DesignQA: A Multimodal Benchmark for Evaluating Large Language Models' Understanding of Engineering Documentation
2404.07917
0
0

Abstract
This research introduces DesignQA, a novel benchmark aimed at evaluating the proficiency of multimodal large language models (MLLMs) in comprehending and applying engineering requirements in technical documentation. Developed with a focus on real-world engineering challenges, DesignQA uniquely combines multimodal data-including textual design requirements, CAD images, and engineering drawings-derived from the Formula SAE student competition. Different from many existing MLLM benchmarks, DesignQA contains document-grounded visual questions where the input image and input document come from different sources. The benchmark features automatic evaluation metrics and is divided into segments-Rule Comprehension, Rule Compliance, and Rule Extraction-based on tasks that engineers perform when designing according to requirements. We evaluate state-of-the-art models like GPT4 and LLaVA against the benchmark, and our study uncovers the existing gaps in MLLMs' abilities to interpret complex engineering documentation. Key findings suggest that while MLLMs demonstrate potential in navigating technical documents, substantial limitations exist, particularly in accurately extracting and applying detailed requirements to engineering designs. This benchmark sets a foundation for future advancements in AI-supported engineering design processes. DesignQA is publicly available at: https://github.com/anniedoris/design_qa/.
Create account to get full access
Overview
- The paper "DesignQA: A Multimodal Benchmark for Evaluating Large Language Models' Understanding of Engineering Documentation" introduces a new benchmark dataset for assessing how well large language models can understand and reason about engineering documentation.
- The dataset includes a diverse collection of engineering diagrams, schematics, and associated textual descriptions, along with question-answer pairs that require a deep understanding of the visual and textual information to solve.
- By evaluating language models on this benchmark, the researchers aim to gain insights into the models' capabilities in comprehending and reasoning about multimodal engineering-related content, which is crucial for applications such as technical support, design assistance, and autonomous systems.
Plain English Explanation
The paper presents a new benchmark called DesignQA that is designed to test how well large language models can understand engineering-related information. The benchmark consists of a collection of engineering diagrams, schematics, and associated text descriptions, along with questions about the content that require both visual and textual understanding to answer correctly.
By evaluating language models on this benchmark, the researchers hope to gain insights into the models' abilities to comprehend and reason about multimodal engineering information. This is important for applications such as providing technical support, assisting with design tasks, and developing autonomous systems that need to understand engineering-related content.
The key idea is that language models need to be able to process and integrate both visual and textual information to truly understand engineering documentation, which is often presented in a multimodal format. The DesignQA benchmark provides a way to assess how well these models can handle this type of complex, real-world information.
Technical Explanation
The DesignQA benchmark is composed of a diverse collection of engineering diagrams, schematics, and associated textual descriptions, along with question-answer pairs that require a deep understanding of the visual and textual information to solve. The dataset was curated from various online engineering resources, such as technical manuals and product documentation.
The researchers designed the benchmark to assess large language models' capabilities in comprehending and reasoning about multimodal engineering-related content. To this end, the question-answer pairs in DesignQA are structured to test the models' ability to integrate visual and textual information, understand technical concepts, and apply logical reasoning to answer questions correctly.
The benchmark is intended to serve as a valuable tool for researchers and developers working on multimodal language models and their applications in engineering-related domains. By evaluating language models on DesignQA, the researchers aim to gain insights into the models' strengths, weaknesses, and potential areas for improvement in understanding and reasoning about engineering documentation.
Critical Analysis
The DesignQA benchmark represents a significant step forward in evaluating large language models' understanding of multimodal engineering-related content. By focusing on the integration of visual and textual information, the benchmark addresses an important gap in the current landscape of language model evaluation, which has traditionally been more text-centric.
One potential limitation of the benchmark is the scope of the engineering domains covered. While the dataset includes a diverse range of engineering topics, it may not fully capture the breadth and complexity of real-world engineering documentation. Additionally, the benchmark's reliance on existing online resources may introduce biases or inconsistencies in the data.
