Detection of financial opportunities in micro-blogging data with a stacked classification system
2404.07224
0
0
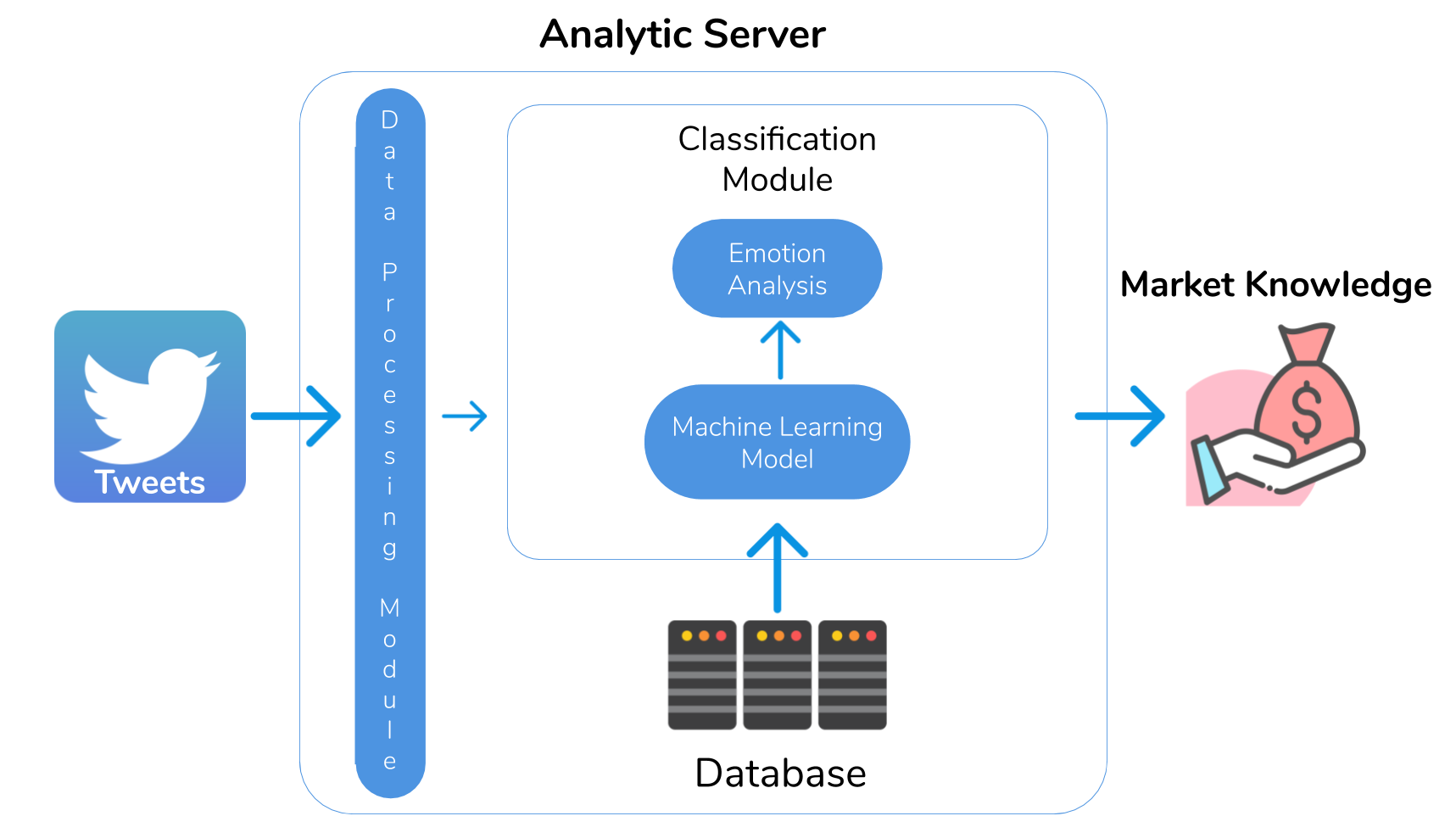
Abstract
Micro-blogging sources such as the Twitter social network provide valuable real-time data for market prediction models. Investors' opinions in this network follow the fluctuations of the stock markets and often include educated speculations on market opportunities that may have impact on the actions of other investors. In view of this, we propose a novel system to detect positive predictions in tweets, a type of financial emotions which we term opportunities that are akin to anticipation in Plutchik's theory. Specifically, we seek a high detection precision to present a financial operator a substantial amount of such tweets while differentiating them from the rest of financial emotions in our system. We achieve it with a three-layer stacked Machine Learning classification system with sophisticated features that result from applying Natural Language Processing techniques to extract valuable linguistic information. Experimental results on a dataset that has been manually annotated with financial emotion and ticker occurrence tags demonstrate that our system yields satisfactory and competitive performance in financial opportunity detection, with precision values up to 83%. This promising outcome endorses the usability of our system to support investors' decision making.
