Detect Closer Surfaces that can be Seen: New Modeling and Evaluation in Cross-domain 3D Object Detection

0

Sign in to get full access
Overview
- Presents a new approach for cross-domain 3D object detection that can identify objects in camera images even when the training data comes from a different domain like lidar or radar
- Introduces a modeling framework and evaluation strategy to address the challenges of detecting objects in unseen domains
- Demonstrates improved performance compared to existing cross-domain 3D object detection methods
Plain English Explanation
In the world of self-driving cars and robotics, accurately detecting 3D objects in the environment is crucial. However, this task can be challenging when the training data (e.g. camera images) comes from a different domain than the testing data (e.g. lidar or radar scans). This paper introduces a new approach to address this "cross-domain" problem in 3D object detection.
The key idea is to develop a model that can identify objects that are closer to the camera, even when the training data comes from a different sensor modality. This is important because objects that are physically closer to the camera are often more important for navigation and safety. The paper presents a new modeling framework and evaluation strategy to tackle this problem, and demonstrates improved performance compared to existing cross-domain 3D object detection methods.
Technical Explanation
The paper proposes a new approach for cross-domain 3D object detection, which aims to detect objects in camera images even when the training data comes from a different sensor modality like lidar or radar. This is a challenging problem because the appearance and characteristics of objects can vary significantly between domains.
The core of the approach is a new modeling framework that focuses on identifying objects that are closer to the camera. This is important because closer objects are often more critical for tasks like navigation and collision avoidance. The framework includes novel architecture components and training strategies to effectively leverage the available cross-domain data.
To evaluate their approach, the authors create a new cross-domain 3D object detection benchmark that simulates realistic scenarios where the training and testing data come from different sensor modalities. Experiments on this benchmark demonstrate significant improvements over existing cross-domain 3D object detection methods.
Critical Analysis
The paper presents a novel and well-designed approach to address the important problem of cross-domain 3D object detection. The focus on identifying closer objects is a clever and practical insight, as these are often the most critical for real-world applications like autonomous driving.
That said, the paper does not discuss some potential limitations or caveats of the approach. For example, it's unclear how the method would perform in cases where the training and testing domains have very little overlap, or when there are significant differences in object scale, occlusion, or scene complexity between the domains.
Additionally, the authors could have provided more details on the specific architectural components and training strategies they used, as well as a more thorough analysis of the failure cases and areas for future improvement. This would help other researchers better understand the strengths and weaknesses of the proposed approach.
Conclusion
Overall, this paper makes an important contribution to the field of 3D object detection by introducing a new modeling framework and evaluation strategy for the cross-domain setting. The focus on detecting closer objects is a practical and valuable insight, and the experimental results demonstrate significant performance improvements over existing methods.
While the paper could benefit from additional analysis and discussion of limitations, it represents a solid step forward in addressing the challenges of 3D object detection in real-world, cross-domain scenarios. The insights and techniques presented here could have important implications for the development of robust and reliable perception systems for autonomous robots and vehicles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Detect Closer Surfaces that can be Seen: New Modeling and Evaluation in Cross-domain 3D Object Detection
Ruixiao Zhang, Yihong Wu, Juheon Lee, Adam Prugel-Bennett, Xiaohao Cai
The performance of domain adaptation technologies has not yet reached an ideal level in the current 3D object detection field for autonomous driving, which is mainly due to significant differences in the size of vehicles, as well as the environments they operate in when applied across domains. These factors together hinder the effective transfer and application of knowledge learned from specific datasets. Since the existing evaluation metrics are initially designed for evaluation on a single domain by calculating the 2D or 3D overlap between the prediction and ground-truth bounding boxes, they often suffer from the overfitting problem caused by the size differences among datasets. This raises a fundamental question related to the evaluation of the 3D object detection models' cross-domain performance: Do we really need models to maintain excellent performance in their original 3D bounding boxes after being applied across domains? From a practical application perspective, one of our main focuses is actually on preventing collisions between vehicles and other obstacles, especially in cross-domain scenarios where correctly predicting the size of vehicles is much more difficult. In other words, as long as a model can accurately identify the closest surfaces to the ego vehicle, it is sufficient to effectively avoid obstacles. In this paper, we propose two metrics to measure 3D object detection models' ability of detecting the closer surfaces to the sensor on the ego vehicle, which can be used to evaluate their cross-domain performance more comprehensively and reasonably. Furthermore, we propose a refinement head, named EdgeHead, to guide models to focus more on the learnable closer surfaces, which can greatly improve the cross-domain performance of existing models not only under our new metrics, but even also under the original BEV/3D metrics.
Read more7/15/2024

0
Revisiting Cross-Domain Problem for LiDAR-based 3D Object Detection
Ruixiao Zhang, Juheon Lee, Xiaohao Cai, Adam Prugel-Bennett
Deep learning models such as convolutional neural networks and transformers have been widely applied to solve 3D object detection problems in the domain of autonomous driving. While existing models have achieved outstanding performance on most open benchmarks, the generalization ability of these deep networks is still in doubt. To adapt models to other domains including different cities, countries, and weather, retraining with the target domain data is currently necessary, which hinders the wide application of autonomous driving. In this paper, we deeply analyze the cross-domain performance of the state-of-the-art models. We observe that most models will overfit the training domains and it is challenging to adapt them to other domains directly. Existing domain adaptation methods for 3D object detection problems are actually shifting the models' knowledge domain instead of improving their generalization ability. We then propose additional evaluation metrics -- the side-view and front-view AP -- to better analyze the core issues of the methods' heavy drops in accuracy levels. By using the proposed metrics and further evaluating the cross-domain performance in each dimension, we conclude that the overfitting problem happens more obviously on the front-view surface and the width dimension which usually faces the sensor and has more 3D points surrounding it. Meanwhile, our experiments indicate that the density of the point cloud data also significantly influences the models' cross-domain performance.
Read more8/26/2024

