Detect Fake with Fake: Leveraging Synthetic Data-driven Representation for Synthetic Image Detection

0

Sign in to get full access
Overview
- This paper proposes a novel approach for detecting synthetic images using synthetic data-driven representation.
- The key idea is to leverage the knowledge learned from synthetic data to build a robust model for synthetic image detection.
- The authors design a hierarchical ensemble framework that combines multiple specialized models to achieve high detection accuracy.
Plain English Explanation
The paper discusses a new way to detect fake or synthetic images, which are images that have been generated by artificial intelligence (AI) systems rather than captured by a camera. The researchers realized that the same AI systems that can create these synthetic images might also hold the key to detecting them.
The core insight is that the AI models used to generate synthetic images have learned unique patterns and representations that can be used to identify these fake images. By training specialized models on synthetic data and then combining them in a hierarchical ensemble, the researchers were able to build a highly accurate system for detecting synthetic images.
The key advantage of this approach is that it leverages the strengths of AI in a smart way. Instead of trying to manually engineer rules or features to detect synthetic images, the system learns directly from examples of synthetic data. This allows it to capture the rich, nuanced patterns that distinguish synthetic images from real ones.
Overall, this research represents an innovative application of AI techniques to tackle the important problem of synthetic image detection. By "fighting fire with fire," the researchers have developed a powerful tool that could have significant real-world impact in areas like digital forensics, media authentication, and beyond.
Technical Explanation
The paper introduces a novel synthetic image detection framework called "Detect Fake with Fake" (DF2). The core idea is to leverage the representations learned by AI models trained on synthetic data to build a robust synthetic image classifier.
The authors design a hierarchical ensemble approach that combines multiple specialized models, each trained on a different type of synthetic data. These specialized models capture distinct patterns and artifacts associated with different synthetic image generation techniques. The ensemble framework then aggregates the predictions from these models to achieve high overall detection accuracy.
Specifically, the DF2 framework consists of three main components:
- Specialized Synthetic Image Detectors: These are individual models trained on diverse synthetic datasets, each focusing on a particular type of synthetic image.
- Ensemble Aggregation: A meta-model that combines the predictions from the specialized detectors to output the final synthetic/real classification.
- Representation Learning: A novel technique to learn discriminative representations from synthetic data that can effectively identify synthetic images.
The authors conduct extensive experiments on multiple real and synthetic image benchmarks. They demonstrate that the DF2 framework significantly outperforms prior state-of-the-art synthetic image detection approaches. The ensemble design and synthetic data-driven representation learning are shown to be key factors in the superior performance.
Critical Analysis
The paper presents a well-designed and principled approach to synthetic image detection, with clear technical contributions and strong empirical results. However, a few potential limitations and areas for further research are worth considering:
- Generalization to Emerging Synthetic Techniques: While the ensemble approach is effective, it may struggle to keep up with the rapid pace of innovation in synthetic image generation. New techniques could introduce novel artifacts that the specialized detectors are not trained to recognize.
- Computational Complexity: The hierarchical ensemble design, while powerful, may incur higher computational costs during inference compared to a single-model approach. This could limit the deployability of the system in real-world applications.
- Interpretability and Explainability: The paper does not delve into the interpretability or explainability of the learned representations and detection decisions. Understanding the underlying factors and rationale behind the system's outputs could be important for building trust and ensuring transparency.
- Real-World Deployment Challenges: The paper evaluates the framework on curated benchmarks, but real-world deployment may involve more diverse and noisy data sources. Addressing practical challenges like processing speed, robustness to distribution shifts, and user experience integration would be valuable next steps.
Overall, the "Detect Fake with Fake" approach represents a significant advance in the field of synthetic image detection. By leveraging AI's own strengths against itself, the researchers have developed a powerful and promising solution. However, continued research and development will be necessary to address the limitations and bring this technology into widespread practical use.
Conclusion
This paper introduces a novel synthetic image detection framework that harnesses the power of AI-generated synthetic data to build robust detectors. The key innovation is the hierarchical ensemble design that combines specialized models, each focusing on a specific type of synthetic image. This approach, coupled with a novel representation learning technique, enables the DF2 framework to outperform previous state-of-the-art methods on multiple benchmarks.