Create account to get full access
Overview
- The paper focuses on detecting financial opportunities from micro-blogging data using a stacked classification system.
- It explores the potential of leveraging sentiment and emotion analysis of social media posts to identify promising investment opportunities.
- The research aims to develop an automated system that can effectively detect and extract valuable financial information from large-scale micro-blogging data.
Plain English Explanation
The researchers in this study are interested in finding ways to uncover promising financial opportunities by analyzing the content of social media posts, specifically on micro-blogging platforms like Twitter. They believe that the sentiment and emotional tone expressed in these posts can provide valuable insights into the public's perception of companies, products, or market trends.
By developing a stacked classification system, the researchers seek to create an automated system that can efficiently process large volumes of micro-blogging data and identify potential financial opportunities that may not be immediately obvious to individual investors or analysts. This could help investors make more informed decisions and potentially identify profitable investment opportunities earlier than they might have otherwise.
Technical Explanation
The paper presents a stacked classification system that combines various machine learning models to detect financial opportunities from micro-blogging data. The system first employs emotion recognition and sentiment analysis techniques to extract relevant features from the micro-blog posts. These features are then used to train a series of classifiers, which are then stacked together to make the final prediction.
The researchers evaluate the performance of their system on a dataset of micro-blog posts related to the financial market. They compare the results of their stacked classification approach to individual classifiers and demonstrate the enhanced performance of the combined system in accurately identifying financial opportunities.
Critical Analysis
The paper presents a novel and potentially promising approach to leveraging micro-blogging data for financial decision-making. However, the researchers acknowledge several limitations and areas for further research.
One key limitation is the reliance on a single dataset of micro-blog posts, which may not be fully representative of the broader social media landscape. Additionally, the researchers note that the interpretation of emotional and sentiment-based features from micro-blog posts can be challenging and may require more advanced natural language processing techniques.
Further research could explore the generalizability of the proposed system to other financial domains, as well as the potential integration of additional data sources, such as news articles or financial reports, to enhance the system's predictive capabilities.
Conclusion
The paper presents a novel approach to detecting financial opportunities from micro-blogging data using a stacked classification system. By combining sentiment and emotion analysis with machine learning, the researchers demonstrate the potential of leveraging social media data to identify promising investment opportunities.
