Constructing Benchmarks and Interventions for Combating Hallucinations in LLMs
2404.09971
0
0

Abstract
Large language models (LLMs) are susceptible to hallucination, which sparked a widespread effort to detect and prevent them. Recent work attempts to mitigate hallucinations by intervening in the model's computation during generation, using different setups and heuristics. Those works lack separation between different hallucination causes. In this work, we first introduce an approach for constructing datasets based on the model knowledge for detection and intervention methods in closed-book and open-book question-answering settings. We then characterize the effect of different choices for intervention, such as the intervened components (MLPs, attention block, residual stream, and specific heads), and how often and how strongly to intervene. We find that intervention success varies depending on the component, with some components being detrimental to language modeling capabilities. Finally, we find that interventions can benefit from pre-hallucination steering direction instead of post-hallucination. The code is available at https://github.com/technion-cs-nlp/hallucination-mitigation
Create account to get full access
Overview
- Constructing Benchmarks and Interventions for Combating Hallucinations in Large Language Models (LLMs)
- Addresses the challenge of hallucination, where LLMs generate plausible-sounding but factually incorrect information
- Proposes methods to detect and mitigate hallucinations, including benchmark datasets and model interventions
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly sophisticated at generating human-like text. However, they can also sometimes produce "hallucinations" - information that sounds convincing but is factually incorrect. This paper explores ways to tackle this challenge.
The researchers first describe a "mitigation setup" where they aim to detect and reduce hallucinations in LLMs. They create new benchmark datasets to test a model's ability to distinguish factual from fabricated information. They also experiment with model interventions, such as adding prompts or fine-tuning, to improve a model's reliability.
Through their experiments, the researchers gain insights into the nature of hallucinations and how to build more trustworthy language models. This work could lead to significant improvements in the safety and reliability of LLMs as they become more widely deployed in real-world applications.
Technical Explanation
The paper proposes a "mitigation setup" to address the problem of hallucinations in LLMs. This involves creating specialized benchmark datasets to evaluate a model's ability to distinguish factual from fabricated information, as well as exploring model interventions to reduce hallucinations.
The researchers construct several new benchmark datasets, including Don't Believe Everything You Read: Enhancing Summarization with Fact-Checking, Hallucinations Leaderboard: An Open Effort to Measure Hallucinations, and Hallucination Diversity-Aware Active Learning for Text Summarization. These datasets test an LLM's ability to distinguish factual claims from fabricated ones.
The paper also explores various model interventions, such as prompting techniques and fine-tuning, to reduce hallucinations. For example, the researchers investigate Large Language Models and Hallucinations: Regard to Known and SLPL Shroom at SemEval-2024 Task 06: A Comprehensive Approach as potential mitigation strategies.
Through these experiments, the researchers gain important insights into the nature of hallucinations and how to build more reliable and trustworthy language models.
Critical Analysis
The paper makes a valuable contribution by addressing the critical issue of hallucinations in LLMs. The proposed mitigation setup, including the new benchmark datasets and model interventions, represents a significant step forward in tackling this challenge.
However, the paper also acknowledges several limitations and areas for further research. For example, the benchmark datasets may not capture the full complexity and diversity of hallucinations encountered in real-world applications. Additionally, the model interventions explored, while showing promise, may not be sufficient to completely eliminate hallucinations.
Further research is needed to develop more comprehensive and robust solutions to the hallucination problem. This could involve exploring additional benchmark datasets, investigating more advanced model architectures and training techniques, and studying the underlying causes of hallucinations in greater depth.
Conclusion
This paper presents a comprehensive approach to addressing the crucial issue of hallucinations in large language models. By constructing specialized benchmark datasets and exploring various model interventions, the researchers have made important progress in detecting and mitigating this challenge.
The insights gained from this work could have far-reaching implications for the development of more reliable and trustworthy language models, which are essential for the safe and responsible deployment of these technologies in real-world applications. Continued research in this area is crucial to ensure that LLMs can be leveraged to their full potential while maintaining high standards of accuracy and reliability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
0
0
This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
4/30/2024

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024

Don't Believe Everything You Read: Enhancing Summarization Interpretability through Automatic Identification of Hallucinations in Large Language Models
Priyesh Vakharia, Devavrat Joshi, Meenal Chavan, Dhananjay Sonawane, Bhrigu Garg, Parsa Mazaheri
0
0
Large Language Models (LLMs) are adept at text manipulation -- tasks such as machine translation and text summarization. However, these models can also be prone to hallucination, which can be detrimental to the faithfulness of any answers that the model provides. Recent works in combating hallucinations in LLMs deal with identifying hallucinated sentences and categorizing the different ways in which models hallucinate. This paper takes a deep dive into LLM behavior with respect to hallucinations, defines a token-level approach to identifying different kinds of hallucinations, and further utilizes this token-level tagging to improve the interpretability and faithfulness of LLMs in dialogue summarization tasks. Through this, the paper presents a new, enhanced dataset and a new training paradigm.
4/4/2024
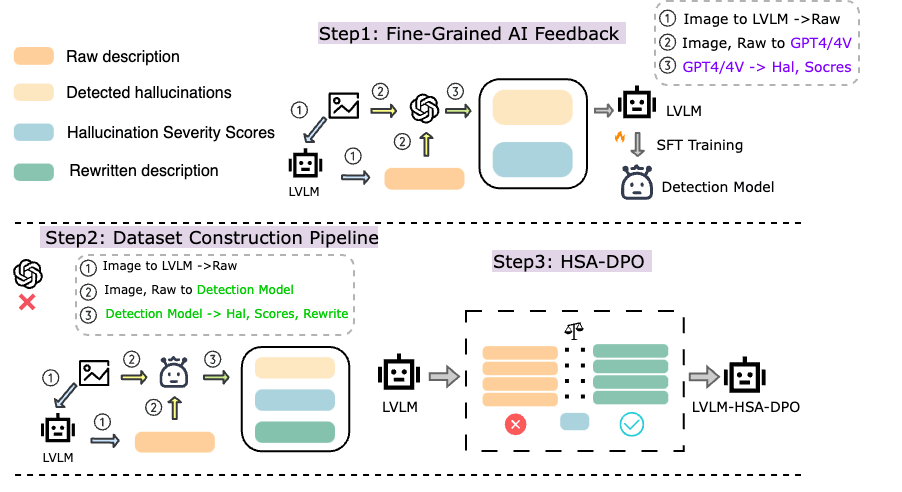
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
0
0
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
4/23/2024