrate results from each level of a UNet-like architecture and produce the final output. Extensive experiments validate that our method outperforms existing state-of-the-art approaches.
Read more5/14/2024
🔎
0
SRFNet: Monocular Depth Estimation with Fine-grained Structure via Spatial Reliability-oriented Fusion of Frames and Events
Tianbo Pan, Zidong Cao, Lin Wang
Monocular depth estimation is a crucial task to measure distance relative to a camera, which is important for applications, such as robot navigation and self-driving. Traditional frame-based methods suffer from performance drops due to the limited dynamic range and motion blur. Therefore, recent works leverage novel event cameras to complement or guide the frame modality via frame-event feature fusion. However, event streams exhibit spatial sparsity, leaving some areas unperceived, especially in regions with marginal light changes. Therefore, direct fusion methods, e.g., RAMNet, often ignore the contribution of the most confident regions of each modality. This leads to structural ambiguity in the modality fusion process, thus degrading the depth estimation performance. In this paper, we propose a novel Spatial Reliability-oriented Fusion Network (SRFNet), that can estimate depth with fine-grained structure at both daytime and nighttime. Our method consists of two key technical components. Firstly, we propose an attention-based interactive fusion (AIF) module that applies spatial priors of events and frames as the initial masks and learns the consensus regions to guide the inter-modal feature fusion. The fused feature are then fed back to enhance the frame and event feature learning. Meanwhile, it utilizes an output head to generate a fused mask, which is iteratively updated for learning consensual spatial priors. Secondly, we propose the Reliability-oriented Depth Refinement (RDR) module to estimate dense depth with the fine-grained structure based on the fused features and masks. We evaluate the effectiveness of our method on the synthetic and real-world datasets, which shows that, even without pretraining, our method outperforms the prior methods, e.g., RAMNet, especially in night scenes. Our project homepage: https://vlislab22.github.io/SRFNet.
Read more7/25/2024
0
Focal Depth Estimation: A Calibration-Free, Subject- and Daytime Invariant Approach
Benedikt W. Hosp, Bjorn Severitt, Rajat Agarwala, Evgenia Rusak, Yannick Sauer, Siegfried Wahl
In an era where personalized technology is increasingly intertwined with daily life, traditional eye-tracking systems and autofocal glasses face a significant challenge: the need for frequent, user-specific calibration, which impedes their practicality. This study introduces a groundbreaking calibration-free method for estimating focal depth, leveraging machine learning techniques to analyze eye movement features within short sequences. Our approach, distinguished by its innovative use of LSTM networks and domain-specific feature engineering, achieves a mean absolute error (MAE) of less than 10 cm, setting a new focal depth estimation accuracy standard. This advancement promises to enhance the usability of autofocal glasses and pave the way for their seamless integration into extended reality environments, marking a significant leap forward in personalized visual technology.
Read more8/9/2024
🌐
0
A Novel Spike Transformer Network for Depth Estimation from Event Cameras via Cross-modality Knowledge Distillation
Xin Zhang, Liangxiu Han, Tam Sobeih, Lianghao Han, Darren Dancey
Depth estimation is crucial for interpreting complex environments, especially in areas such as autonomous vehicle navigation and robotics. Nonetheless, obtaining accurate depth readings from event camera data remains a formidable challenge. Event cameras operate differently from traditional digital cameras, continuously capturing data and generating asynchronous binary spikes that encode time, location, and light intensity. Yet, the unique sampling mechanisms of event cameras render standard image based algorithms inadequate for processing spike data. This necessitates the development of innovative, spike-aware algorithms tailored for event cameras, a task compounded by the irregularity, continuity, noise, and spatial and temporal characteristics inherent in spiking data.Harnessing the strong generalization capabilities of transformer neural networks for spatiotemporal data, we propose a purely spike-driven spike transformer network for depth estimation from spiking camera data. To address performance limitations with Spiking Neural Networks (SNN), we introduce a novel single-stage cross-modality knowledge transfer framework leveraging knowledge from a large vision foundational model of artificial neural networks (ANN) (DINOv2) to enhance the performance of SNNs with limited data. Our experimental results on both synthetic and real datasets show substantial improvements over existing models, with notable gains in Absolute Relative and Square Relative errors (49% and 39.77% improvements over the benchmark model Spike-T, respectively). Besides accuracy, the proposed model also demonstrates reduced power consumptions, a critical factor for practical applications.
Read more5/2/2024