Deterministic Policy Gradient Primal-Dual Methods for Continuous-Space Constrained MDPs

0
Sign in to get full access
Overview
- This paper proposes a new algorithm for solving continuous-space constrained Markov Decision Processes (MDPs).
- The algorithm combines deterministic policy gradient and primal-dual methods to learn an optimal policy that satisfies constraints.
- The authors provide theoretical guarantees for the algorithm's convergence and constraint satisfaction.
- Experiments on several benchmark tasks demonstrate the algorithm's effectiveness compared to prior methods.
Plain English Explanation
The paper addresses the problem of reinforcement learning in continuous-space environments where there are constraints on the agent's behavior. For example, a robot navigating an environment might need to avoid obstacles or maintain a certain level of battery life.
The authors introduce a new algorithm that combines two powerful techniques: deterministic policy gradient and primal-dual optimization. The deterministic policy gradient method allows the algorithm to learn an optimal control policy that maximizes the agent's long-term reward. The primal-dual approach ensures that the learned policy satisfies the given constraints, such as keeping the robot within safe boundaries.
The key insight is that by jointly optimizing the policy and the Lagrange multipliers (which encode the constraint violations), the algorithm can find a solution that is both optimal and feasible. The authors provide theoretical guarantees showing that their method will converge to such an optimal and constraint-satisfying policy.
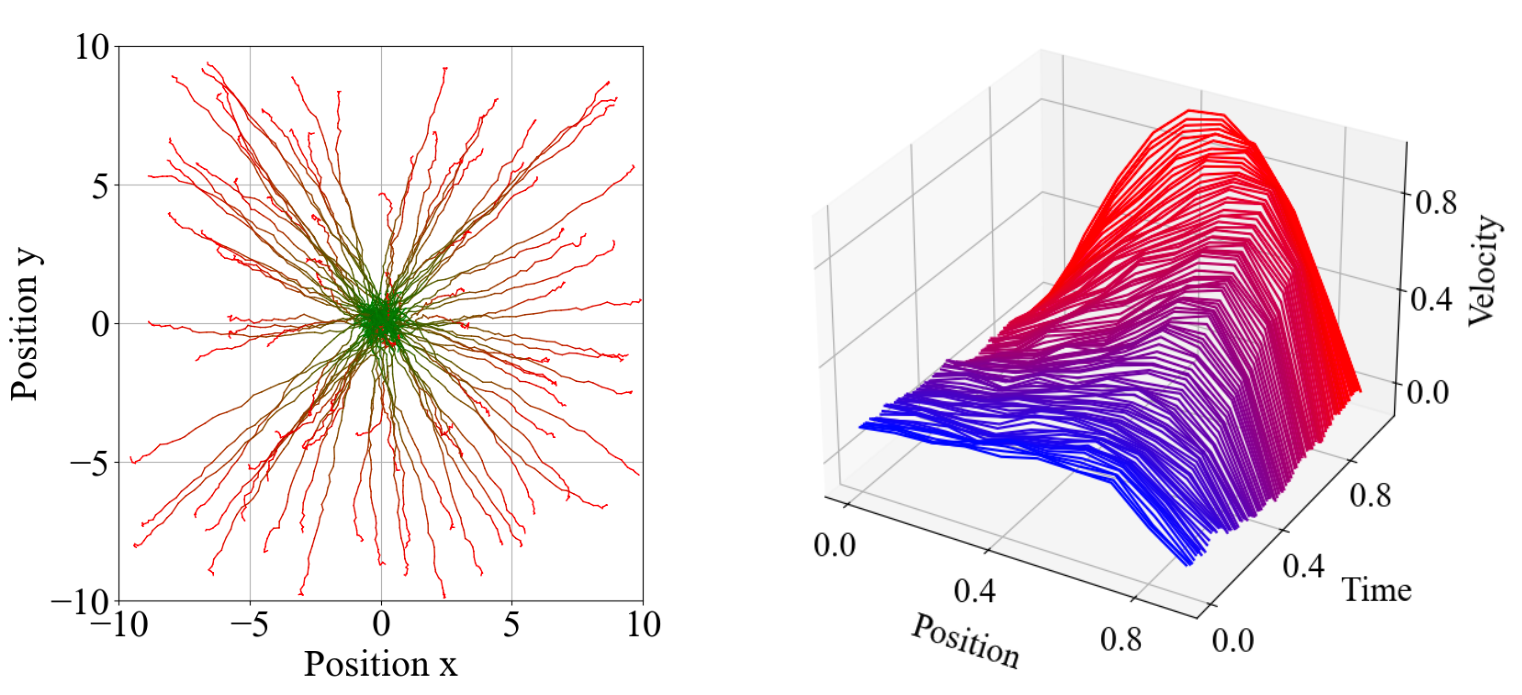
To demonstrate the effectiveness of their approach, the researchers evaluate the algorithm on several benchmark tasks, including classic control problems like inverted pendulum and cart-pole balancing. The results show that their method outperforms previous approaches in terms of both reward maximization and constraint satisfaction.
