Position Paper: Rethinking Empirical Research in Machine Learning: Addressing Epistemic and Methodological Challenges of Experimentation

0
✅
Sign in to get full access
Overview
- The paper warns against a common but incomplete understanding of empirical research in machine learning (ML) that leads to non-replicable results, unreliable findings, and threatens to undermine progress in the field.
- The authors call for more awareness of the plurality of ways of gaining knowledge experimentally, as well as some epistemic limitations.
- They argue that most current empirical ML research is considered confirmatory, when it should rather be viewed as exploratory.
Plain English Explanation
The paper highlights an important issue in machine learning (ML) research. Oftentimes, ML studies are designed and reported in a way that makes it difficult to reproduce the results. This undermines the reliability of the findings and can slow down progress in the field.
The authors argue that researchers need to be more aware of the different ways that knowledge can be gained through experiments. They also need to recognize the limitations of what can be learned from these experiments.
A key point the authors make is that most current ML research is set up to confirm pre-existing ideas, rather than explore new territory. This "confirmatory" approach can lead to biased or incomplete conclusions. Instead, the authors suggest that ML research should be approached more as an "exploratory" process, where researchers are open to discovering unexpected insights.
By addressing these concerns, the authors hope to improve the quality and impact of ML research, leading to more robust and meaningful advancements in the field. This relates to work on topics like double machine learning approaches to combining experimental evidence, moving from model performance to substantive claims, and challenges in deploying ML models in the real world.
Technical Explanation
The paper argues that a common but incomplete understanding of empirical research in machine learning (ML) has led to issues with non-replicable results and unreliable findings. The authors call for greater awareness of the different ways knowledge can be gained experimentally, as well as the limitations of these approaches.
A key point is that most current empirical ML research is framed as confirmatory, aiming to validate pre-existing hypotheses. However, the authors suggest this work should instead be viewed as exploratory, where the goal is to discover new insights rather than prove existing ones.
The paper discusses how the confirmatory mindset can lead to biased conclusions and undermine the progress of the ML field. The authors propose that researchers need to be more cognizant of the epistemological assumptions underlying their work, and consider alternative experimental frameworks like those used in knowledge-guided machine learning.
Additionally, the paper raises concerns about the way ML model evaluations are often reported, noting how they can be misleading. The authors argue that a shift towards more exploratory, pluralistic approaches to empirical research could help address these issues and strengthen the foundations of ML as a field.
Critical Analysis
The paper makes a compelling case for the need to re-examine common practices in empirical ML research. The authors rightly point out how the predominant confirmatory mindset can lead to non-replicable results and questionable conclusions.
One limitation of the paper is that it does not provide detailed examples or case studies to illustrate the specific problems it identifies. While the arguments are logical, more concrete evidence from the literature could strengthen the authors' claims.
Additionally, the paper does not delve deeply into the practical challenges of transitioning towards a more exploratory research paradigm. Implementing such a shift would likely require significant changes to how ML studies are designed, conducted, and reported. The authors could have explored some of these implementation hurdles in greater detail.
That said, the core message of the paper is an important one. As machine learning continues to advance and have greater societal impact, it is crucial that the underlying research be as rigorous and reliable as possible. By encouraging a more pluralistic, open-minded approach to empirical work, the authors hope to put the field on a stronger footing for the future.
Overall, this paper serves as a valuable critique and call-to-action for the ML community. Readers are encouraged to think critically about their own research practices and consider how they might contribute to building a more robust, trustworthy discipline.
Conclusion
This paper highlights a serious issue in the current state of empirical research in machine learning. The authors argue that a prevalent confirmatory mindset, combined with incomplete understanding of experimental methods, has led to non-replicable results and unreliable findings that threaten to undermine progress in the field.
To address this problem, the authors call for greater awareness of the diverse ways knowledge can be gained through experimentation, as well as the inherent limitations of these approaches. They emphasize the need to shift away from a confirmatory research paradigm and towards a more exploratory, open-minded perspective.
Implementing such a shift would likely require significant changes to how ML studies are designed, conducted, and reported. But by doing so, the authors believe the field can build a stronger, more rigorous foundation that will enable more trustworthy and impactful advancements in the years to come.
