Is Synthetic Image Useful for Transfer Learning? An Investigation into Data Generation, Volume, and Utilization
2403.19866
0
0
Abstract
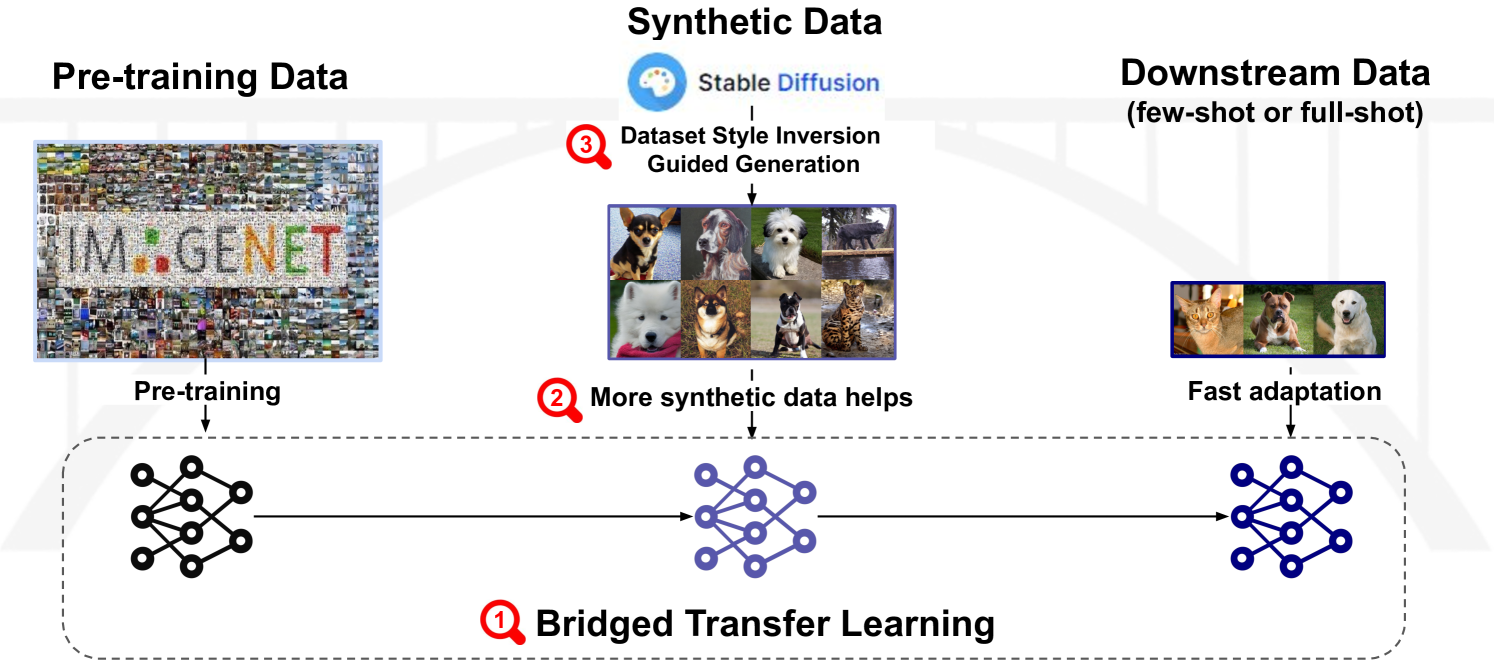
Synthetic image data generation represents a promising avenue for training deep learning models, particularly in the realm of transfer learning, where obtaining real images within a specific domain can be prohibitively expensive due to privacy and intellectual property considerations. This work delves into the generation and utilization of synthetic images derived from text-to-image generative models in facilitating transfer learning paradigms. Despite the high visual fidelity of the generated images, we observe that their naive incorporation into existing real-image datasets does not consistently enhance model performance due to the inherent distribution gap between synthetic and real images. To address this issue, we introduce a novel two-stage framework called bridged transfer, which initially employs synthetic images for fine-tuning a pre-trained model to improve its transferability and subsequently uses real data for rapid adaptation. Alongside, We propose dataset style inversion strategy to improve the stylistic alignment between synthetic and real images. Our proposed methods are evaluated across 10 different datasets and 5 distinct models, demonstrating consistent improvements, with up to 30% accuracy increase on classification tasks. Intriguingly, we note that the enhancements were not yet saturated, indicating that the benefits may further increase with an expanded volume of synthetic data.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper investigates the use of synthetic images for transfer learning in machine learning models.