Technical Explanation
The paper formally defines the continuous-space constrained MDP problem, where the agent's state and action spaces are continuous, and there are constraints on the agent's behavior that must be satisfied.
The authors then propose a deterministic policy gradient primal-dual (DPGPD) algorithm to solve this problem. The key steps are:
- Policy gradient update: The algorithm performs a gradient descent step to update the policy parameters in the direction that maximizes the expected reward.
- Primal-dual update: Simultaneously, the algorithm updates the Lagrange multipliers (dual variables) associated with the constraints. This encourages the policy to satisfy the constraints.
- Alternating optimization: The policy gradient and primal-dual updates are performed in alternation, allowing the algorithm to converge to an optimal and feasible solution.
The authors provide theoretical analysis showing that under certain assumptions, the DPGPD algorithm is guaranteed to converge to a stationary point that satisfies the constraints. They also derive bounds on the constraint violation and the sub-optimality of the learned policy.
In the experimental evaluation, the algorithm is tested on several continuous control tasks with state and action constraints, such as cart-pole balancing and quadrotor control. The results demonstrate that DPGPD outperforms previous methods like constrained policy optimization and primal-dual policy gradient in terms of both reward maximization and constraint satisfaction.
Critical Analysis
The paper presents a well-designed and theoretically-grounded algorithm for solving continuous-space constrained MDPs. The authors have carefully analyzed the convergence properties of their method and provided strong theoretical guarantees.
One potential limitation is that the assumptions required for the theoretical analysis, such as the smoothness and convexity of the reward and constraint functions, may not always hold in real-world applications. It would be interesting to see how the algorithm performs when these assumptions are relaxed.
Additionally, the experiments are conducted on relatively simple benchmark tasks, and it remains to be seen how the method would scale to more complex, high-dimensional problems. Further research is needed to understand the practical limitations and potential bottlenecks of the DPGPD algorithm.
Another area for future work could be exploring the sensitivity of the method to the hyperparameters, such as the step sizes and the initialization of the Lagrange multipliers. Understanding how to best tune these parameters could improve the algorithm's robustness and reliability.
Overall, this paper presents a promising approach to solving continuous-space constrained MDPs and opens up exciting avenues for further research and development in this domain.
Conclusion
This paper introduces a new deterministic policy gradient primal-dual (DPGPD) algorithm for solving continuous-space constrained Markov Decision Processes (MDPs). The algorithm combines deterministic policy gradient and primal-dual optimization to learn an optimal policy that satisfies the given constraints.
The authors provide theoretical guarantees for the algorithm's convergence and constraint satisfaction, and demonstrate its empirical effectiveness through experiments on several benchmark tasks. The results show that DPGPD outperforms previous methods in terms of both reward maximization and constraint satisfaction.
This work represents an important contribution to the field of reinforcement learning with constraints, which is crucial for developing safe and reliable autonomous systems that can operate in complex, real-world environments. The insights and techniques presented in this paper can inspire further advancements in this area and pave the way for more practical and impactful applications of constrained reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deterministic Policy Gradient Primal-Dual Methods for Continuous-Space Constrained MDPs
Sergio Rozada, Dongsheng Ding, Antonio G. Marques, Alejandro Ribeiro
We study the problem of computing deterministic optimal policies for constrained Markov decision processes (MDPs) with continuous state and action spaces, which are widely encountered in constrained dynamical systems. Designing deterministic policy gradient methods in continuous state and action spaces is particularly challenging due to the lack of enumerable state-action pairs and the adoption of deterministic policies, hindering the application of existing policy gradient methods for constrained MDPs. To this end, we develop a deterministic policy gradient primal-dual method to find an optimal deterministic policy with non-asymptotic convergence. Specifically, we leverage regularization of the Lagrangian of the constrained MDP to propose a deterministic policy gradient primal-dual (D-PGPD) algorithm that updates the deterministic policy via a quadratic-regularized gradient ascent step and the dual variable via a quadratic-regularized gradient descent step. We prove that the primal-dual iterates of D-PGPD converge at a sub-linear rate to an optimal regularized primal-dual pair. We instantiate D-PGPD with function approximation and prove that the primal-dual iterates of D-PGPD converge at a sub-linear rate to an optimal regularized primal-dual pair, up to a function approximation error. Furthermore, we demonstrate the effectiveness of our method in two continuous control problems: robot navigation and fluid control. To the best of our knowledge, this appears to be the first work that proposes a deterministic policy search method for continuous-space constrained MDPs.