This paper's critical analysis of current practices in empirical ML research is an important contribution that deserves careful consideration by researchers and practitioners alike. Only by confronting these issues head-on can the machine learning community ensure the long-term validity and reliability of its work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
0
Position Paper: Rethinking Empirical Research in Machine Learning: Addressing Epistemic and Methodological Challenges of Experimentation
Moritz Herrmann, F. Julian D. Lange, Katharina Eggensperger, Giuseppe Casalicchio, Marcel Wever, Matthias Feurer, David Rugamer, Eyke Hullermeier, Anne-Laure Boulesteix, Bernd Bischl
We warn against a common but incomplete understanding of empirical research in machine learning that leads to non-replicable results, makes findings unreliable, and threatens to undermine progress in the field. To overcome this alarming situation, we call for more awareness of the plurality of ways of gaining knowledge experimentally but also of some epistemic limitations. In particular, we argue most current empirical machine learning research is fashioned as confirmatory research while it should rather be considered exploratory.
Read more5/28/2024
0
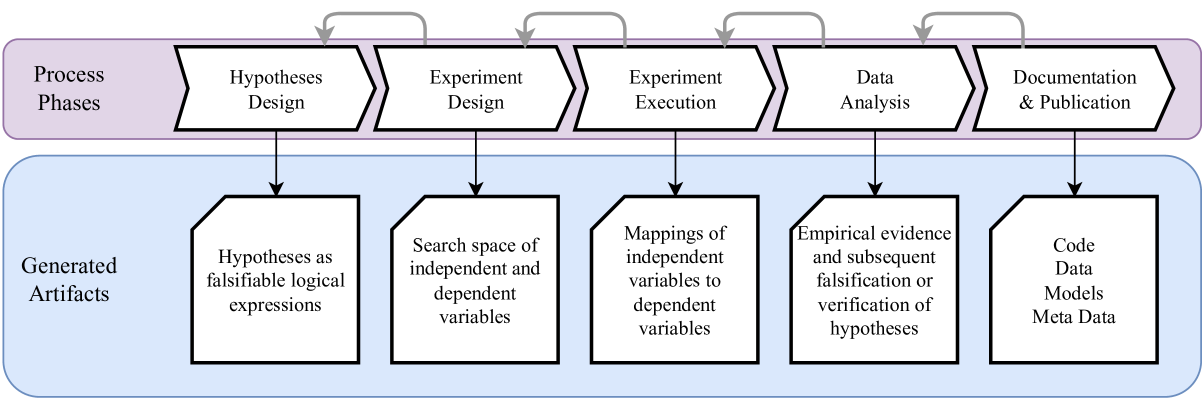
Design Principles for Falsifiable, Replicable and Reproducible Empirical ML Research
Daniel Vranjev{s}, Oliver Niggemann
Empirical research plays a fundamental role in the machine learning domain. At the heart of impactful empirical research lies the development of clear research hypotheses, which then shape the design of experiments. The execution of experiments must be carried out with precision to ensure reliable results, followed by statistical analysis to interpret these outcomes. This process is key to either supporting or refuting initial hypotheses. Despite its importance, there is a high variability in research practices across the machine learning community and no uniform understanding of quality criteria for empirical research. To address this gap, we propose a model for the empirical research process, accompanied by guidelines to uphold the validity of empirical research. By embracing these recommendations, greater consistency, enhanced reliability and increased impact can be achieved.
