Mitigating Dialogue Hallucination for Large Vision Language Models via Adversarial Instruction Tuning
2403.10492
0
0

Abstract
Mitigating hallucinations of Large Vision Language Models,(LVLMs) is crucial to enhance their reliability for general-purpose assistants. This paper shows that such hallucinations of LVLMs can be significantly exacerbated by preceding user-system dialogues. To precisely measure this, we first present an evaluation benchmark by extending popular multi-modal benchmark datasets with prepended hallucinatory dialogues powered by our novel Adversarial Question Generator (AQG), which can automatically generate image-related yet adversarial dialogues by adopting adversarial attacks on LVLMs. On our benchmark, the zero-shot performance of state-of-the-art LVLMs drops significantly for both the VQA and Captioning tasks. Next, we further reveal this hallucination is mainly due to the prediction bias toward preceding dialogues rather than visual content. To reduce this bias, we propose Adversarial Instruction Tuning (AIT) that robustly fine-tunes LVLMs against hallucinatory dialogues. Extensive experiments show our proposed approach successfully reduces dialogue hallucination while maintaining performance.
Create account to get full access
Overview
- This paper presents a novel approach, called Adversarial Instruction Tuning (AIT), to mitigate dialogue hallucination in large multi-modal models.
- Dialogue hallucination is the issue where large language models generate irrelevant or nonsensical responses during open-ended dialogue.
- The authors show that AIT can effectively reduce hallucination while maintaining the models' strong performance on various tasks.
Plain English Explanation
The paper addresses the problem of dialogue hallucination in large multi-modal models. Dialogue hallucination occurs when these powerful AI models generate responses that are irrelevant or nonsensical during open-ended conversations.
To solve this issue, the researchers developed a technique called Adversarial Instruction Tuning (AIT). AIT works by fine-tuning the models using "adversarial" instructions - prompts that are designed to push the models towards producing more coherent and grounded responses.
The key insight is that by training the models to follow these carefully crafted instructions, they become less prone to generating hallucinated outputs during open-ended dialogue. The authors demonstrate that AIT can effectively reduce hallucination while preserving the models' strong performance on a variety of other tasks, such as question answering and reading comprehension.
Technical Explanation
The paper introduces Adversarial Instruction Tuning (AIT), a novel technique to mitigate dialogue hallucination in large multi-modal models. Dialogue hallucination is the issue where these powerful models generate irrelevant or nonsensical responses during open-ended conversations.
The AIT approach works by fine-tuning the models using "adversarial" instructions - prompts that are carefully designed to push the models towards producing more coherent and grounded responses. The key insight is that by training the models to follow these adversarial instructions, they become less prone to generating hallucinated outputs during open-ended dialogue.
The authors evaluate AIT on a variety of large multi-modal models, including GPT-3 and CLIP. Their experiments show that AIT can effectively reduce dialogue hallucination while maintaining the models' strong performance on tasks such as question answering and reading comprehension.
Critical Analysis
The paper presents a novel and promising approach to mitigating dialogue hallucination in large multi-modal models. The authors have thoughtfully designed the AIT technique and demonstrated its effectiveness through extensive experiments.
One potential limitation of the study is that it focuses primarily on reducing hallucination in open-ended dialogue, and does not explore the impact of AIT on other types of multi-modal tasks, such as image captioning or visual question answering. Further research would be needed to understand the broader applicability of the technique.
Additionally, the paper does not provide much insight into the underlying mechanisms by which AIT achieves its performance gains. A deeper analysis of the changes in the models' internal representations and decision-making processes could lead to a better understanding of the approach and guide future improvements.
Overall, the paper makes a valuable contribution to the field of large multi-modal models and provides a solid foundation for further research on addressing the critical issue of dialogue hallucination.
Conclusion
This paper introduces Adversarial Instruction Tuning (AIT), a novel technique for mitigating dialogue hallucination in large multi-modal models. The key idea is to fine-tune these powerful models using carefully crafted "adversarial" instructions, which helps reduce their tendency to generate irrelevant or nonsensical responses during open-ended conversations.
The authors demonstrate the effectiveness of AIT through extensive experiments, showing that it can significantly improve the coherence and grounding of the models' dialogue outputs while maintaining strong performance on other tasks. This work represents an important step forward in addressing the critical challenge of dialogue hallucination, which has been a major limitation of large language models.
The insights and techniques presented in this paper have the potential to enhance the reliability and trustworthiness of multi-modal AI systems, paving the way for their more widespread and impactful deployment in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
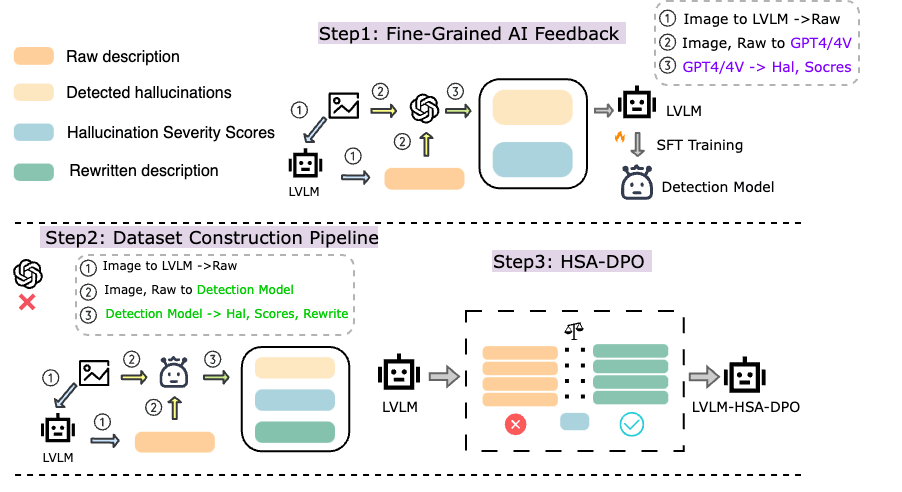
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
0
0
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
4/23/2024
🏋️
Prescribing the Right Remedy: Mitigating Hallucinations in Large Vision-Language Models via Targeted Instruction Tuning
Rui Hu, Yahan Tu, Jitao Sang
0
0
Despite achieving outstanding performance on various cross-modal tasks, current large vision-language models (LVLMs) still suffer from hallucination issues, manifesting as inconsistencies between their generated responses and the corresponding images. Prior research has implicated that the low quality of instruction data, particularly the skewed balance between positive and negative samples, is a significant contributor to model hallucinations. Recently, researchers have proposed high-quality instruction datasets, such as LRV-Instruction, to mitigate model hallucination. Nonetheless, our investigation reveals that hallucinatory concepts from different LVLMs exhibit specificity, i.e. the distribution of hallucinatory concepts varies significantly across models. Existing datasets did not consider the hallucination specificity of different models in the design processes, thereby diminishing their efficacy in mitigating model hallucination. In this paper, we propose a targeted instruction data generation framework named DFTG that tailored to the hallucination specificity of different models. Concretely, DFTG consists of two stages: hallucination diagnosis, which extracts the necessary information from the model's responses and images for hallucination diagnosis; and targeted data generation, which generates targeted instruction data based on diagnostic results. The experimental results on hallucination benchmarks demonstrate that the targeted instruction data generated by our method are more effective in mitigating hallucinations compared to previous datasets.
4/17/2024

