Design Principles for Falsifiable, Replicable and Reproducible Empirical ML Research

0
Sign in to get full access
Overview
- This paper discusses design principles for conducting falsifiable, replicable, and reproducible empirical machine learning (ML) research.
- It highlights the importance of addressing the lack of reproducibility and replicability in the field of ML, which can undermine scientific progress.
- The paper proposes a set of guidelines and best practices to improve the quality and rigor of empirical ML research.
Plain English Explanation
The paper emphasizes the need for more rigorous and reliable empirical research in the field of machine learning (ML). In recent years, there has been growing concern about the lack of reproducibility and replicability in ML studies, where researchers often struggle to get the same results as previous work or fail to replicate experiments.
This is a significant problem because it can undermine the credibility of the field and hinder scientific progress. To address this issue, the authors propose a set of design principles to help researchers conduct more falsifiable, replicable, and reproducible empirical ML research.
The core idea is to introduce more transparency, standardization, and rigor into the research process. This includes clearly documenting experimental protocols, making data and code publicly available, and preregistering studies to avoid post-hoc analyses that can introduce bias.
By following these principles, the authors believe the ML community can improve the overall quality and reliability of empirical research, leading to more trustworthy scientific claims and a better understanding of the capabilities and limitations of ML systems.
Technical Explanation
The paper outlines several key design principles for conducting falsifiable, replicable, and reproducible empirical ML research:
-
Transparent Reporting: Researchers should provide detailed descriptions of their experimental protocols, including data preprocessing steps, model architectures, training procedures, and evaluation metrics. This information should be comprehensive enough to allow others to replicate the study.
-
Open Data and Code: Researchers should make their data and code publicly available, either in the paper or through a public repository. This enables others to inspect the materials used in the study and attempt to replicate the findings.
-
Preregistration: Researchers should preregister their studies, specifying their hypotheses, experimental design, and analysis plan before conducting the research. This helps to mitigate p-hacking and other forms of statistical bias.
-
Robust Evaluation: Researchers should use multiple, diverse datasets and evaluation metrics to assess the performance and generalizability of their ML models. This helps to prevent overfitting and ensure the reliability of the findings.
-
Uncertainty Quantification: Researchers should provide estimates of the uncertainty associated with their findings, such as confidence intervals or credible intervals. This allows readers to better understand the precision and reliability of the reported results.
-
Sensitivity Analysis: Researchers should conduct sensitivity analyses to understand how their results are affected by changes in experimental parameters or assumptions. This helps to identify the robustness of the findings and any potential confounding factors.
-
Negative Results: Researchers should be more willing to publish negative results, as these can be just as informative as positive findings and help to reduce publication bias.
By adopting these design principles, the authors argue that the ML research community can improve the overall quality, reliability, and credibility of empirical studies, leading to more robust and trustworthy scientific claims.
Critical Analysis
The paper makes a compelling case for the need to address the lack of reproducibility and replicability in empirical ML research. The proposed design principles are well-grounded in best practices from other scientific disciplines and could significantly improve the rigor and transparency of the research process.
However, the authors acknowledge that implementing these principles may be challenging, as they require additional time and effort from researchers, as well as a cultural shift towards more open and collaborative research practices. There may also be concerns about the feasibility of preregistering highly exploratory or iterative research, where the specific hypotheses and analysis plans may need to evolve as the study progresses.
Furthermore, the paper does not address the potential barriers to data and code sharing, such as privacy concerns, intellectual property rights, or technical challenges in preparing and curating the materials for public release. Addressing these practical considerations will be crucial for the widespread adoption of the proposed design principles.
Overall, the paper provides a well-reasoned and timely contribution to the ongoing discussion around improving the reliability and reproducibility of empirical ML research. By encouraging researchers to embrace more rigorous and transparent practices, the authors hope to strengthen the scientific foundations of the field and ultimately lead to more trustworthy and impactful discoveries.
Conclusion
This paper presents a set of design principles for conducting falsifiable, replicable, and reproducible empirical research in the field of machine learning. The authors argue that addressing the lack of reproducibility and replicability in ML studies is crucial for improving the credibility and progress of the field.
By promoting transparency, open data and code, preregistration, robust evaluation, and other best practices, the authors believe the ML community can produce more reliable and trustworthy scientific claims. While implementing these principles may pose practical challenges, the potential benefits in terms of enhancing the quality and credibility of empirical ML research are substantial.