Read more5/29/2024
0
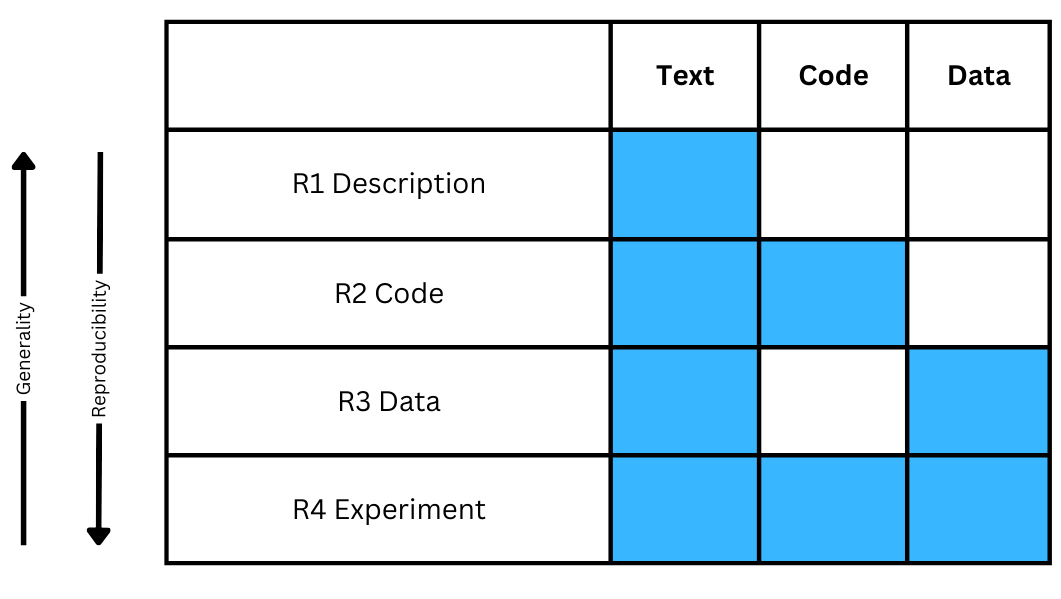
Reproducibility in Machine Learning-based Research: Overview, Barriers and Drivers
Harald Semmelrock, Tony Ross-Hellauer, Simone Kopeinik, Dieter Theiler, Armin Haberl, Stefan Thalmann, Dominik Kowald
Research in various fields is currently experiencing challenges regarding the reproducibility of results. This problem is also prevalent in machine learning (ML) research. The issue arises primarily due to unpublished data and/or source code and the sensitivity of ML training conditions. Although different solutions have been proposed to address this issue, such as using ML platforms, the level of reproducibility in ML-driven research remains unsatisfactory. Therefore, in this article, we discuss the reproducibility of ML-driven research with three main aims: (i) identify the barriers to reproducibility when applying ML in research as well as categorize the barriers to different types of reproducibility (description, code, data, and experiment reproducibility), (ii) identify potential drivers such as tools, practices, and interventions that support ML reproducibility as well as distinguish between technology-driven drivers, procedural drivers, and drivers related to awareness and education, and (iii) map the drivers to the barriers. With this work, we hope to provide insights and contribute to the decision-making process regarding the adoption of different solutions to support ML reproducibility.
Read more6/21/2024
↗️
0
Information-Theoretic Foundations for Machine Learning
Hong Jun Jeon, Benjamin Van Roy
The staggering progress of machine learning in the past decade has been a sight to behold. In retrospect, it is both remarkable and unsettling that these milestones were achievable with little to no rigorous theory to guide experimentation. Despite this fact, practitioners have been able to guide their future experimentation via observations from previous large-scale empirical investigations. However, alluding to Plato's Allegory of the cave, it is likely that the observations which form the field's notion of reality are but shadows representing fragments of that reality. In this work, we propose a theoretical framework which attempts to answer what exists outside of the cave. To the theorist, we provide a framework which is mathematically rigorous and leaves open many interesting ideas for future exploration. To the practitioner, we provide a framework whose results are very intuitive, general, and which will help form principles to guide future investigations. Concretely, we provide a theoretical framework rooted in Bayesian statistics and Shannon's information theory which is general enough to unify the analysis of many phenomena in machine learning. Our framework characterizes the performance of an optimal Bayesian learner, which considers the fundamental limits of information. Throughout this work, we derive very general theoretical results and apply them to derive insights specific to settings ranging from data which is independently and identically distributed under an unknown distribution, to data which is sequential, to data which exhibits hierarchical structure amenable to meta-learning. We conclude with a section dedicated to characterizing the performance of misspecified algorithms. These results are exciting and particularly relevant as we strive to overcome increasingly difficult machine learning challenges in this endlessly complex world.
Read more8/21/2024