While the study has limitations, it highlights the growing importance of social media analytics in the financial domain and the potential for further advancements in this area. The research findings could inspire further exploration and development of automated systems that can assist investors and financial professionals in making more informed decisions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
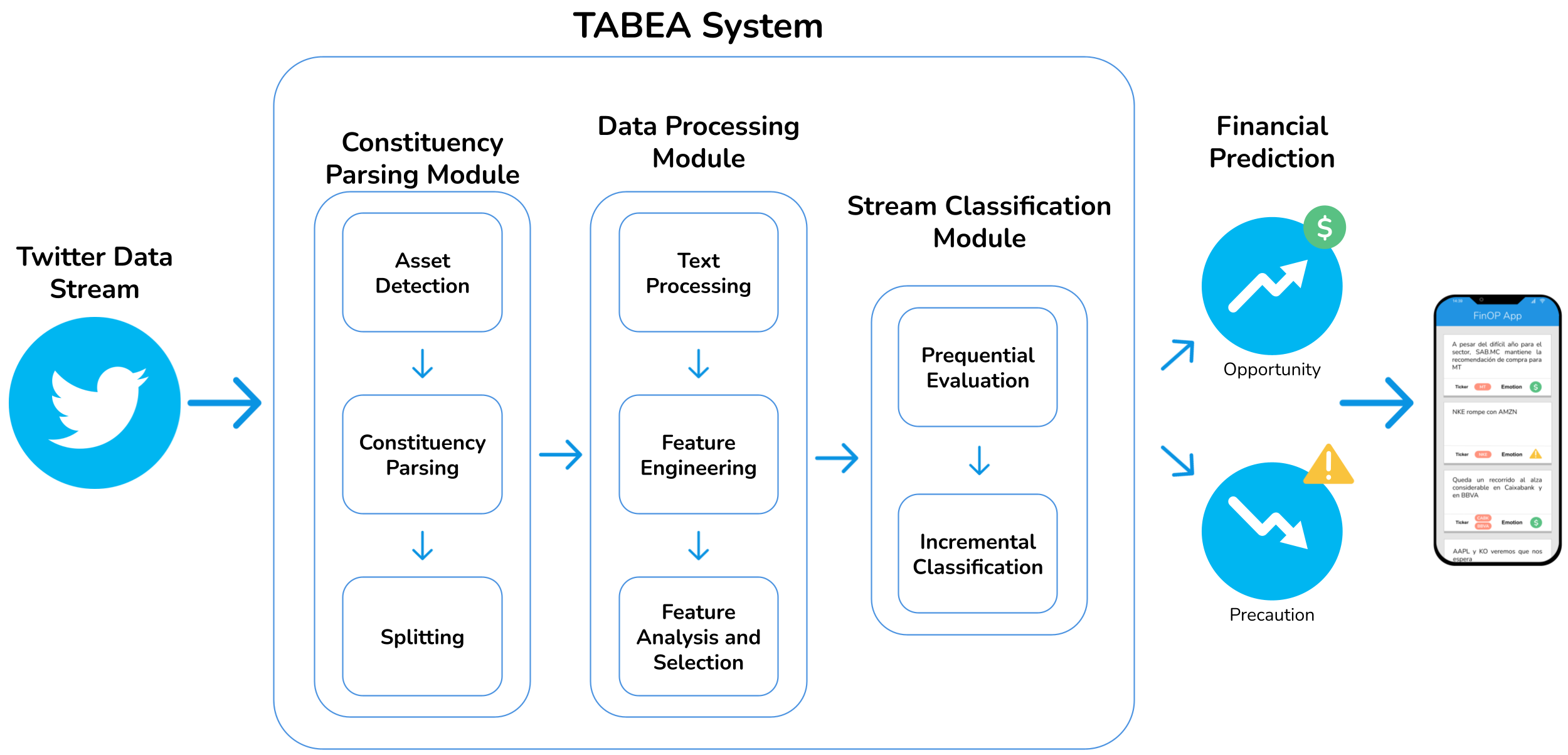
Targeted aspect-based emotion analysis to detect opportunities and precaution in financial Twitter messages
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Ana Barros-Vila, Francisco J. Gonz'alez-Casta~no
0
0
Microblogging platforms, of which Twitter is a representative example, are valuable information sources for market screening and financial models. In them, users voluntarily provide relevant information, including educated knowledge on investments, reacting to the state of the stock markets in real-time and, often, influencing this state. We are interested in the user forecasts in financial, social media messages expressing opportunities and precautions about assets. We propose a novel Targeted Aspect-Based Emotion Analysis (TABEA) system that can individually discern the financial emotions (positive and negative forecasts) on the different stock market assets in the same tweet (instead of making an overall guess about that whole tweet). It is based on Natural Language Processing (NLP) techniques and Machine Learning streaming algorithms. The system comprises a constituency parsing module for parsing the tweets and splitting them into simpler declarative clauses; an offline data processing module to engineer textual, numerical and categorical features and analyse and select them based on their relevance; and a stream classification module to continuously process tweets on-the-fly. Experimental results on a labelled data set endorse our solution. It achieves over 90% precision for the target emotions, financial opportunity, and precaution on Twitter. To the best of our knowledge, no prior work in the literature has addressed this problem despite its practical interest in decision-making, and we are not aware of any previous NLP nor online Machine Learning approaches to TABEA.