- It examines the impact of data generation, volume, and utilization on the performance of transfer learning.
- The researchers conduct experiments to understand the effectiveness of synthetic data in boosting model performance compared to real-world datasets.
Plain English Explanation
The paper explores the potential benefits of using synthetic, computer-generated images for training machine learning models. Transfer learning is a technique where a model trained on a large dataset is then fine-tuned on a smaller, specialized dataset to improve its performance on a specific task.
The researchers wanted to see if synthetic data could be used effectively in this transfer learning process. They generated various amounts of synthetic images and tested how well models performed when trained on a combination of real and synthetic data, compared to using real data alone.
The key idea is that synthetic data can be created in large quantities, which may help compensate for the lack of real-world data, especially in niche or specialized domains. By intelligently blending synthetic and real data, the researchers hoped to boost model performance beyond what could be achieved with real data alone.
Technical Explanation
The paper conducts experiments to evaluate the use of synthetic data for transfer learning. They first generate synthetic images using a Generative Adversarial Network (GAN) model. They then train a base model on a large dataset of real images, and fine-tune this model using varying proportions of real and synthetic images.
The experiments test different data generation ratios, with synthetic data making up 0%, 25%, 50%, 75%, and 100% of the fine-tuning dataset. They evaluate the model's performance on a held-out test set of real images.
The results show that using a combination of real and synthetic data can outperform using real data alone, particularly when the synthetic data makes up 25-50% of the fine-tuning dataset. However, relying solely on synthetic data (100%) results in worse performance compared to using real data.
The paper also investigates the effect of dataset size, finding that the benefits of synthetic data are more pronounced when the real-world dataset is smaller. As the real dataset size increases, the relative advantage of synthetic data diminishes.
Critical Analysis
The paper provides a thorough investigation into the use of synthetic data for transfer learning, with well-designed experiments and clear insights. However, a few caveats and areas for further research are worth noting:
-
The experiments are limited to a single domain (image classification) and may not generalize to other tasks or data modalities. Further research is needed to understand the broader applicability of these findings.
-
The quality and realism of the synthetic data generated by the GAN model could play a significant role in the results. More research is needed on the impact of synthetic data quality on transfer learning performance.
-
The paper does not explore the potential biases or artifacts that may be present in the synthetic data and how they might affect model performance on real-world data. This is an important consideration for the practical deployment of such techniques.
-
The experiments focus on the relative performance of models, but do not assess the computational or training efficiency of using synthetic data. This aspect could be important in real-world deployment scenarios.
Conclusion
Overall, this paper presents a valuable contribution to the understanding of synthetic data's role in transfer learning. The findings suggest that judiciously combining real and synthetic data can boost model performance, especially when real-world datasets are limited. However, the benefits are not unconditional, and further research is needed to understand the broader implications and practical considerations of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
Mind the Gap Between Synthetic and Real: Utilizing Transfer Learning to Probe the Boundaries of Stable Diffusion Generated Data
Leonhard Hennicke, Christian Medeiros Adriano, Holger Giese, Jan Mathias Koehler, Lukas Schott
0
0
Generative foundation models like Stable Diffusion comprise a diverse spectrum of knowledge in computer vision with the potential for transfer learning, e.g., via generating data to train student models for downstream tasks. This could circumvent the necessity of collecting labeled real-world data, thereby presenting a form of data-free knowledge distillation. However, the resultant student models show a significant drop in accuracy compared to models trained on real data. We investigate possible causes for this drop and focus on the role of the different layers of the student model. By training these layers using either real or synthetic data, we reveal that the drop mainly stems from the model's final layers. Further, we briefly investigate other factors, such as differences in data-normalization between synthetic and real, the impact of data augmentations, texture vs. shape learning, and assuming oracle prompts. While we find that some of those factors can have an impact, they are not sufficient to close the gap towards real data. Building upon our insights that mainly later layers are responsible for the drop, we investigate the data-efficiency of fine-tuning a synthetically trained model with real data applied to only those last layers. Our results suggest an improved trade-off between the amount of real training data used and the model's accuracy. Our findings contribute to the understanding of the gap between synthetic and real data and indicate solutions to mitigate the scarcity of labeled real data.
