Leveraging Representations from Intermediate Encoder-blocks for Synthetic Image Detection

0

Sign in to get full access
Overview
- This paper explores using representations from intermediate encoder blocks in deep learning models to improve the detection of synthetic or manipulated images.
- The researchers propose a novel approach that leverages the features extracted from different layers of an image encoder to enhance the model's ability to distinguish real from fake images.
- The method is evaluated on several benchmark datasets and shown to outperform existing state-of-the-art techniques for synthetic image detection.
Plain English Explanation
Deep learning models, such as those used for image classification, often rely on features extracted from the final encoder layers to make predictions. However, the researchers behind this paper hypothesized that information from intermediate encoder blocks could also be valuable for detecting synthetic or manipulated images.
Synthetic images, often referred to as "deepfakes," are created using advanced techniques like generative adversarial networks (GANs) and can be challenging to distinguish from real images, even for human experts. Detecting these synthetic images is crucial for maintaining trust and integrity in visual media.
The researchers' approach involves extracting features from multiple layers of the image encoder and using them together to make more accurate predictions about whether an image is real or synthetic. By leveraging a richer set of representations, the model can learn more nuanced cues that distinguish authentic from manipulated imagery.
This technique builds upon prior work in liveness detection and zero-shot image classification, demonstrating how insights from those fields can be applied to the challenge of synthetic image detection.
Technical Explanation
The researchers propose a model architecture that takes an input image and passes it through a pre-trained image encoder, such as a convolutional neural network (CNN) or a vision transformer (ViT). Instead of relying solely on the final encoder layer, the model extracts features from multiple intermediate layers and combines them to produce the final prediction.
Specifically, the researchers employ a "feature fusion" module that aggregates the representations from different encoder blocks, allowing the model to leverage a more diverse set of visual cues. This approach is inspired by the observation that lower-level features in the encoder can capture local patterns, while higher-level features can encode more global, semantic information - both of which are likely important for distinguishing real from synthetic images.
The fused features are then passed through a series of fully connected layers to produce the final classification output, indicating whether the input image is real or synthetic. The model is trained end-to-end using a combination of standard classification loss and regularization techniques to encourage the encoder to learn discriminative features.
The researchers evaluate their approach on several benchmark datasets for synthetic image detection, including FaceForensics++ and Celeb-DF. Their results demonstrate that leveraging intermediate encoder representations outperforms existing state-of-the-art methods, highlighting the value of this novel technique for improving the robustness and reliability of synthetic image detection systems.
Critical Analysis
The researchers acknowledge that their approach, while effective, may still have limitations in handling certain types of sophisticated synthetic images or completely novel manipulation techniques. They suggest that further research is needed to explore the generalization capabilities of the model and its ability to adapt to emerging threats in the rapidly evolving field of synthetic media detection.
Additionally, the paper does not provide a comprehensive analysis of the computational and memory overhead introduced by the feature fusion module, which could be an important practical consideration for real-world deployment. It would be valuable for future work to investigate the trade-offs between the performance gains and the increased model complexity.
Another potential area for further investigation is the interpretability of the model's predictions. Understanding the specific visual cues that the model uses to distinguish real from synthetic images could provide valuable insights for improving the explainability and trustworthiness of the system, which is crucial for sensitive applications like media authentication.
Conclusion
This paper presents a novel approach for leveraging representations from intermediate encoder blocks in deep learning models to enhance the detection of synthetic or manipulated images. By combining features from multiple layers of the encoder, the model can learn more robust and discriminative representations, outperforming existing state-of-the-art techniques on several benchmark datasets.
