Spatial-Temporal Graph Enhanced DETR Towards Multi-Frame 3D Object Detection

0
Sign in to get full access
Overview
- This paper presents a Spatial-Temporal Enhanced Transformer (STET) model for multi-frame 3D object detection.
- The model aims to effectively leverage temporal information from multiple frames to improve 3D object detection performance.
- STET combines a Transformer-based architecture with a Graph Attention Network (GAT) to capture both spatial and temporal features from point cloud data.
Plain English Explanation
The Spatial-Temporal Enhanced Transformer (STET) is a new approach for 3D object detection that uses information from multiple camera frames over time, rather than just a single frame. This is important for applications like self-driving cars, where being able to track objects over time can help make better decisions.
The key idea is to use a Transformer architecture, which is a type of neural network that can effectively process sequential data like video or audio. The Transformer is combined with a Graph Attention Network (GAT), which helps the model understand the spatial relationships between different objects in the 3D point cloud data.
By considering both the spatial information (where objects are located) and the temporal information (how objects move over time), the STET model is able to make more accurate 3D object detections compared to previous approaches that only used a single frame of data. This could lead to improvements in applications like autonomous driving, where tracking objects over time is crucial for safe navigation.
Technical Explanation
The Spatial-Temporal Enhanced Transformer (STET) model consists of several key components:
-
Temporal Encoding: The model takes in 3D point cloud data from multiple consecutive frames and encodes the temporal information using a Transformer-based architecture. This allows the model to understand how objects move and change over time.
-
Spatial Encoding: In parallel, the model uses a Graph Attention Network (GAT) to encode the spatial relationships between objects in the 3D point cloud data. This helps the model understand the context and structure of the scene.
-
Spatial-Temporal Fusion: The temporal and spatial encodings are then fused together using a series of attention mechanisms and residual connections. This allows the model to effectively leverage both spatial and temporal information for improved 3D object detection.
-
Object Detection Head: The fused spatial-temporal features are then passed to a detection head, which outputs the bounding boxes and class labels for the detected 3D objects.
The authors evaluate the STET model on several benchmark 3D object detection datasets, including nuScenes and Waymo Open Dataset. Their results show that STET outperforms state-of-the-art single-frame 3D object detectors, demonstrating the benefits of incorporating temporal information for this task.
Critical Analysis
The Spatial-Temporal Enhanced Transformer (STET) model presents a promising approach for leveraging temporal information in 3D object detection. However, the paper does not address some potential limitations and areas for further research:
-
Computational Complexity: Incorporating multiple frames of data and the additional spatial-temporal processing components may increase the computational cost of the model, which could be a concern for real-time applications like autonomous driving.
-
Sensitivity to Occlusions: The paper does not discuss how the model handles occlusions, where objects are partially hidden from view. Temporal information may not be as useful in these cases, and the model's performance could be affected.
-
Generalization to Diverse Environments: The evaluation is primarily focused on urban driving scenarios. It would be valuable to assess the model's performance in other environments, such as rural areas or complex indoor scenes, to understand its broader applicability.
-
Interpretability: The Transformer and GAT components of the model can be viewed as "black boxes," making it difficult to understand the specific spatial and temporal cues the model is using to make its predictions. Improving the interpretability of the model could lead to valuable insights for further research and development.
Conclusion
The Spatial-Temporal Enhanced Transformer (STET) model represents an important step forward in leveraging temporal information for 3D object detection. By combining Transformer-based temporal encoding with a Graph Attention Network for spatial understanding, the model is able to achieve state-of-the-art performance on several benchmark datasets.
This research has significant implications for applications like autonomous driving, where the ability to track objects over time is crucial for safe navigation and decision-making. While the paper highlights the potential of this approach, further research is needed to address the computational complexity, robustness to occlusions, and interpretability of the model.
