DesignProbe: A Graphic Design Benchmark for Multimodal Large Language Models
2404.14801
0
0
💬
Abstract
A well-executed graphic design typically achieves harmony in two levels, from the fine-grained design elements (color, font and layout) to the overall design. This complexity makes the comprehension of graphic design challenging, for it needs the capability to both recognize the design elements and understand the design. With the rapid development of Multimodal Large Language Models (MLLMs), we establish the DesignProbe, a benchmark to investigate the capability of MLLMs in design. Our benchmark includes eight tasks in total, across both the fine-grained element level and the overall design level. At design element level, we consider both the attribute recognition and semantic understanding tasks. At overall design level, we include style and metaphor. 9 MLLMs are tested and we apply GPT-4 as evaluator. Besides, further experiments indicates that refining prompts can enhance the performance of MLLMs. We first rewrite the prompts by different LLMs and found increased performances appear in those who self-refined by their own LLMs. We then add extra task knowledge in two different ways (text descriptions and image examples), finding that adding images boost much more performance over texts.
Create account to get full access
Overview
- This paper investigates the capability of Multimodal Large Language Models (MLLMs) in understanding and analyzing graphic design.
- The researchers establish the DesignProbe benchmark, which includes eight tasks across fine-grained design elements and overall design.
- The benchmark tests 9 MLLMs, with GPT-4 used as the evaluator.
- The paper also explores how refining prompts and adding task-specific knowledge can enhance the performance of MLLMs on design-related tasks.
Plain English Explanation
Graphic design is a complex field that requires the ability to recognize individual design elements like color, font, and layout, as well as understand the overall design concept. With the rapid advancement of Multimodal Large Language Models (MLLMs), the researchers wanted to investigate how well these models can handle design-related tasks.
To do this, they created the DesignProbe benchmark, which includes a variety of tasks at both the fine-grained element level (like identifying color or font attributes) and the overall design level (like understanding design style or metaphor). They tested 9 different MLLMs, using the powerful GPT-4 model as the evaluator.
The researchers also found that refining the prompts used to give instructions to the MLLMs, and providing additional task-specific knowledge (either in the form of text descriptions or image examples), can significantly boost the models' performance on design-related tasks. This suggests that with the right prompts and supporting information, these language models can become more adept at understanding and analyzing graphic design.
Technical Explanation
The paper establishes the DesignProbe benchmark to evaluate the capabilities of Multimodal Large Language Models (MLLMs) in design-related tasks. The benchmark includes eight tasks, divided into two categories: fine-grained design elements (attribute recognition and semantic understanding) and overall design (style and metaphor).
The researchers tested 9 different MLLMs on the DesignProbe, using the GPT-4 model as the evaluator. They found that the performance of these models could be enhanced by refining the prompts used to give instructions. Specifically, they observed that MLLMs performed better on tasks when the prompts were rewritten by the models themselves, rather than by external sources.
Additionally, the paper explores the impact of providing task-specific knowledge to the MLLMs. They found that adding image examples to the prompts resulted in a much larger performance boost compared to adding text-based descriptions. This suggests that visual information is particularly helpful for these models when tackling design-related tasks.
Critical Analysis
The paper provides a comprehensive and well-designed benchmark for evaluating the capabilities of MLLMs in the domain of graphic design. The DesignProbe covers a range of tasks that are relevant to both fine-grained design elements and overall design concepts, allowing for a thorough assessment of the models' capabilities.
One potential limitation of the research is the relatively small sample size of 9 MLLMs tested. While this provides a good starting point, expanding the study to include a larger and more diverse set of models could yield additional insights and strengthen the generalizability of the findings.
Additionally, the paper does not delve deeply into the specific architectures or training approaches of the tested MLLMs. Understanding how these factors might contribute to the models' performance on design-related tasks could provide valuable insights for future model development and refinement.
Finally, the paper focuses on the technical aspects of the benchmark and the model evaluations, but does not extensively discuss the potential real-world implications or applications of this research. Exploring how these findings could impact the design industry, education, or other relevant domains could enhance the practical relevance of the study.
Conclusion
This paper presents a novel benchmark, DesignProbe, for evaluating the capabilities of Multimodal Large Language Models in the domain of graphic design. The findings suggest that with the right prompts and supporting information, these models can become more adept at understanding and analyzing design elements and overall design concepts.