The researchers' findings contribute to the ongoing efforts to develop reliable and scalable solutions for combating the growing threat of synthetic media, which can have significant societal and ethical implications. As the field of synthetic image detection continues to evolve, this work highlights the importance of exploring innovative architectural designs and feature extraction strategies to stay ahead of the ever-changing landscape of digital manipulation techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Leveraging Representations from Intermediate Encoder-blocks for Synthetic Image Detection
Christos Koutlis, Symeon Papadopoulos
The recently developed and publicly available synthetic image generation methods and services make it possible to create extremely realistic imagery on demand, raising great risks for the integrity and safety of online information. State-of-the-art Synthetic Image Detection (SID) research has led to strong evidence on the advantages of feature extraction from foundation models. However, such extracted features mostly encapsulate high-level visual semantics instead of fine-grained details, which are more important for the SID task. On the contrary, shallow layers encode low-level visual information. In this work, we leverage the image representations extracted by intermediate Transformer blocks of CLIP's image-encoder via a lightweight network that maps them to a learnable forgery-aware vector space capable of generalizing exceptionally well. We also employ a trainable module to incorporate the importance of each Transformer block to the final prediction. Our method is compared against the state-of-the-art by evaluating it on 20 test datasets and exhibits an average +10.6% absolute performance improvement. Notably, the best performing models require just a single epoch for training (~8 minutes). Code available at https://github.com/mever-team/rine.
Read more7/9/2024

0
New!Detect Fake with Fake: Leveraging Synthetic Data-driven Representation for Synthetic Image Detection
Hina Otake, Yoshihiro Fukuhara, Yoshiki Kubotani, Shigeo Morishima
Are general-purpose visual representations acquired solely from synthetic data useful for detecting fake images? In this work, we show the effectiveness of synthetic data-driven representations for synthetic image detection. Upon analysis, we find that vision transformers trained by the latest visual representation learners with synthetic data can effectively distinguish fake from real images without seeing any real images during pre-training. Notably, using SynCLR as the backbone in a state-of-the-art detection method demonstrates a performance improvement of +10.32 mAP and +4.73% accuracy over the widely used CLIP, when tested on previously unseen GAN models. Code is available at https://github.com/cvpaperchallenge/detect-fake-with-fake.
Read more9/16/2024

0
Improving Synthetic Image Detection Towards Generalization: An Image Transformation Perspective
Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, Fuli Feng
With recent generative models facilitating photo-realistic image synthesis, the proliferation of synthetic images has also engendered certain negative impacts on social platforms, thereby raising an urgent imperative to develop effective detectors. Current synthetic image detection (SID) pipelines are primarily dedicated to crafting universal artifact features, accompanied by an oversight about SID training paradigm. In this paper, we re-examine the SID problem and identify two prevalent biases in current training paradigms, i.e., weakened artifact features and overfitted artifact features. Meanwhile, we discover that the imaging mechanism of synthetic images contributes to heightened local correlations among pixels, suggesting that detectors should be equipped with local awareness. In this light, we propose SAFE, a lightweight and effective detector with three simple image transformations. Firstly, for weakened artifact features, we substitute the down-sampling operator with the crop operator in image pre-processing to help circumvent artifact distortion. Secondly, for overfitted artifact features, we include ColorJitter and RandomRotation as additional data augmentations, to help alleviate irrelevant biases from color discrepancies and semantic differences in limited training samples. Thirdly, for local awareness, we propose a patch-based random masking strategy tailored for SID, forcing the detector to focus on local regions at training. Comparative experiments are conducted on an open-world dataset, comprising synthetic images generated by 26 distinct generative models. Our pipeline achieves a new state-of-the-art performance, with remarkable improvements of 4.5% in accuracy and 2.9% in average precision against existing methods.