4/16/2024
BERTopic-Driven Stock Market Predictions: Unraveling Sentiment Insights
Enmin Zhu, Jerome Yen
0
0
This paper explores the intersection of Natural Language Processing (NLP) and financial analysis, focusing on the impact of sentiment analysis in stock price prediction. We employ BERTopic, an advanced NLP technique, to analyze the sentiment of topics derived from stock market comments. Our methodology integrates this sentiment analysis with various deep learning models, renowned for their effectiveness in time series and stock prediction tasks. Through comprehensive experiments, we demonstrate that incorporating topic sentiment notably enhances the performance of these models. The results indicate that topics in stock market comments provide implicit, valuable insights into stock market volatility and price trends. This study contributes to the field by showcasing the potential of NLP in enriching financial analysis and opens up avenues for further research into real-time sentiment analysis and the exploration of emotional and contextual aspects of market sentiment. The integration of advanced NLP techniques like BERTopic with traditional financial analysis methods marks a step forward in developing more sophisticated tools for understanding and predicting market behaviors.
4/5/2024
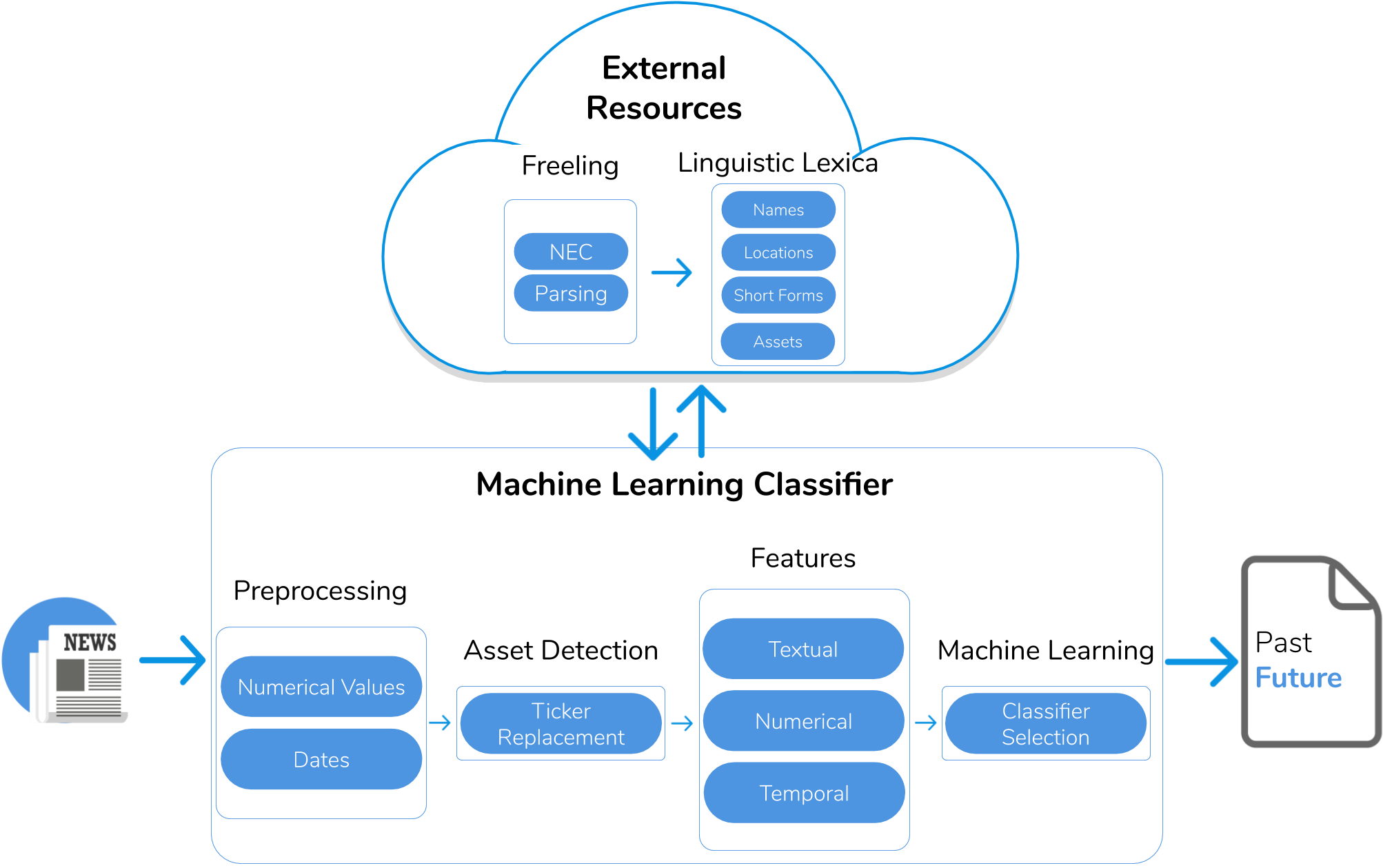
Detection of Temporality at Discourse Level on Financial News by Combining Natural Language Processing and Machine Learning
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Ana Barros-Vila, Francisco J. Gonz'alez-Casta~no
0
0
Finance-related news such as Bloomberg News, CNN Business and Forbes are valuable sources of real data for market screening systems. In news, an expert shares opinions beyond plain technical analyses that include context such as political, sociological and cultural factors. In the same text, the expert often discusses the performance of different assets. Some key statements are mere descriptions of past events while others are predictions. Therefore, understanding the temporality of the key statements in a text is essential to separate context information from valuable predictions. We propose a novel system to detect the temporality of finance-related news at discourse level that combines Natural Language Processing and Machine Learning techniques, and exploits sophisticated features such as syntactic and semantic dependencies. More specifically, we seek to extract the dominant tenses of the main statements, which may be either explicit or implicit. We have tested our system on a labelled dataset of finance-related news annotated by researchers with knowledge in the field. Experimental results reveal a high detection precision compared to an alternative rule-based baseline approach. Ultimately, this research contributes to the state-of-the-art of market screening by identifying predictive knowledge for financial decision making.
