Described Spatial-Temporal Video Detection

0

Sign in to get full access
Overview
- This paper presents a novel approach for detecting and tracking multiple objects in video data using a spatial-temporal video detection model.
- The proposed method leverages both spatial and temporal information to improve the accuracy and robustness of object detection and tracking in complex video scenarios.
- The model is evaluated on several benchmark datasets, demonstrating state-of-the-art performance in multi-object tracking and video object detection tasks.
Plain English Explanation
The paper describes a new way to detect and follow multiple objects in video. Typically, object detection in videos is done by looking at each frame separately. However, this can miss important information about how the objects move and change over time. The researchers developed a model that considers both the spatial (where things are) and temporal (how things move) aspects of the video.
By taking the video's full spatial-temporal context into account, the model is better able to identify and track multiple objects as they move around the scene. This leads to more accurate and reliable object detection and tracking, even in complex video scenarios with lots of activity and occlusion.
The model was tested on standard video benchmarks and achieved state-of-the-art performance, outperforming previous approaches that only looked at individual frames. This suggests the spatial-temporal approach is a promising direction for improving video understanding tasks like multi-object tracking and video object detection.
Technical Explanation
The paper introduces a Described Spatial-Temporal Video Detection model that leverages both spatial and temporal information to improve the accuracy and robustness of multi-object tracking and video object detection.
The key innovation is the use of a spatial-temporal graph that encodes the relationships between objects across both space and time. This allows the model to reason about how objects move and interact over the course of a video, rather than just considering each frame in isolation.
The spatial-temporal graph is integrated into a deep neural network architecture that performs end-to-end object detection and tracking. Experiments on benchmark datasets like Open Vocabulary Spatio-Temporal Action Detection and Dense Video Object Captioning demonstrate state-of-the-art performance, outperforming previous methods that only consider the spatial or temporal aspects in isolation.
The Correlation Guided Query Dependency Calibration for Video Temporal Reasoning module is also integrated to further enhance the model's ability to reason about object relationships and interactions over time.
Overall, this work represents an important advance in video understanding, showing how combining spatial and temporal cues can lead to significant improvements in multi-object tracking and video object detection.
Critical Analysis
The paper makes a compelling case for the benefits of the proposed spatial-temporal approach, with thorough experimental validation on benchmark datasets. However, there are a few potential limitations and areas for future work worth considering:
-
The model's performance may be sensitive to the quality and consistency of the input video data. Noisy, low-resolution, or heavily occluded videos could still pose challenges for accurate object detection and tracking.
-
The spatial-temporal graph representation and associated reasoning mechanisms, while powerful, add significant complexity to the model. Deploying such a system in real-world, resource-constrained applications may require further optimization and simplification.
-
The paper does not explore the model's generalization capabilities beyond the specific benchmarks used. Assessing its performance on a wider range of video domains and tasks would help validate the broader applicability of the approach.
-
While the Correlation Guided Query Dependency Calibration module helps, there may be additional ways to further improve the model's temporal reasoning abilities, such as through the Enhancing Video-Language Representations with Structural Spatio-Temporal information.
Overall, this work represents a significant advance in video understanding, and the proposed spatial-temporal approach is a promising direction for future research in this field.
Conclusion
This paper presents a novel Described Spatial-Temporal Video Detection model that leverages both spatial and temporal information to improve the performance of multi-object tracking and video object detection tasks. By encoding the relationships between objects across space and time using a spatial-temporal graph, the model is able to reason about object movements and interactions more effectively than previous methods that only consider individual video frames.
Experimental results on benchmark datasets demonstrate the effectiveness of the proposed approach, with the model achieving state-of-the-art performance. While the spatial-temporal graph representation introduces additional complexity, this work suggests that incorporating both spatial and temporal cues is a crucial step towards more robust and reliable video understanding systems.