Read more8/20/2024
🌿
0
Convergence and sample complexity of natural policy gradient primal-dual methods for constrained MDPs
Dongsheng Ding, Kaiqing Zhang, Jiali Duan, Tamer Bac{s}ar, Mihailo R. Jovanovi'c
We study sequential decision making problems aimed at maximizing the expected total reward while satisfying a constraint on the expected total utility. We employ the natural policy gradient method to solve the discounted infinite-horizon optimal control problem for Constrained Markov Decision Processes (constrained MDPs). Specifically, we propose a new Natural Policy Gradient Primal-Dual (NPG-PD) method that updates the primal variable via natural policy gradient ascent and the dual variable via projected sub-gradient descent. Although the underlying maximization involves a nonconcave objective function and a nonconvex constraint set, under the softmax policy parametrization we prove that our method achieves global convergence with sublinear rates regarding both the optimality gap and the constraint violation. Such convergence is independent of the size of the state-action space, i.e., it is~dimension-free. Furthermore, for log-linear and general smooth policy parametrizations, we establish sublinear convergence rates up to a function approximation error caused by restricted policy parametrization. We also provide convergence and finite-sample complexity guarantees for two sample-based NPG-PD algorithms. Finally, we use computational experiments to showcase the merits and the effectiveness of our approach.
Read more8/30/2024
🔍
0
A Policy Gradient Primal-Dual Algorithm for Constrained MDPs with Uniform PAC Guarantees
Toshinori Kitamura, Tadashi Kozuno, Masahiro Kato, Yuki Ichihara, Soichiro Nishimori, Akiyoshi Sannai, Sho Sonoda, Wataru Kumagai, Yutaka Matsuo
We study a primal-dual (PD) reinforcement learning (RL) algorithm for online constrained Markov decision processes (CMDPs). Despite its widespread practical use, the existing theoretical literature on PD-RL algorithms for this problem only provides sublinear regret guarantees and fails to ensure convergence to optimal policies. In this paper, we introduce a novel policy gradient PD algorithm with uniform probably approximate correctness (Uniform-PAC) guarantees, simultaneously ensuring convergence to optimal policies, sublinear regret, and polynomial sample complexity for any target accuracy. Notably, this represents the first Uniform-PAC algorithm for the online CMDP problem. In addition to the theoretical guarantees, we empirically demonstrate in a simple CMDP that our algorithm converges to optimal policies, while baseline algorithms exhibit oscillatory performance and constraint violation.
Read more7/2/2024
🏅
0
Achieving Zero Constraint Violation for Constrained Reinforcement Learning via Conservative Natural Policy Gradient Primal-Dual Algorithm
Qinbo Bai, Amrit Singh Bedi, Vaneet Aggarwal
We consider the problem of constrained Markov decision process (CMDP) in continuous state-actions spaces where the goal is to maximize the expected cumulative reward subject to some constraints. We propose a novel Conservative Natural Policy Gradient Primal-Dual Algorithm (C-NPG-PD) to achieve zero constraint violation while achieving state of the art convergence results for the objective value function. For general policy parametrization, we prove convergence of value function to global optimal upto an approximation error due to restricted policy class. We even improve the sample complexity of existing constrained NPG-PD algorithm cite{Ding2020} from $mathcal{O}(1/epsilon^6)$ to $mathcal{O}(1/epsilon^4)$. To the best of our knowledge, this is the first work to establish zero constraint violation with Natural policy gradient style algorithms for infinite horizon discounted CMDPs. We demonstrate the merits of proposed algorithm via experimental evaluations.
Read more5/20/2024