Overall, this paper provides a valuable roadmap for researchers, journal editors, and funding agencies to help drive the field of ML towards more rigorous, transparent, and reproducible empirical practices, ultimately leading to more robust and impactful scientific discoveries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Design Principles for Falsifiable, Replicable and Reproducible Empirical ML Research
Daniel Vranjev{s}, Oliver Niggemann
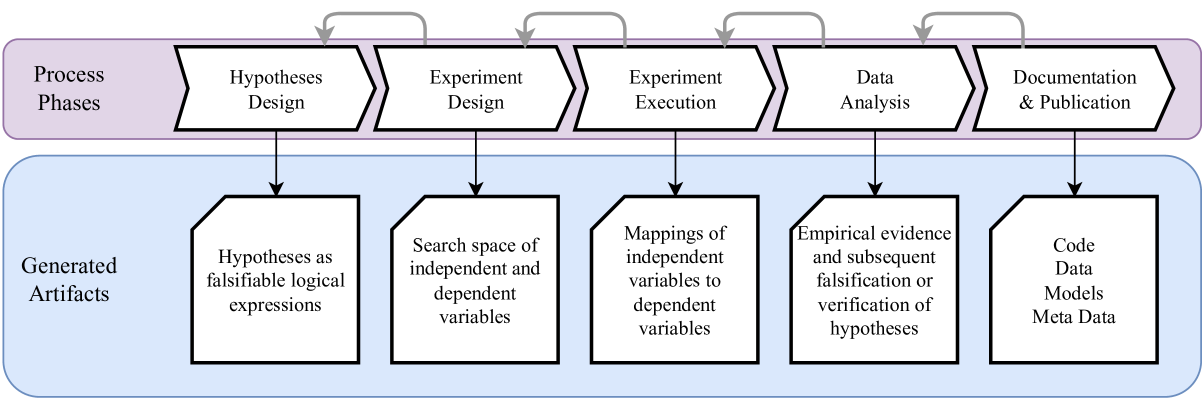
Empirical research plays a fundamental role in the machine learning domain. At the heart of impactful empirical research lies the development of clear research hypotheses, which then shape the design of experiments. The execution of experiments must be carried out with precision to ensure reliable results, followed by statistical analysis to interpret these outcomes. This process is key to either supporting or refuting initial hypotheses. Despite its importance, there is a high variability in research practices across the machine learning community and no uniform understanding of quality criteria for empirical research. To address this gap, we propose a model for the empirical research process, accompanied by guidelines to uphold the validity of empirical research. By embracing these recommendations, greater consistency, enhanced reliability and increased impact can be achieved.
Read more5/29/2024
✅
0
Position Paper: Rethinking Empirical Research in Machine Learning: Addressing Epistemic and Methodological Challenges of Experimentation
Moritz Herrmann, F. Julian D. Lange, Katharina Eggensperger, Giuseppe Casalicchio, Marcel Wever, Matthias Feurer, David Rugamer, Eyke Hullermeier, Anne-Laure Boulesteix, Bernd Bischl
We warn against a common but incomplete understanding of empirical research in machine learning that leads to non-replicable results, makes findings unreliable, and threatens to undermine progress in the field. To overcome this alarming situation, we call for more awareness of the plurality of ways of gaining knowledge experimentally but also of some epistemic limitations. In particular, we argue most current empirical machine learning research is fashioned as confirmatory research while it should rather be considered exploratory.
Read more5/28/2024
0
What is Reproducibility in Artificial Intelligence and Machine Learning Research?
Abhyuday Desai, Mohamed Abdelhamid, Nakul R. Padalkar
In the rapidly evolving fields of Artificial Intelligence (AI) and Machine Learning (ML), the reproducibility crisis underscores the urgent need for clear validation methodologies to maintain scientific integrity and encourage advancement. The crisis is compounded by the prevalent confusion over validation terminology. Responding to this challenge, we introduce a validation framework that clarifies the roles and definitions of key validation efforts: repeatability, dependent and independent reproducibility, and direct and conceptual replicability. This structured framework aims to provide AI/ML researchers with the necessary clarity on these essential concepts, facilitating the appropriate design, conduct, and interpretation of validation studies. By articulating the nuances and specific roles of each type of validation study, we hope to contribute to a more informed and methodical approach to addressing the challenges of reproducibility, thereby supporting the community's efforts to enhance the reliability and trustworthiness of its research findings.
Read more7/16/2024
✨
0
Between Randomness and Arbitrariness: Some Lessons for Reliable Machine Learning at Scale
A. Feder Cooper
To develop rigorous knowledge about ML models -- and the systems in which they are embedded -- we need reliable measurements. But reliable measurement is fundamentally challenging, and touches on issues of reproducibility, scalability, uncertainty quantification, epistemology, and more. This dissertation addresses criteria needed to take reliability seriously: both criteria for designing meaningful metrics, and for methodologies that ensure that we can dependably and efficiently measure these metrics at scale and in practice. In doing so, this dissertation articulates a research vision for a new field of scholarship at the intersection of machine learning, law, and policy. Within this frame, we cover topics that fit under three different themes: (1) quantifying and mitigating sources of arbitrariness in ML, (2) taming randomness in uncertainty estimation and optimization algorithms, in order to achieve scalability without sacrificing reliability, and (3) providing methods for evaluating generative-AI systems, with specific focuses on quantifying memorization in language models and training latent diffusion models on open-licensed data. By making contributions in these three themes, this dissertation serves as an empirical proof by example that research on reliable measurement for machine learning is intimately and inescapably bound up with research in law and policy. These different disciplines pose similar research questions about reliable measurement in machine learning. They are, in fact, two complementary sides of the same research vision, which, broadly construed, aims to construct machine-learning systems that cohere with broader societal values.
Read more8/13/2024