Overall, the Spatial-Temporal Enhanced Transformer (STET) model is a promising contribution to the field of 3D object detection, and it paves the way for future advancements in this important area of computer vision and robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
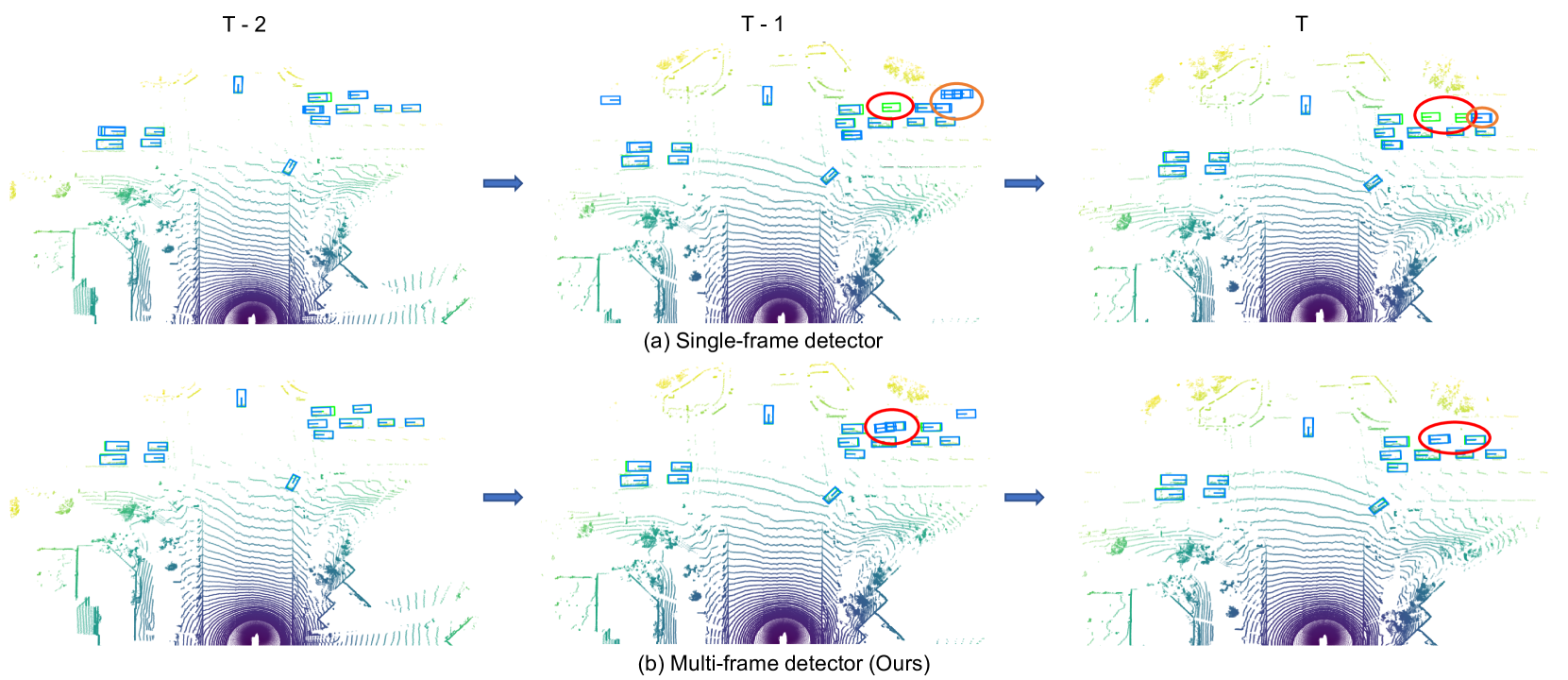
Spatial-Temporal Graph Enhanced DETR Towards Multi-Frame 3D Object Detection
Yifan Zhang, Zhiyu Zhu, Junhui Hou, Dapeng Wu
The Detection Transformer (DETR) has revolutionized the design of CNN-based object detection systems, showcasing impressive performance. However, its potential in the domain of multi-frame 3D object detection remains largely unexplored. In this paper, we present STEMD, a novel end-to-end framework that enhances the DETR-like paradigm for multi-frame 3D object detection by addressing three key aspects specifically tailored for this task. First, to model the inter-object spatial interaction and complex temporal dependencies, we introduce the spatial-temporal graph attention network, which represents queries as nodes in a graph and enables effective modeling of object interactions within a social context. To solve the problem of missing hard cases in the proposed output of the encoder in the current frame, we incorporate the output of the previous frame to initialize the query input of the decoder. Finally, it poses a challenge for the network to distinguish between the positive query and other highly similar queries that are not the best match. And similar queries are insufficiently suppressed and turn into redundant prediction boxes. To address this issue, our proposed IoU regularization term encourages similar queries to be distinct during the refinement. Through extensive experiments, we demonstrate the effectiveness of our approach in handling challenging scenarios, while incurring only a minor additional computational overhead. The code is publicly available at https://github.com/Eaphan/STEMD.