0
Multimodal 3D Object Detection on Unseen Domains
Deepti Hegde, Suhas Lohit, Kuan-Chuan Peng, Michael J. Jones, Vishal M. Patel
LiDAR datasets for autonomous driving exhibit biases in properties such as point cloud density, range, and object dimensions. As a result, object detection networks trained and evaluated in different environments often experience performance degradation. Domain adaptation approaches assume access to unannotated samples from the test distribution to address this problem. However, in the real world, the exact conditions of deployment and access to samples representative of the test dataset may be unavailable while training. We argue that the more realistic and challenging formulation is to require robustness in performance to unseen target domains. We propose to address this problem in a two-pronged manner. First, we leverage paired LiDAR-image data present in most autonomous driving datasets to perform multimodal object detection. We suggest that working with multimodal features by leveraging both images and LiDAR point clouds for scene understanding tasks results in object detectors more robust to unseen domain shifts. Second, we train a 3D object detector to learn multimodal object features across different distributions and promote feature invariance across these source domains to improve generalizability to unseen target domains. To this end, we propose CLIX$^text{3D}$, a multimodal fusion and supervised contrastive learning framework for 3D object detection that performs alignment of object features from same-class samples of different domains while pushing the features from different classes apart. We show that CLIX$^text{3D}$ yields state-of-the-art domain generalization performance under multiple dataset shifts.
Read more4/19/2024
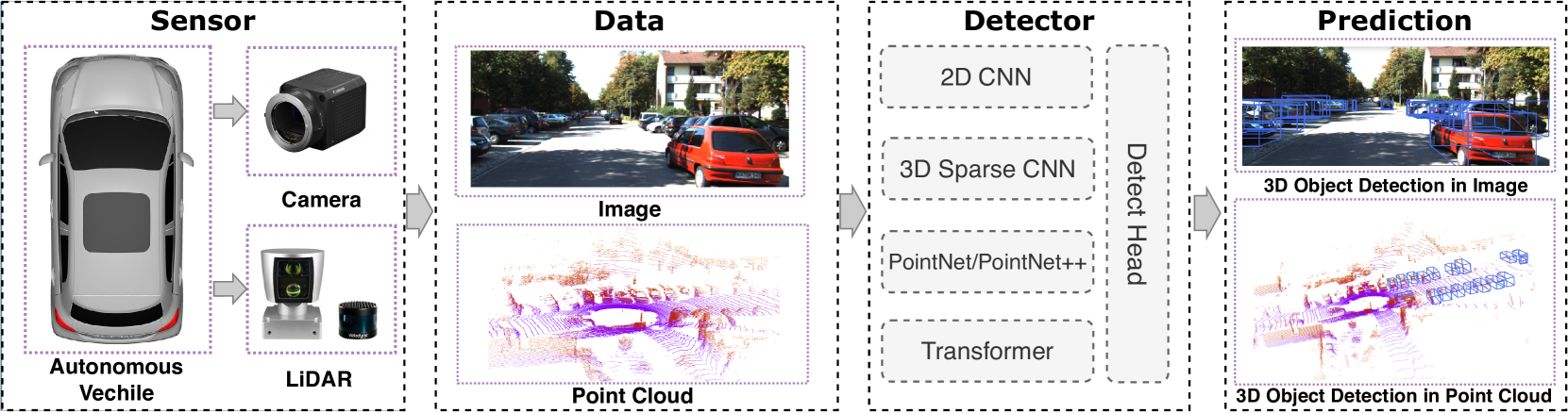
0
Robustness-Aware 3D Object Detection in Autonomous Driving: A Review and Outlook
Ziying Song, Lin Liu, Feiyang Jia, Yadan Luo, Guoxin Zhang, Lei Yang, Li Wang, Caiyan Jia
In the realm of modern autonomous driving, the perception system is indispensable for accurately assessing the state of the surrounding environment, thereby enabling informed prediction and planning. The key step to this system is related to 3D object detection that utilizes vehicle-mounted sensors such as LiDAR and cameras to identify the size, the category, and the location of nearby objects. Despite the surge in 3D object detection methods aimed at enhancing detection precision and efficiency, there is a gap in the literature that systematically examines their resilience against environmental variations, noise, and weather changes. This study emphasizes the importance of robustness, alongside accuracy and latency, in evaluating perception systems under practical scenarios. Our work presents an extensive survey of camera-only, LiDAR-only, and multi-modal 3D object detection algorithms, thoroughly evaluating their trade-off between accuracy, latency, and robustness, particularly on datasets like KITTI-C and nuScenes-C to ensure fair comparisons. Among these, multi-modal 3D detection approaches exhibit superior robustness, and a novel taxonomy is introduced to reorganize the literature for enhanced clarity. This survey aims to offer a more practical perspective on the current capabilities and the constraints of 3D object detection algorithms in real-world applications, thus steering future research towards robustness-centric advancements.
Read more8/16/2024