The research represents an ingenious application of AI techniques to tackle the important problem of synthetic media detection. By "fighting fire with fire," the authors have developed a promising solution that could have far-reaching impacts in areas like digital forensics, media authentication, and beyond. While the approach has some limitations, the core ideas and insights presented in this paper pave the way for further advancements in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Detect Fake with Fake: Leveraging Synthetic Data-driven Representation for Synthetic Image Detection
Hina Otake, Yoshihiro Fukuhara, Yoshiki Kubotani, Shigeo Morishima
Are general-purpose visual representations acquired solely from synthetic data useful for detecting fake images? In this work, we show the effectiveness of synthetic data-driven representations for synthetic image detection. Upon analysis, we find that vision transformers trained by the latest visual representation learners with synthetic data can effectively distinguish fake from real images without seeing any real images during pre-training. Notably, using SynCLR as the backbone in a state-of-the-art detection method demonstrates a performance improvement of +10.32 mAP and +4.73% accuracy over the widely used CLIP, when tested on previously unseen GAN models. Code is available at https://github.com/cvpaperchallenge/detect-fake-with-fake.
Read more9/16/2024

0
Harnessing Machine Learning for Discerning AI-Generated Synthetic Images
Yuyang Wang, Yizhi Hao, Amando Xu Cong
In the realm of digital media, the advent of AI-generated synthetic images has introduced significant challenges in distinguishing between real and fabricated visual content. These images, often indistinguishable from authentic ones, pose a threat to the credibility of digital media, with potential implications for disinformation and fraud. Our research addresses this challenge by employing machine learning techniques to discern between AI-generated and genuine images. Central to our approach is the CIFAKE dataset, a comprehensive collection of images labeled as Real and Fake. We refine and adapt advanced deep learning architectures like ResNet, VGGNet, and DenseNet, utilizing transfer learning to enhance their precision in identifying synthetic images. We also compare these with a baseline model comprising a vanilla Support Vector Machine (SVM) and a custom Convolutional Neural Network (CNN). The experimental results were significant, demonstrating that our optimized deep learning models outperform traditional methods, with DenseNet achieving an accuracy of 97.74%. Our application study contributes by applying and optimizing these advanced models for synthetic image detection, conducting a comparative analysis using various metrics, and demonstrating their superior capability in identifying AI-generated images over traditional machine learning techniques. This research not only advances the field of digital media integrity but also sets a foundation for future explorations into the ethical and technical dimensions of AI-generated content in digital media.
Read more5/27/2024

0
Leveraging Representations from Intermediate Encoder-blocks for Synthetic Image Detection
Christos Koutlis, Symeon Papadopoulos
The recently developed and publicly available synthetic image generation methods and services make it possible to create extremely realistic imagery on demand, raising great risks for the integrity and safety of online information. State-of-the-art Synthetic Image Detection (SID) research has led to strong evidence on the advantages of feature extraction from foundation models. However, such extracted features mostly encapsulate high-level visual semantics instead of fine-grained details, which are more important for the SID task. On the contrary, shallow layers encode low-level visual information. In this work, we leverage the image representations extracted by intermediate Transformer blocks of CLIP's image-encoder via a lightweight network that maps them to a learnable forgery-aware vector space capable of generalizing exceptionally well. We also employ a trainable module to incorporate the importance of each Transformer block to the final prediction. Our method is compared against the state-of-the-art by evaluating it on 20 test datasets and exhibits an average +10.6% absolute performance improvement. Notably, the best performing models require just a single epoch for training (~8 minutes). Code available at https://github.com/mever-team/rine.