Read more8/14/2024

0
New!RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision
Shuo Wang, Chunlong Xia, Feng Lv, Yifeng Shi
RT-DETR is the first real-time end-to-end transformer-based object detector. Its efficiency comes from the framework design and the Hungarian matching. However, compared to dense supervision detectors like the YOLO series, the Hungarian matching provides much sparser supervision, leading to insufficient model training and difficult to achieve optimal results. To address these issues, we proposed a hierarchical dense positive supervision method based on RT-DETR, named RT-DETRv3. Firstly, we introduce a CNN-based auxiliary branch that provides dense supervision that collaborates with the original decoder to enhance the encoder feature representation. Secondly, to address insufficient decoder training, we propose a novel learning strategy involving self-attention perturbation. This strategy diversifies label assignment for positive samples across multiple query groups, thereby enriching positive supervisions. Additionally, we introduce a shared-weight decoder branch for dense positive supervision to ensure more high-quality queries matching each ground truth. Notably, all aforementioned modules are training-only. We conduct extensive experiments to demonstrate the effectiveness of our approach on COCO val2017. RT-DETRv3 significantly outperforms existing real-time detectors, including the RT-DETR series and the YOLO series. For example, RT-DETRv3-R18 achieves 48.1% AP (+1.6%/+1.4%) compared to RT-DETR-R18/RT-DETRv2-R18 while maintaining the same latency. Meanwhile, it requires only half of epochs to attain a comparable performance. Furthermore, RT-DETRv3-R101 can attain an impressive 54.6% AP outperforming YOLOv10-X. Code will be released soon.
Read more9/16/2024

0
MV-DETR: Multi-modality indoor object detection by Multi-View DEtecton TRansformers
Zichao Dong, Yilin Zhang, Xufeng Huang, Hang Ji, Zhan Shi, Xin Zhan, Junbo Chen
We introduce a novel MV-DETR pipeline which is effective while efficient transformer based detection method. Given input RGBD data, we notice that there are super strong pretraining weights for RGB data while less effective works for depth related data. First and foremost , we argue that geometry and texture cues are both of vital importance while could be encoded separately. Secondly, we find that visual texture feature is relatively hard to extract compared with geometry feature in 3d space. Unfortunately, single RGBD dataset with thousands of data is not enough for training an discriminating filter for visual texture feature extraction. Last but certainly not the least, we designed a lightweight VG module consists of a visual textual encoder, a geometry encoder and a VG connector. Compared with previous state of the art works like V-DETR, gains from pretrained visual encoder could be seen. Extensive experiments on ScanNetV2 dataset shows the effectiveness of our method. It is worth mentioned that our method achieve 78% AP which create new state of the art on ScanNetv2 benchmark.