Read more8/14/2024
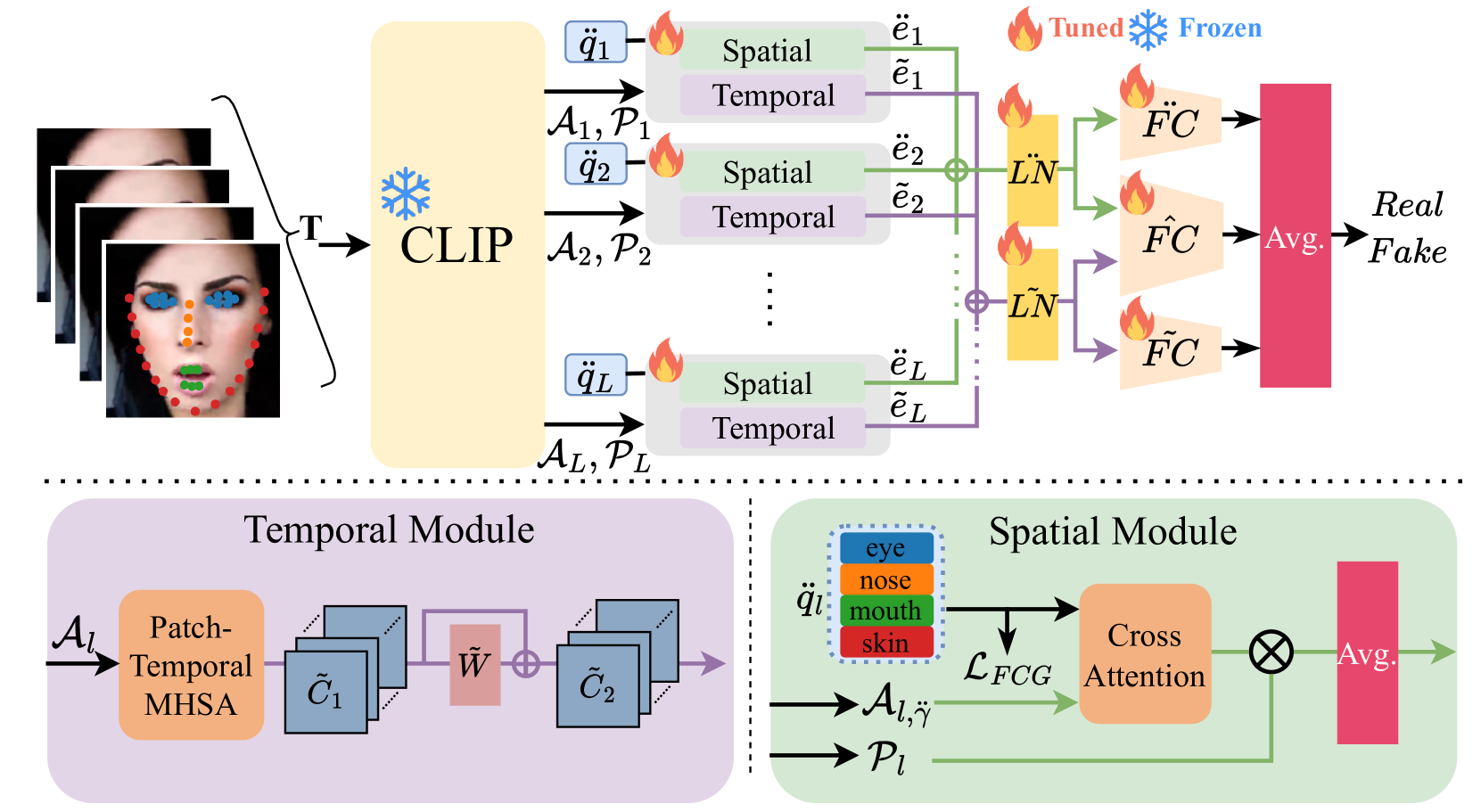
0
Towards More General Video-based Deepfake Detection through Facial Feature Guided Adaptation for Foundation Model
Yue-Hua Han, Tai-Ming Huang, Shu-Tzu Lo, Po-Han Huang, Kai-Lung Hua, Jun-Cheng Chen
With the rise of deep learning, generative models have enabled the creation of highly realistic synthetic images, presenting challenges due to their potential misuse. While research in Deepfake detection has grown rapidly in response, many detection methods struggle with unseen Deepfakes generated by new synthesis techniques. To address this generalisation challenge, we propose a novel Deepfake detection approach by adapting the Foundation Models with rich information encoded inside, specifically using the image encoder from CLIP which has demonstrated strong zero-shot capability for downstream tasks. Inspired by the recent advances of parameter efficient fine-tuning, we propose a novel side-network-based decoder to extract spatial and temporal cues from the given video clip, with the promotion of the Facial Component Guidance (FCG) to encourage the spatial feature to include features of key facial parts for more robust and general Deepfake detection. Through extensive cross-dataset evaluations, our approach exhibits superior effectiveness in identifying unseen Deepfake samples, achieving notable performance improvement even with limited training samples and manipulation types. Our model secures an average performance enhancement of 0.9% AUROC in cross-dataset assessments comparing with state-of-the-art methods, especially a significant lead of achieving 4.4% improvement on the challenging DFDC dataset.
Read more6/6/2024