Alleviating Hallucinations in Large Vision-Language Models through Hallucination-Induced Optimization
Beitao Chen, Xinyu Lyu, Lianli Gao, Jingkuan Song, Heng Tao Shen
0
0
Although Large Visual Language Models (LVLMs) have demonstrated exceptional abilities in understanding multimodal data, they invariably suffer from hallucinations, leading to a disconnect between the generated text and the corresponding images. Almost all current visual contrastive decoding methods attempt to mitigate these hallucinations by introducing visual uncertainty information that appropriately widens the contrastive logits gap between hallucinatory and targeted ones. However, due to uncontrollable nature of the global visual uncertainty, they struggle to precisely induce the hallucinatory tokens, which severely limits their effectiveness in mitigating hallucinations and may even lead to the generation of undesired hallucinations. To tackle this issue, we conducted the theoretical analysis to promote the effectiveness of contrast decoding. Building on this insight, we introduce a novel optimization strategy named Hallucination-Induced Optimization (HIO). This strategy seeks to amplify the contrast between hallucinatory and targeted tokens relying on a fine-tuned theoretical preference model (i.e., Contrary Bradley-Terry Model), thereby facilitating efficient contrast decoding to alleviate hallucinations in LVLMs. Extensive experimental research demonstrates that our HIO strategy can effectively reduce hallucinations in LVLMs, outperforming state-of-the-art methods across various benchmarks.
5/27/2024

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024