Read more7/9/2024
0
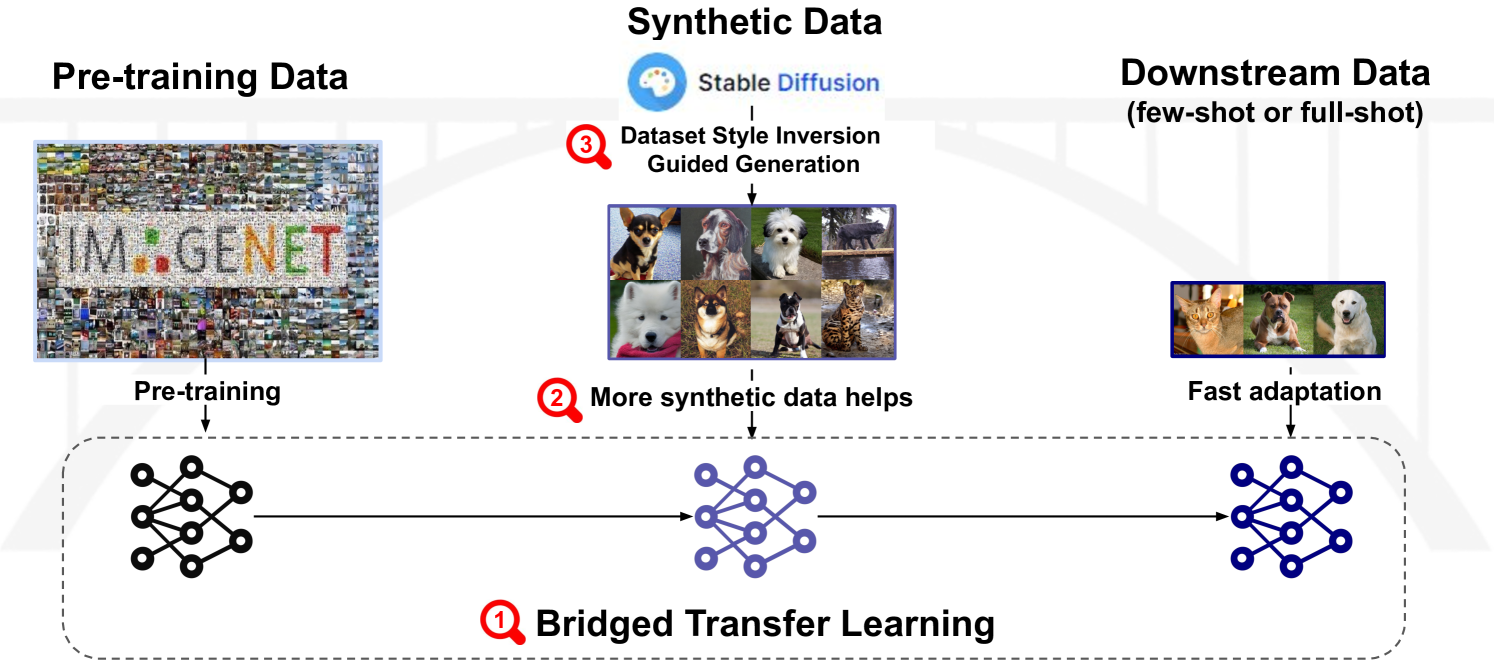
Is Synthetic Image Useful for Transfer Learning? An Investigation into Data Generation, Volume, and Utilization
Yuhang Li, Xin Dong, Chen Chen, Jingtao Li, Yuxin Wen, Michael Spranger, Lingjuan Lyu
Synthetic image data generation represents a promising avenue for training deep learning models, particularly in the realm of transfer learning, where obtaining real images within a specific domain can be prohibitively expensive due to privacy and intellectual property considerations. This work delves into the generation and utilization of synthetic images derived from text-to-image generative models in facilitating transfer learning paradigms. Despite the high visual fidelity of the generated images, we observe that their naive incorporation into existing real-image datasets does not consistently enhance model performance due to the inherent distribution gap between synthetic and real images. To address this issue, we introduce a novel two-stage framework called bridged transfer, which initially employs synthetic images for fine-tuning a pre-trained model to improve its transferability and subsequently uses real data for rapid adaptation. Alongside, We propose dataset style inversion strategy to improve the stylistic alignment between synthetic and real images. Our proposed methods are evaluated across 10 different datasets and 5 distinct models, demonstrating consistent improvements, with up to 30% accuracy increase on classification tasks. Intriguingly, we note that the enhancements were not yet saturated, indicating that the benefits may further increase with an expanded volume of synthetic data.
Read more4/4/2024