Probing Conceptual Understanding of Large Visual-Language Models
2304.03659
0
0
🤔
Abstract
In recent years large visual-language (V+L) models have achieved great success in various downstream tasks. However, it is not well studied whether these models have a conceptual grasp of the visual content. In this work we focus on conceptual understanding of these large V+L models. To facilitate this study, we propose novel benchmarking datasets for probing three different aspects of content understanding, 1) textit{relations}, 2) textit{composition}, and 3) textit{context}. Our probes are grounded in cognitive science and help determine if a V+L model can, for example, determine if snow garnished with a man is implausible, or if it can identify beach furniture by knowing it is located on a beach. We experimented with many recent state-of-the-art V+L models and observe that these models mostly textit{fail to demonstrate} a conceptual understanding. This study reveals several interesting insights such as that textit{cross-attention} helps learning conceptual understanding, and that CNNs are better with textit{texture and patterns}, while Transformers are better at textit{color and shape}. We further utilize some of these insights and investigate a textit{simple finetuning technique} that rewards the three conceptual understanding measures with promising initial results. The proposed benchmarks will drive the community to delve deeper into conceptual understanding and foster advancements in the capabilities of large V+L models. The code and dataset is available at: url{https://tinyurl.com/vlm-robustness}
Create account to get full access
Overview
- Large visual-language (V+L) models have achieved significant success in various tasks, but their conceptual understanding of visual content is not well studied.
- This research proposes novel benchmarking datasets to probe three aspects of content understanding: relations, composition, and context.
- The study reveals that current state-of-the-art V+L models mostly fail to demonstrate a conceptual understanding of the visual content.
- The researchers also investigate a simple fine-tuning technique that rewards the three conceptual understanding measures, with promising initial results.
Plain English Explanation
Large language and vision models have become very good at tasks like image captioning and visual question answering. However, it's not clear if these models truly understand the conceptual meaning of the visual content they're working with.
To explore this, the researchers created new test datasets that probe different aspects of conceptual understanding. For example, one dataset checks if a model can identify implausible visual scenes, like snow garnished with a person. Another dataset sees if a model can recognize beach furniture by knowing it's located on a beach.
When the researchers tested many state-of-the-art language and vision models on these new benchmarks, they found the models generally failed to demonstrate a deep conceptual understanding. The models seemed to rely more on superficial patterns than truly grasping the meaning behind the images.
However, the study also found some promising insights. For instance, the models that used "cross-attention" between the language and vision components seemed to do better at conceptual understanding. The researchers also observed that convolutional neural networks (CNNs) were better at understanding texture and patterns, while transformer models were stronger at color and shape.
Building on these findings, the researchers experimented with a simple fine-tuning technique that rewarded the models for performing well on the conceptual understanding benchmarks. This showed some initial success, suggesting a path forward for developing language and vision models with more robust conceptual abilities.
Technical Explanation
The researchers designed novel benchmarking datasets to probe three key aspects of conceptual understanding in large visual-language (V+L) models:
- Relations: Assessing whether a model can detect implausible or nonsensical visual relationships, like a man garnishing snow.
- Composition: Evaluating if a model can recognize objects by their contextual cues, like identifying beach furniture based on its location.
- Context: Determining if a model can understand the broader situational and semantic context of visual scenes.
The researchers experimented with multiple state-of-the-art V+L models, including those based on convolutional neural networks (CNNs) and transformer architectures. They found that these models generally failed to demonstrate robust conceptual understanding, relying more on superficial patterns than deep semantic comprehension.
However, the study revealed several interesting insights:
- Cross-Attention: V+L models that used cross-attention mechanisms to integrate language and vision performed better on the conceptual understanding tasks.
- Texture vs. Shape: CNNs were stronger at understanding texture and low-level visual patterns, while transformer-based models were better at recognizing color and shape.
Building on these findings, the researchers investigated a simple fine-tuning technique that rewarded the models for performing well on the conceptual understanding benchmarks. This approach showed promising initial results, suggesting a potential path forward for developing V+L models with more robust conceptual abilities.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their study:
- The proposed benchmarks, while grounded in cognitive science, may not fully capture the nuances of human conceptual understanding. Additional evaluation approaches could provide a more comprehensive assessment.
- The fine-tuning technique explored is relatively simple, and more sophisticated methods may be needed to truly instill conceptual understanding in large V+L models.
- The study focuses on a limited set of state-of-the-art models, and the findings may not generalize to future architectures or techniques.
Furthermore, it's worth considering the broader implications of this research. While the results suggest current V+L models lack robust conceptual understanding, the researchers' insights on the strengths and weaknesses of different model architectures could inform the development of more conceptually-aware systems. Ultimately, advancing conceptual understanding in large-scale language and vision models is a crucial step towards building AI systems that can truly comprehend and reason about the world around them.
Conclusion
This research offers a thought-provoking exploration of the conceptual understanding capabilities of large visual-language models. By proposing novel benchmarking datasets and testing state-of-the-art models, the study reveals that current V+L systems predominantly rely on superficial patterns rather than deep semantic comprehension.
