Detecting critical treatment effect bias in small subgroups
2404.18905
0
0
📊
Abstract
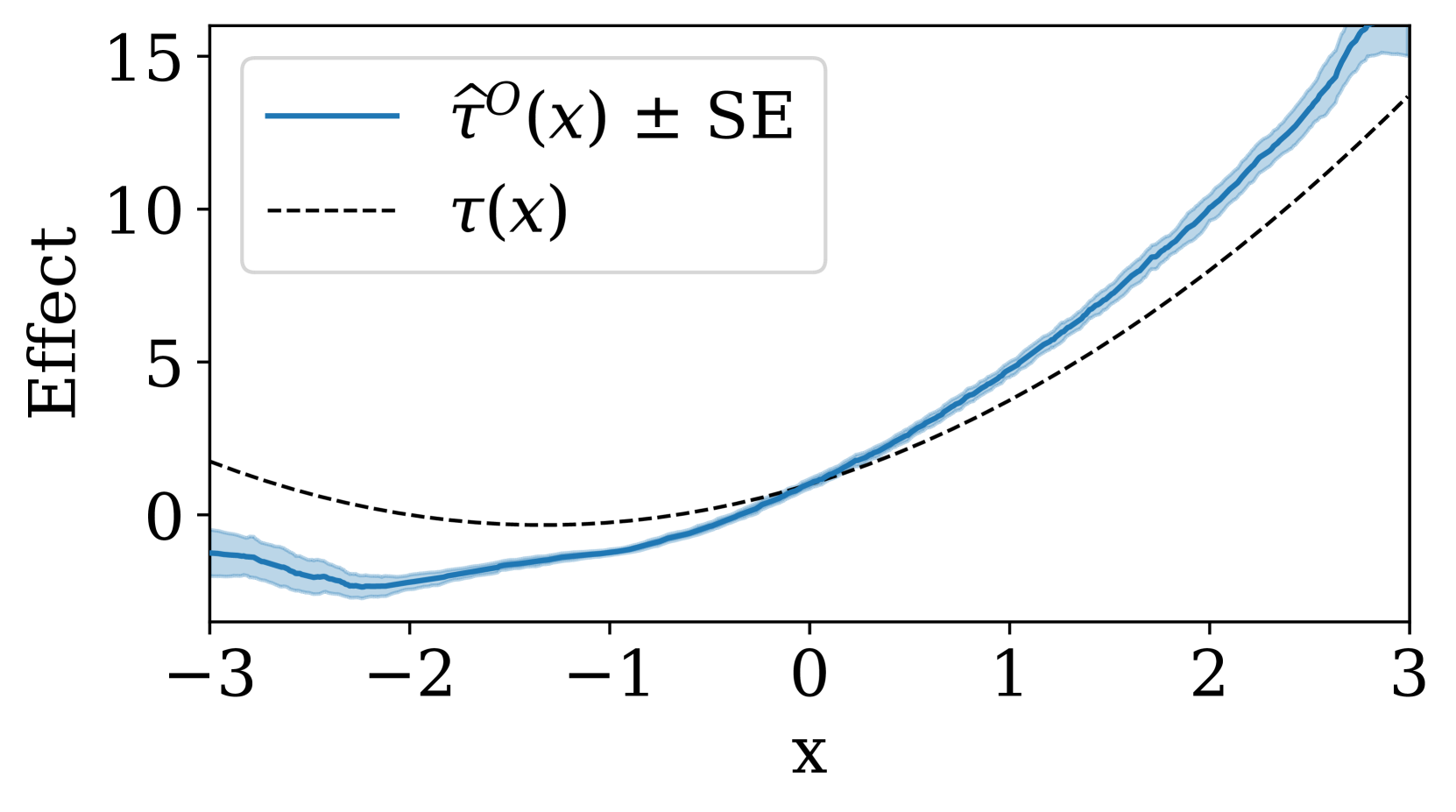
Randomized trials are considered the gold standard for making informed decisions in medicine, yet they often lack generalizability to the patient populations in clinical practice. Observational studies, on the other hand, cover a broader patient population but are prone to various biases. Thus, before using an observational study for decision-making, it is crucial to benchmark its treatment effect estimates against those derived from a randomized trial. We propose a novel strategy to benchmark observational studies beyond the average treatment effect. First, we design a statistical test for the null hypothesis that the treatment effects estimated from the two studies, conditioned on a set of relevant features, differ up to some tolerance. We then estimate an asymptotically valid lower bound on the maximum bias strength for any subgroup in the observational study. Finally, we validate our benchmarking strategy in a real-world setting and show that it leads to conclusions that align with established medical knowledge.
Create account to get full access
Overview
- Randomized trials are considered the gold standard for making informed decisions in medicine, but they often lack generalizability to real-world patient populations.
- Observational studies cover a broader population but are prone to various biases.
- It is crucial to benchmark observational studies against randomized trials before using them for decision-making.
Plain English Explanation
Randomized trials are seen as the best way to test new medical treatments, as they provide the most reliable information about the treatment's effectiveness. However, the patients in these trials may not be representative of the full range of people who will actually receive the treatment in real-world clinical practice.
On the other hand, observational studies look at a wider variety of patients, but they can be subject to various biases that can skew the results. Before using the findings from an observational study to guide medical decisions, it's important to compare its estimates of the treatment's effects to the results from a randomized trial.
The researchers propose a new approach to do this benchmarking that goes beyond just looking at the average treatment effect. They develop a statistical test to see if the treatment effects estimated by the two studies are similar, even when considering differences in the patient populations. They also calculate a lower bound on the maximum potential bias in the observational study's results.