The insights gained from this research could have important implications for the development of more capable and versatile design tools, as well as for the integration of AI-powered design analysis and critique into various industries and educational settings. As Multimodal Large Language Models continue to evolve, the DesignProbe benchmark provides a valuable framework for assessing their progress and identifying areas for further improvement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DesignQA: A Multimodal Benchmark for Evaluating Large Language Models' Understanding of Engineering Documentation
Anna C. Doris, Daniele Grandi, Ryan Tomich, Md Ferdous Alam, Hyunmin Cheong, Faez Ahmed
0
0
This research introduces DesignQA, a novel benchmark aimed at evaluating the proficiency of multimodal large language models (MLLMs) in comprehending and applying engineering requirements in technical documentation. Developed with a focus on real-world engineering challenges, DesignQA uniquely combines multimodal data-including textual design requirements, CAD images, and engineering drawings-derived from the Formula SAE student competition. Different from many existing MLLM benchmarks, DesignQA contains document-grounded visual questions where the input image and input document come from different sources. The benchmark features automatic evaluation metrics and is divided into segments-Rule Comprehension, Rule Compliance, and Rule Extraction-based on tasks that engineers perform when designing according to requirements. We evaluate state-of-the-art models like GPT4 and LLaVA against the benchmark, and our study uncovers the existing gaps in MLLMs' abilities to interpret complex engineering documentation. Key findings suggest that while MLLMs demonstrate potential in navigating technical documents, substantial limitations exist, particularly in accurately extracting and applying detailed requirements to engineering designs. This benchmark sets a foundation for future advancements in AI-supported engineering design processes. DesignQA is publicly available at: https://github.com/anniedoris/design_qa/.
4/12/2024
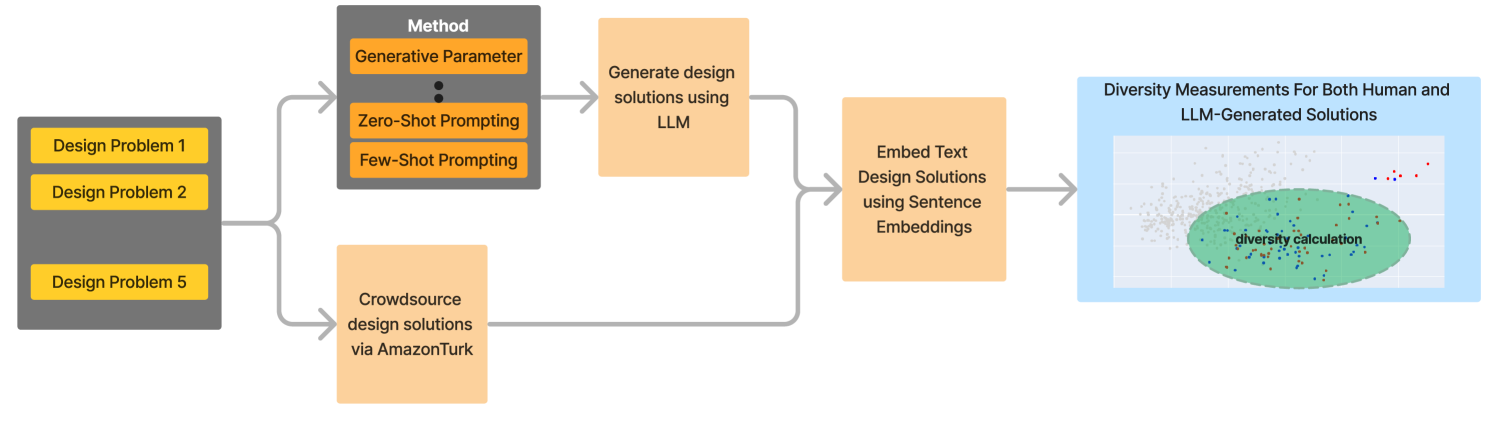
Exploring the Capabilities of Large Language Models for Generating Diverse Design Solutions
Kevin Ma, Daniele Grandi, Christopher McComb, Kosa Goucher-Lambert
0
0
Access to large amounts of diverse design solutions can support designers during the early stage of the design process. In this paper, we explore the efficacy of large language models (LLM) in producing diverse design solutions, investigating the level of impact that parameter tuning and various prompt engineering techniques can have on the diversity of LLM-generated design solutions. Specifically, LLMs are used to generate a total of 4,000 design solutions across five distinct design topics, eight combinations of parameters, and eight different types of prompt engineering techniques, comparing each combination of parameter and prompt engineering method across four different diversity metrics. LLM-generated solutions are compared against 100 human-crowdsourced solutions in each design topic using the same set of diversity metrics. Results indicate that human-generated solutions consistently have greater diversity scores across all design topics. Using a post hoc logistic regression analysis we investigate whether these differences primarily exist at the semantic level. Results show that there is a divide in some design topics between humans and LLM-generated solutions, while others have no clear divide. Taken together, these results contribute to the understanding of LLMs' capabilities in generating a large volume of diverse design solutions and offer insights for future research that leverages LLMs to generate diverse design solutions for a broad range of design tasks (e.g., inspirational stimuli).