Further research could explore expanding the DesignQA dataset to include a wider range of engineering disciplines, as well as investigating the generalization of language models' performance across different types of engineering documentation. Assessing the models' ability to handle novel, unseen engineering content could also provide valuable insights.
Conclusion
The DesignQA benchmark introduced in this paper represents a significant advancement in the evaluation of large language models' understanding of engineering documentation. By incorporating both visual and textual information, the benchmark challenges language models to integrate multimodal cues and apply logical reasoning to answer questions correctly.
The results of evaluating language models on DesignQA could have important implications for the development of intelligent systems that need to understand and reason about engineering-related content, such as technical support chatbots, design assistance tools, and autonomous systems that operate in engineering-focused environments. By identifying strengths and weaknesses in language models' multimodal understanding, the DesignQA benchmark can help guide future research and development in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
DesignProbe: A Graphic Design Benchmark for Multimodal Large Language Models
Jieru Lin, Danqing Huang, Tiejun Zhao, Dechen Zhan, Chin-Yew Lin
0
0
A well-executed graphic design typically achieves harmony in two levels, from the fine-grained design elements (color, font and layout) to the overall design. This complexity makes the comprehension of graphic design challenging, for it needs the capability to both recognize the design elements and understand the design. With the rapid development of Multimodal Large Language Models (MLLMs), we establish the DesignProbe, a benchmark to investigate the capability of MLLMs in design. Our benchmark includes eight tasks in total, across both the fine-grained element level and the overall design level. At design element level, we consider both the attribute recognition and semantic understanding tasks. At overall design level, we include style and metaphor. 9 MLLMs are tested and we apply GPT-4 as evaluator. Besides, further experiments indicates that refining prompts can enhance the performance of MLLMs. We first rewrite the prompts by different LLMs and found increased performances appear in those who self-refined by their own LLMs. We then add extra task knowledge in two different ways (text descriptions and image examples), finding that adding images boost much more performance over texts.
4/24/2024
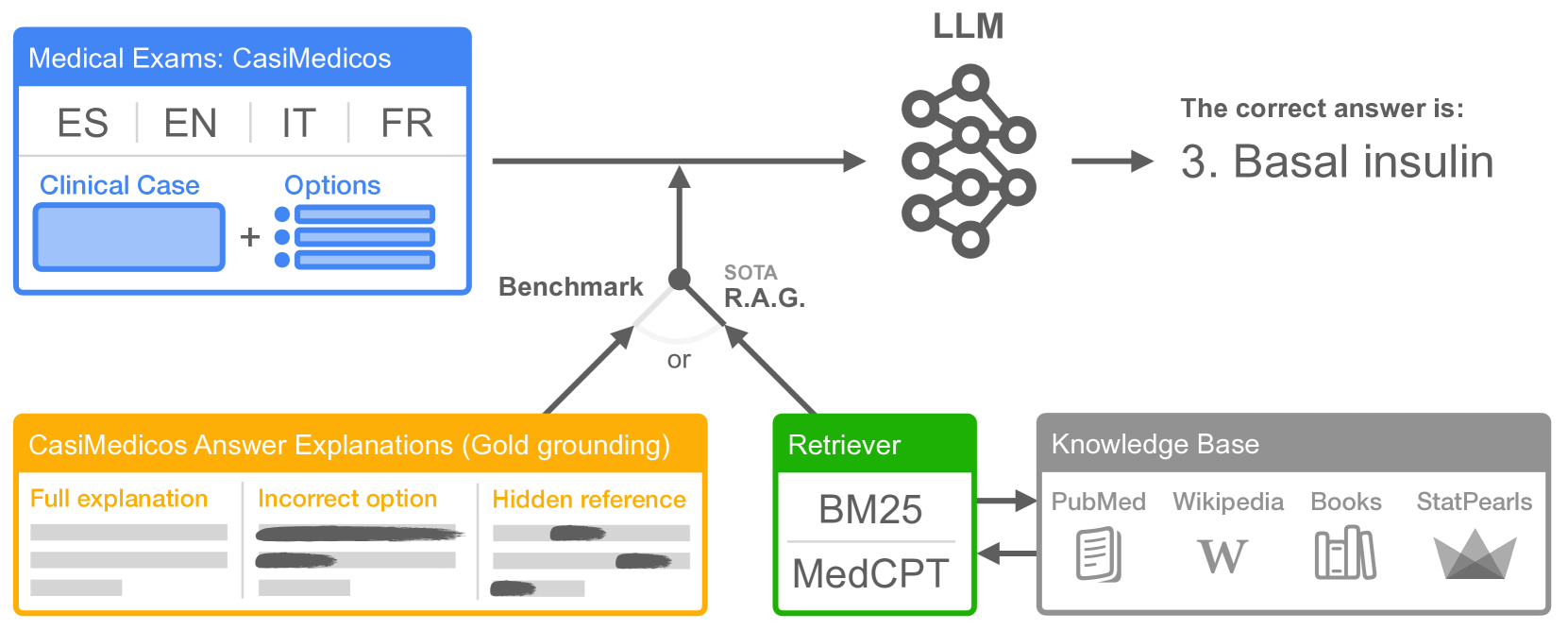
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
I~nigo Alonso, Maite Oronoz, Rodrigo Agerri
0
0
Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