The paper also highlights several avenues for future research, such as improving the model's generalization capabilities, optimizing its efficiency for real-world deployment, and exploring additional techniques to enhance its temporal reasoning abilities. Overall, this research represents an important advancement in the field of video understanding and has the potential to enable a wide range of practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Described Spatial-Temporal Video Detection
Wei Ji, Xiangyan Liu, Yingfei Sun, Jiajun Deng, You Qin, Ammar Nuwanna, Mengyao Qiu, Lina Wei, Roger Zimmermann
Detecting visual content on language expression has become an emerging topic in the community. However, in the video domain, the existing setting, i.e., spatial-temporal video grounding (STVG), is formulated to only detect one pre-existing object in each frame, ignoring the fact that language descriptions can involve none or multiple entities within a video. In this work, we advance the STVG to a more practical setting called described spatial-temporal video detection (DSTVD) by overcoming the above limitation. To facilitate the exploration of DSTVD, we first introduce a new benchmark, namely DVD-ST. Notably, DVD-ST supports grounding from none to many objects onto the video in response to queries and encompasses a diverse range of over 150 entities, including appearance, actions, locations, and interactions. The extensive breadth and diversity of the DVD-ST dataset make it an exemplary testbed for the investigation of DSTVD. In addition to the new benchmark, we further present two baseline methods for our proposed DSTVD task by extending two representative STVG models, i.e., TubeDETR, and STCAT. These extended models capitalize on tubelet queries to localize and track referred objects across the video sequence. Besides, we adjust the training objectives of these models to optimize spatial and temporal localization accuracy and multi-class classification capabilities. Furthermore, we benchmark the baselines on the introduced DVD-ST dataset and conduct extensive experimental analysis to guide future investigation. Our code and benchmark will be publicly available.
Read more7/9/2024
0
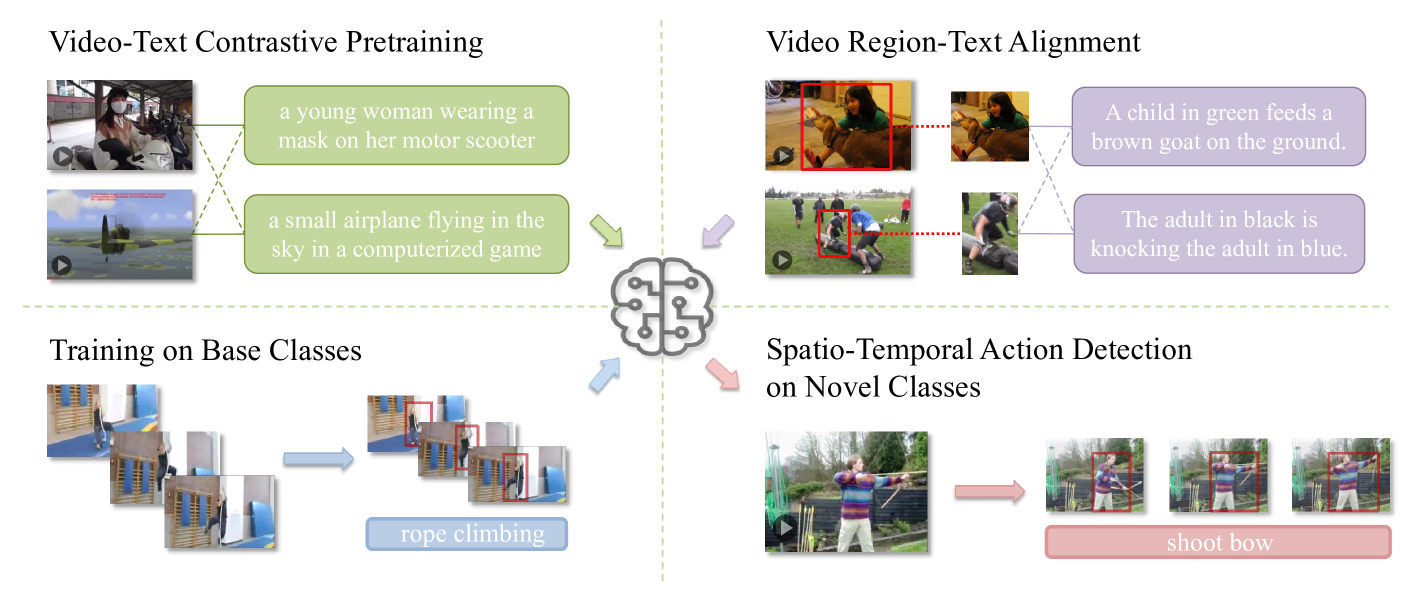
Open-Vocabulary Spatio-Temporal Action Detection
Tao Wu, Shuqiu Ge, Jie Qin, Gangshan Wu, Limin Wang