The findings provide valuable insights, such as the importance of cross-attention mechanisms and the complementary strengths of CNNs and transformers. These insights could guide future developments in the field, potentially leading to V+L models with more robust conceptual understanding abilities.
Overall, this work represents an important step in pushing the boundaries of what large language and vision models can achieve, and it highlights the need for continued research to develop AI systems with a genuine conceptual grasp of the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Concept-based Analysis of Neural Networks via Vision-Language Models
Ravi Mangal, Nina Narodytska, Divya Gopinath, Boyue Caroline Hu, Anirban Roy, Susmit Jha, Corina Pasareanu
0
0
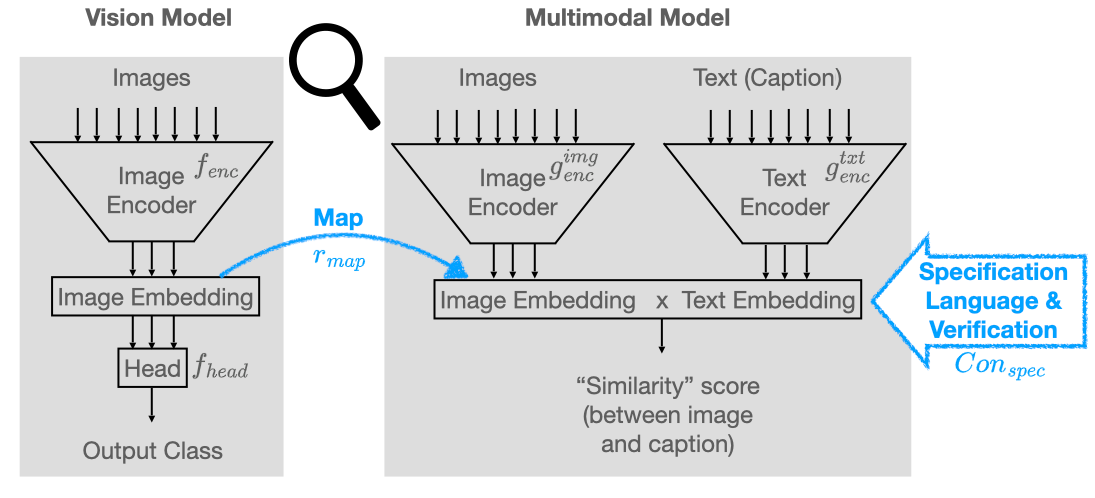
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $texttt{Con}_{texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $texttt{Con}_{texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
4/12/2024
👀
Constructing Multilingual Visual-Text Datasets Revealing Visual Multilingual Ability of Vision Language Models
Jesse Atuhurra, Iqra Ali, Tatsuya Hiraoka, Hidetaka Kamigaito, Tomoya Iwakura, Taro Watanabe
0
0
Large language models (LLMs) have increased interest in vision language models (VLMs), which process image-text pairs as input. Studies investigating the visual understanding ability of VLMs have been proposed, but such studies are still preliminary because existing datasets do not permit a comprehensive evaluation of the fine-grained visual linguistic abilities of VLMs across multiple languages. To further explore the strengths of VLMs, such as GPT-4V cite{openai2023GPT4}, we developed new datasets for the systematic and qualitative analysis of VLMs. Our contribution is four-fold: 1) we introduced nine vision-and-language (VL) tasks (including object recognition, image-text matching, and more) and constructed multilingual visual-text datasets in four languages: English, Japanese, Swahili, and Urdu through utilizing templates containing textit{questions} and prompting GPT4-V to generate the textit{answers} and the textit{rationales}, 2) introduced a new VL task named textit{unrelatedness}, 3) introduced rationales to enable human understanding of the VLM reasoning process, and 4) employed human evaluation to measure the suitability of proposed datasets for VL tasks. We show that VLMs can be fine-tuned on our datasets. Our work is the first to conduct such analyses in Swahili and Urdu. Also, it introduces textit{rationales} in VL analysis, which played a vital role in the evaluation.
6/26/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024

Evaluating Large Vision-Language Models' Understanding of Real-World Complexities Through Synthetic Benchmarks
Haokun Zhou, Yipeng Hong
0
0
This study assesses the ability of Large Vision-Language Models (LVLMs) to differentiate between AI-generated and human-generated images. It introduces a new automated benchmark construction method for this evaluation. The experiment compared common LVLMs with human participants using a mixed dataset of AI and human-created images. Results showed that LVLMs could distinguish between the image types to some extent but exhibited a rightward bias, and perform significantly worse compared to humans. To build on these findings, we developed an automated benchmark construction process using AI. This process involved topic retrieval, narrative script generation, error embedding, and image generation, creating a diverse set of text-image pairs with intentional errors. We validated our method through constructing two caparable benchmarks. This study highlights the strengths and weaknesses of LVLMs in real-world understanding and advances benchmark construction techniques, providing a scalable and automatic approach for AI model evaluation.
6/14/2024