4/9/2024
💬
LibriSQA: A Novel Dataset and Framework for Spoken Question Answering with Large Language Models
Zihan Zhao, Yiyang Jiang, Heyang Liu, Yanfeng Wang, Yu Wang
0
0
While Large Language Models (LLMs) have demonstrated commendable performance across a myriad of domains and tasks, existing LLMs still exhibit a palpable deficit in handling multimodal functionalities, especially for the Spoken Question Answering (SQA) task which necessitates precise alignment and deep interaction between speech and text features. To address the SQA challenge on LLMs, we initially curated the free-form and open-ended LibriSQA dataset from Librispeech, comprising Part I with natural conversational formats and Part II encompassing multiple-choice questions followed by answers and analytical segments. Both parts collectively include 107k SQA pairs that cover various topics. Given the evident paucity of existing speech-text LLMs, we propose a lightweight, end-to-end framework to execute the SQA task on the LibriSQA, witnessing significant results. By reforming ASR into the SQA format, we further substantiate our framework's capability in handling ASR tasks. Our empirical findings bolster the LLMs' aptitude for aligning and comprehending multimodal information, paving the way for the development of universal multimodal LLMs. The dataset and demo can be found at https://github.com/ZihanZhaoSJTU/LibriSQA.
4/19/2024

SportQA: A Benchmark for Sports Understanding in Large Language Models
Haotian Xia, Zhengbang Yang, Yuqing Wang, Rhys Tracy, Yun Zhao, Dongdong Huang, Zezhi Chen, Yan Zhu, Yuan-fang Wang, Weining Shen
0
0
A deep understanding of sports, a field rich in strategic and dynamic content, is crucial for advancing Natural Language Processing (NLP). This holds particular significance in the context of evaluating and advancing Large Language Models (LLMs), given the existing gap in specialized benchmarks. To bridge this gap, we introduce SportQA, a novel benchmark specifically designed for evaluating LLMs in the context of sports understanding. SportQA encompasses over 70,000 multiple-choice questions across three distinct difficulty levels, each targeting different aspects of sports knowledge from basic historical facts to intricate, scenario-based reasoning tasks. We conducted a thorough evaluation of prevalent LLMs, mainly utilizing few-shot learning paradigms supplemented by chain-of-thought (CoT) prompting. Our results reveal that while LLMs exhibit competent performance in basic sports knowledge, they struggle with more complex, scenario-based sports reasoning, lagging behind human expertise. The introduction of SportQA marks a significant step forward in NLP, offering a tool for assessing and enhancing sports understanding in LLMs.
6/19/2024