Spatio-temporal action detection (STAD) is an important fine-grained video understanding task. Current methods require box and label supervision for all action classes in advance. However, in real-world applications, it is very likely to come across new action classes not seen in training because the action category space is large and hard to enumerate. Also, the cost of data annotation and model training for new classes is extremely high for traditional methods, as we need to perform detailed box annotations and re-train the whole network from scratch. In this paper, we propose a new challenging setting by performing open-vocabulary STAD to better mimic the situation of action detection in an open world. Open-vocabulary spatio-temporal action detection (OV-STAD) requires training a model on a limited set of base classes with box and label supervision, which is expected to yield good generalization performance on novel action classes. For OV-STAD, we build two benchmarks based on the existing STAD datasets and propose a simple but effective method based on pretrained video-language models (VLM). To better adapt the holistic VLM for the fine-grained action detection task, we carefully fine-tune it on the localized video region-text pairs. This customized fine-tuning endows the VLM with better motion understanding, thus contributing to a more accurate alignment between video regions and texts. Local region feature and global video feature fusion before alignment is adopted to further improve the action detection performance by providing global context. Our method achieves a promising performance on novel classes.
Read more5/20/2024
0
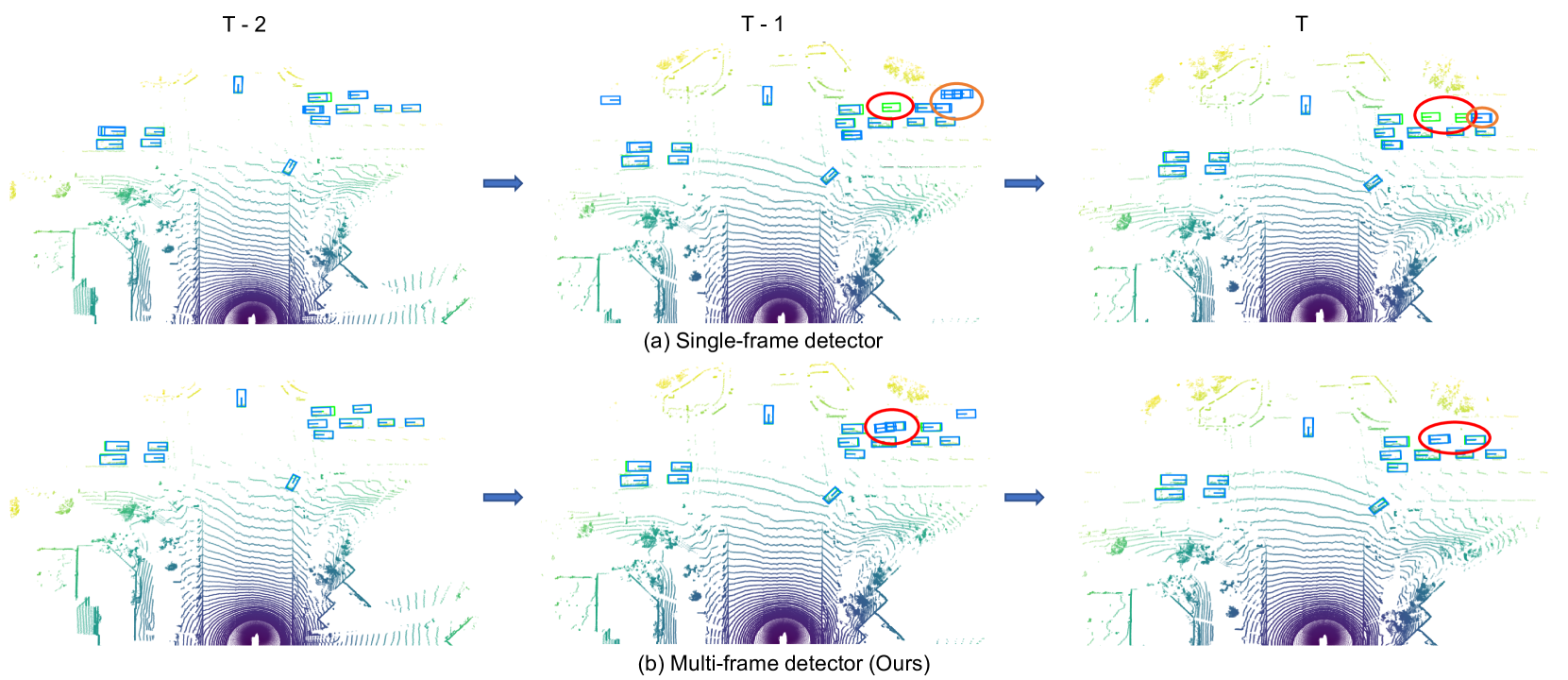
Spatial-Temporal Graph Enhanced DETR Towards Multi-Frame 3D Object Detection
Yifan Zhang, Zhiyu Zhu, Junhui Hou, Dapeng Wu
The Detection Transformer (DETR) has revolutionized the design of CNN-based object detection systems, showcasing impressive performance. However, its potential in the domain of multi-frame 3D object detection remains largely unexplored. In this paper, we present STEMD, a novel end-to-end framework that enhances the DETR-like paradigm for multi-frame 3D object detection by addressing three key aspects specifically tailored for this task. First, to model the inter-object spatial interaction and complex temporal dependencies, we introduce the spatial-temporal graph attention network, which represents queries as nodes in a