5/7/2024
📊
Synthetic Data Generation for Bridging Sim2Real Gap in a Production Environment
Parth Rawal, Mrunal Sompura, Wolfgang Hintze
0
0
Synthetic data is being used lately for training deep neural networks in computer vision applications such as object detection, object segmentation and 6D object pose estimation. Domain randomization hereby plays an important role in reducing the simulation to reality gap. However, this generalization might not be effective in specialized domains like a production environment involving complex assemblies. Either the individual parts, trained with synthetic images, are integrated in much larger assemblies making them indistinguishable from their counterparts and result in false positives or are partially occluded just enough to give rise to false negatives. Domain knowledge is vital in these cases and if conceived effectively while generating synthetic data, can show a considerable improvement in bridging the simulation to reality gap. This paper focuses on synthetic data generation procedures for parts and assemblies used in a production environment. The basic procedures for synthetic data generation and their various combinations are evaluated and compared on images captured in a production environment, where results show up to 15% improvement using combinations of basic procedures. Reducing the simulation to reality gap in this way can aid to utilize the true potential of robot assisted production using artificial intelligence.
5/13/2024

Generating Synthetic Satellite Imagery With Deep-Learning Text-to-Image Models -- Technical Challenges and Implications for Monitoring and Verification
Tuong Vy Nguyen, Alexander Glaser, Felix Biessmann
0
0
Novel deep-learning (DL) architectures have reached a level where they can generate digital media, including photorealistic images, that are difficult to distinguish from real data. These technologies have already been used to generate training data for Machine Learning (ML) models, and large text-to-image models like DALL-E 2, Imagen, and Stable Diffusion are achieving remarkable results in realistic high-resolution image generation. Given these developments, issues of data authentication in monitoring and verification deserve a careful and systematic analysis: How realistic are synthetic images? How easily can they be generated? How useful are they for ML researchers, and what is their potential for Open Science? In this work, we use novel DL models to explore how synthetic satellite images can be created using conditioning mechanisms. We investigate the challenges of synthetic satellite image generation and evaluate the results based on authenticity and state-of-the-art metrics. Furthermore, we investigate how synthetic data can alleviate the lack of data in the context of ML methods for remote-sensing. Finally we discuss implications of synthetic satellite imagery in the context of monitoring and verification.
4/12/2024
Domain-Transferred Synthetic Data Generation for Improving Monocular Depth Estimation
Seungyeop Lee, Knut Peterson, Solmaz Arezoomandan, Bill Cai, Peihan Li, Lifeng Zhou, David Han
0
0
A major obstacle to the development of effective monocular depth estimation algorithms is the difficulty in obtaining high-quality depth data that corresponds to collected RGB images. Collecting this data is time-consuming and costly, and even data collected by modern sensors has limited range or resolution, and is subject to inconsistencies and noise. To combat this, we propose a method of data generation in simulation using 3D synthetic environments and CycleGAN domain transfer. We compare this method of data generation to the popular NYUDepth V2 dataset by training a depth estimation model based on the DenseDepth structure using different training sets of real and simulated data. We evaluate the performance of the models on newly collected images and LiDAR depth data from a Husky robot to verify the generalizability of the approach and show that GAN-transformed data can serve as an effective alternative to real-world data, particularly in depth estimation.
5/3/2024