4/3/2024
🔎
Automatic detection of relevant information, predictions and forecasts in financial news through topic modelling with Latent Dirichlet Allocation
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Ana Barros-Vila, Francisco J. Gonz'alez-Casta~no, Enrique Costa-Montenegro
0
0
Financial news items are unstructured sources of information that can be mined to extract knowledge for market screening applications. Manual extraction of relevant information from the continuous stream of finance-related news is cumbersome and beyond the skills of many investors, who, at most, can follow a few sources and authors. Accordingly, we focus on the analysis of financial news to identify relevant text and, within that text, forecasts and predictions. We propose a novel Natural Language Processing (NLP) system to assist investors in the detection of relevant financial events in unstructured textual sources by considering both relevance and temporality at the discursive level. Firstly, we segment the text to group together closely related text. Secondly, we apply co-reference resolution to discover internal dependencies within segments. Finally, we perform relevant topic modelling with Latent Dirichlet Allocation (LDA) to separate relevant from less relevant text and then analyse the relevant text using a Machine Learning-oriented temporal approach to identify predictions and speculative statements. We created an experimental data set composed of 2,158 financial news items that were manually labelled by NLP researchers to evaluate our solution. The ROUGE-L values for the identification of relevant text and predictions/forecasts were 0.662 and 0.982, respectively. To our knowledge, this is the first work to jointly consider relevance and temporality at the discursive level. It contributes to the transfer of human associative discourse capabilities to expert systems through the combination of multi-paragraph topic segmentation and co-reference resolution to separate author expression patterns, topic modelling with LDA to detect relevant text, and discursive temporality analysis to identify forecasts and predictions within this text.
4/3/2024