graph and enables effective modeling of object interactions within a social context. To solve the problem of missing hard cases in the proposed output of the encoder in the current frame, we incorporate the output of the previous frame to initialize the query input of the decoder. Finally, it poses a challenge for the network to distinguish between the positive query and other highly similar queries that are not the best match. And similar queries are insufficiently suppressed and turn into redundant prediction boxes. To address this issue, our proposed IoU regularization term encourages similar queries to be distinct during the refinement. Through extensive experiments, we demonstrate the effectiveness of our approach in handling challenging scenarios, while incurring only a minor additional computational overhead. The code is publicly available at https://github.com/Eaphan/STEMD.
Read more8/14/2024
🌿
0
Structured Video-Language Modeling with Temporal Grouping and Spatial Grounding
Yuanhao Xiong, Long Zhao, Boqing Gong, Ming-Hsuan Yang, Florian Schroff, Ting Liu, Cho-Jui Hsieh, Liangzhe Yuan
Existing video-language pre-training methods primarily focus on instance-level alignment between video clips and captions via global contrastive learning but neglect rich fine-grained local information in both videos and text, which is of importance to downstream tasks requiring temporal localization and semantic reasoning. A powerful model is expected to be capable of capturing region-object correspondences and recognizing scene changes in a video clip, reflecting spatial and temporal granularity, respectively. To strengthen model's understanding into such fine-grained details, we propose a simple yet effective video-language modeling framework, S-ViLM, by exploiting the intrinsic structures of these two modalities. It includes two novel designs, inter-clip spatial grounding and intra-clip temporal grouping, to promote learning region-object alignment and temporal-aware features, simultaneously. Comprehensive evaluations demonstrate that S-ViLM performs favorably against existing approaches in learning more expressive representations. Specifically, S-ViLM surpasses the state-of-the-art methods substantially on four representative downstream tasks, covering text-video retrieval, video question answering, video action recognition, and temporal action localization.
Read more9/10/2024