Read more8/14/2024
0
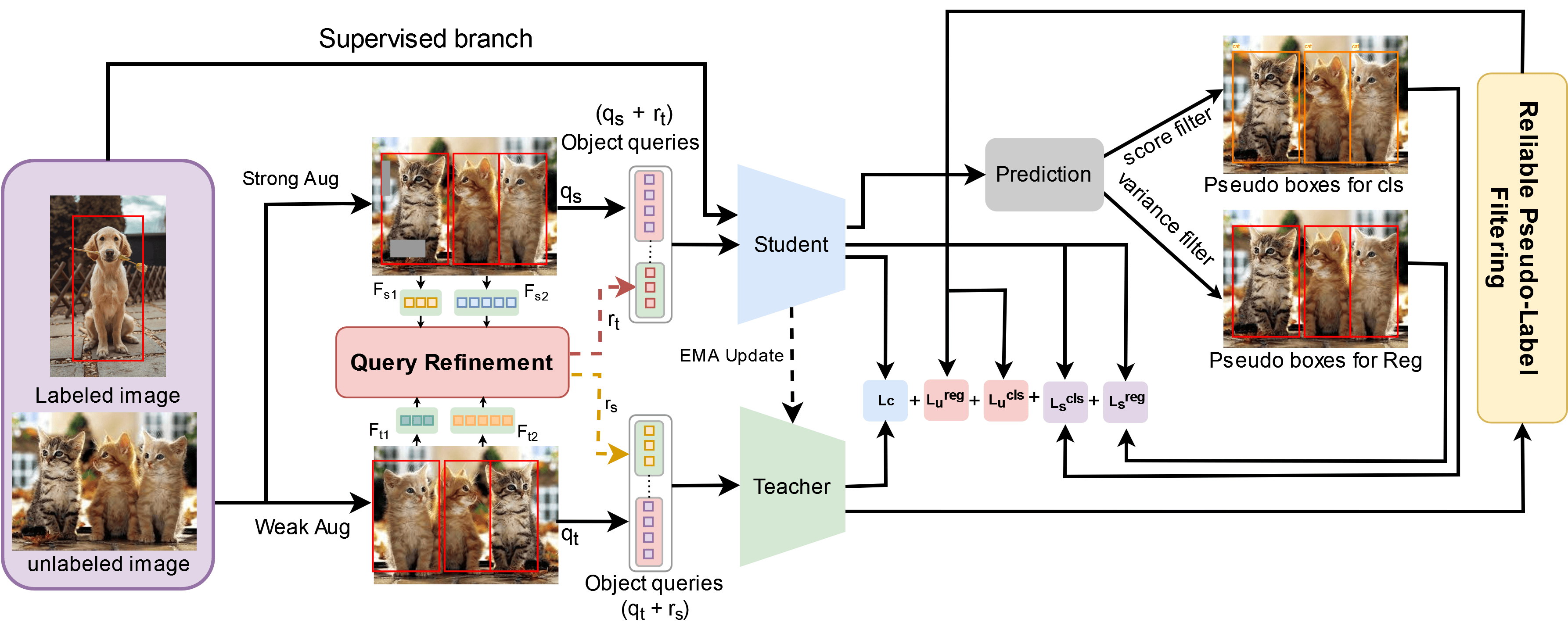
Sparse Semi-DETR: Sparse Learnable Queries for Semi-Supervised Object Detection
Tahira Shehzadi, Khurram Azeem Hashmi, Didier Stricker, Muhammad Zeshan Afzal
In this paper, we address the limitations of the DETR-based semi-supervised object detection (SSOD) framework, particularly focusing on the challenges posed by the quality of object queries. In DETR-based SSOD, the one-to-one assignment strategy provides inaccurate pseudo-labels, while the one-to-many assignments strategy leads to overlapping predictions. These issues compromise training efficiency and degrade model performance, especially in detecting small or occluded objects. We introduce Sparse Semi-DETR, a novel transformer-based, end-to-end semi-supervised object detection solution to overcome these challenges. Sparse Semi-DETR incorporates a Query Refinement Module to enhance the quality of object queries, significantly improving detection capabilities for small and partially obscured objects. Additionally, we integrate a Reliable Pseudo-Label Filtering Module that selectively filters high-quality pseudo-labels, thereby enhancing detection accuracy and consistency. On the MS-COCO and Pascal VOC object detection benchmarks, Sparse Semi-DETR achieves a significant improvement over current state-of-the-art methods that highlight Sparse Semi-DETR's effectiveness in semi-supervised object detection, particularly in challenging scenarios involving small or partially obscured objects.
Read more4/3/2024