5/7/2024
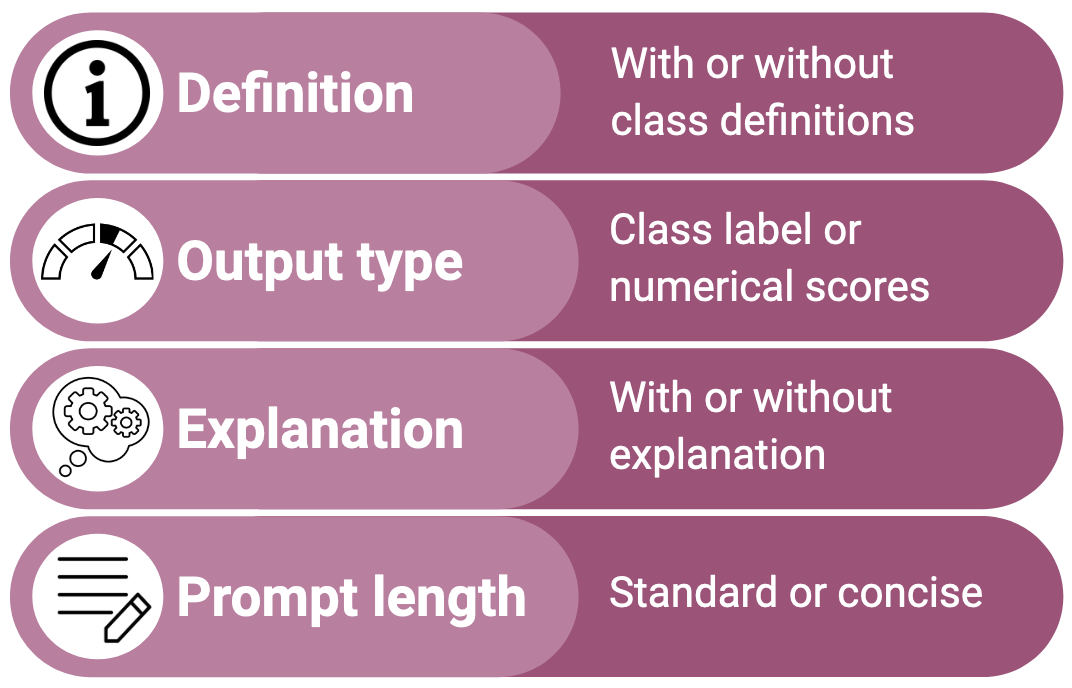
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
0
0
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
6/19/2024
🤔
Probing Conceptual Understanding of Large Visual-Language Models
Madeline Schiappa, Raiyaan Abdullah, Shehreen Azad, Jared Claypoole, Michael Cogswell, Ajay Divakaran, Yogesh Rawat
0
0
In recent years large visual-language (V+L) models have achieved great success in various downstream tasks. However, it is not well studied whether these models have a conceptual grasp of the visual content. In this work we focus on conceptual understanding of these large V+L models. To facilitate this study, we propose novel benchmarking datasets for probing three different aspects of content understanding, 1) textit{relations}, 2) textit{composition}, and 3) textit{context}. Our probes are grounded in cognitive science and help determine if a V+L model can, for example, determine if snow garnished with a man is implausible, or if it can identify beach furniture by knowing it is located on a beach. We experimented with many recent state-of-the-art V+L models and observe that these models mostly textit{fail to demonstrate} a conceptual understanding. This study reveals several interesting insights such as that textit{cross-attention} helps learning conceptual understanding, and that CNNs are better with textit{texture and patterns}, while Transformers are better at textit{color and shape}. We further utilize some of these insights and investigate a textit{simple finetuning technique} that rewards the three conceptual understanding measures with promising initial results. The proposed benchmarks will drive the community to delve deeper into conceptual understanding and foster advancements in the capabilities of large V+L models. The code and dataset is available at: url{https://tinyurl.com/vlm-robustness}
4/29/2024