By validating this benchmarking strategy using real-world data, the researchers show that it can lead to conclusions that align with established medical knowledge.
Technical Explanation
The researchers designed a statistical test to assess whether the treatment effect estimates from an observational study and a randomized trial, conditioned on relevant features, are consistent within a specified tolerance. This goes beyond simply comparing the average treatment effects, which may overlook important differences in the underlying patient populations.
They also derived an estimate of the asymptotic lower bound on the maximum bias strength for any subgroup in the observational study. This provides a quantitative measure of the potential limitations of the observational study, beyond just the average.
The researchers validated their benchmarking approach using real-world data, and showed that the conclusions drawn align with established medical knowledge. This suggests the method can help reconcile findings from observational studies and randomized trials, improving the way causal effects are estimated from non-experimental data.
Critical Analysis
The paper acknowledges that observational studies can suffer from various biases, and that care must be taken when using their results for decision-making. The proposed benchmarking strategy helps address this by quantifying the potential limitations of the observational study, beyond just comparing average treatment effects.
However, the method still relies on the assumption that the relevant confounding factors have been properly measured and included in the analysis. If there are unobserved confounders, the benchmarking approach may not fully account for the biases in the observational study.
Additionally, the validation in a real-world setting was limited to a single case study. Further testing with a wider range of observational and randomized studies would help demonstrate the broader applicability and robustness of the proposed benchmarking approach.
Conclusion
This research proposes a novel strategy to benchmark observational studies against randomized trials, going beyond just comparing average treatment effects. By quantifying the potential biases in the observational study, this approach can help reconcile findings from different study designs and improve the use of non-experimental data for causal inference.
Validating this method with real-world data suggests it can lead to conclusions aligned with established medical knowledge. However, further testing is needed to fully understand the limitations and generalizability of this benchmarking approach, particularly regarding the role of unobserved confounders.
Overall, this research represents an important step towards better integrating observational and experimental data to inform medical decision-making, with implications for causal modeling more broadly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
Hidden yet quantifiable: A lower bound for confounding strength using randomized trials
Piersilvio De Bartolomeis, Javier Abad, Konstantin Donhauser, Fanny Yang
0
0
In the era of fast-paced precision medicine, observational studies play a major role in properly evaluating new treatments in clinical practice. Yet, unobserved confounding can significantly compromise causal conclusions drawn from non-randomized data. We propose a novel strategy that leverages randomized trials to quantify unobserved confounding. First, we design a statistical test to detect unobserved confounding with strength above a given threshold. Then, we use the test to estimate an asymptotically valid lower bound on the unobserved confounding strength. We evaluate the power and validity of our statistical test on several synthetic and semi-synthetic datasets. Further, we show how our lower bound can correctly identify the absence and presence of unobserved confounding in a real-world setting.
5/2/2024
Estimating Heterogeneous Treatment Effects by Combining Weak Instruments and Observational Data
Miruna Oprescu, Nathan Kallus
0
0
Accurately predicting conditional average treatment effects (CATEs) is crucial in personalized medicine and digital platform analytics. Since often the treatments of interest cannot be directly randomized, observational data is leveraged to learn CATEs, but this approach can incur significant bias from unobserved confounding. One strategy to overcome these limitations is to seek latent quasi-experiments in instrumental variables (IVs) for the treatment, for example, a randomized intent to treat or a randomized product recommendation. This approach, on the other hand, can suffer from low compliance, i.e., IV weakness. Some subgroups may even exhibit zero compliance meaning we cannot instrument for their CATEs at all. In this paper we develop a novel approach to combine IV and observational data to enable reliable CATE estimation in the presence of unobserved confounding in the observational data and low compliance in the IV data, including no compliance for some subgroups. We propose a two-stage framework that first learns biased CATEs from the observational data, and then applies a compliance-weighted correction using IV data, effectively leveraging IV strength variability across covariates. We characterize the convergence rates of our method and validate its effectiveness through a simulation study. Additionally, we demonstrate its utility with real data by analyzing the heterogeneous effects of 401(k) plan participation on wealth.
6/11/2024

Prediction-powered Generalization of Causal Inferences
Ilker Demirel, Ahmed Alaa, Anthony Philippakis, David Sontag
0
0
Causal inferences from a randomized controlled trial (RCT) may not pertain to a target population where some effect modifiers have a different distribution. Prior work studies generalizing the results of a trial to a target population with no outcome but covariate data available. We show how the limited size of trials makes generalization a statistically infeasible task, as it requires estimating complex nuisance functions. We develop generalization algorithms that supplement the trial data with a prediction model learned from an additional observational study (OS), without making any assumptions on the OS. We theoretically and empirically show that our methods facilitate better generalization when the OS is high-quality, and remain robust when it is not, and e.g., have unmeasured confounding.
6/6/2024

A Double Machine Learning Approach to Combining Experimental and Observational Data
Harsh Parikh, Marco Morucci, Vittorio Orlandi, Sudeepa Roy, Cynthia Rudin, Alexander Volfovsky
0
0
Experimental and observational studies often lack validity due to untestable assumptions. We propose a double machine learning approach to combine experimental and observational studies, allowing practitioners to test for assumption violations and estimate treatment effects consistently. Our framework tests for violations of external validity and ignorability under milder assumptions. When only one of these assumptions is violated, we provide semiparametrically efficient treatment effect estimators. However, our no-free-lunch theorem highlights the necessity of accurately identifying the violated assumption for consistent treatment effect estimation. Through comparative analyses, we show our framework's superiority over existing data fusion methods. The practical utility of our approach is further exemplified by three real-world case studies, underscoring its potential for widespread application in empirical research.
4/4/2024