Deterministic Reversible Data Augmentation for Neural Machine Translation

0

Sign in to get full access
Overview
- This paper introduces a new data augmentation technique called Deterministic Reversible Data Augmentation (DRDA) for improving the performance of neural machine translation (NMT) models.
- DRDA is a deterministic and reversible approach that applies transformations to the input sentences in a way that can be undone during inference, preserving the original meaning.
- The authors demonstrate that DRDA can significantly improve the performance of NMT models on several language pairs, outperforming traditional data augmentation techniques.
Plain English Explanation
The paper discusses a new way to improve the performance of neural machine translation (NMT) models, which are used to automatically translate text from one language to another. The key idea is to apply a series of transformations to the input sentences that can be easily reversed during the translation process.
For example, the system might rearrange the words in a sentence or substitute certain words with synonyms. These changes are made in a deterministic way, meaning they can be precisely undone later on. This allows the model to learn from a larger and more diverse set of training examples without introducing ambiguity or changing the original meaning of the sentences.
The authors show that this Deterministic Reversible Data Augmentation (DRDA) technique leads to significant improvements in translation quality across multiple language pairs, outperforming traditional data augmentation methods. This is an important advance, as data augmentation is a widely used technique for improving the performance of NMT and other deep learning models.
Technical Explanation
The paper introduces a new data augmentation technique called Deterministic Reversible Data Augmentation (DRDA) for improving neural machine translation (NMT) models. DRDA applies a series of deterministic and reversible transformations to the input sentences, such as word reordering, word substitution, and sentence splitting/merging.
These transformations are designed to be easily inverted, so that the original sentence can be recovered during inference. This allows the NMT model to learn from a larger and more diverse set of training examples without introducing ambiguity or changing the original meaning of the sentences.
The authors evaluate DRDA on several language pairs, including English-German, English-French, and English-Chinese. They show that DRDA significantly outperforms traditional data augmentation techniques, such as back-translation and word dropout, in terms of translation quality as measured by BLEU score.
The key insight behind DRDA is that by making the transformations deterministic and reversible, the model can learn robust representations that generalize better to unseen data. The authors also provide an analysis of the types of transformations that are most effective for different language pairs, suggesting that the optimal augmentation strategy may depend on the specific characteristics of the language pair.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the DRDA technique, with experiments on multiple language pairs and comparisons to several baseline methods. The results demonstrate the effectiveness of DRDA in improving NMT performance, which is an important contribution to the field.
However, the paper does not address some potential limitations or areas for further research. For example, the authors do not explore the scalability of DRDA to very large datasets or the computational overhead of applying the reversible transformations during inference. Additionally, the paper does not discuss the potential for the DRDA technique to be extended to other natural language processing tasks beyond machine translation.
Furthermore, while the authors provide some analysis of the transformation types that are most effective, there is scope for deeper investigation into the underlying reasons why certain transformations work better than others. Understanding these factors could lead to further refinements and improvements to the DRDA approach.
Overall, the paper presents a compelling and well-executed study on a novel data augmentation technique for NMT. The DRDA approach shows promise and warrants further exploration and development by the research community.
Conclusion
This paper introduces a new data augmentation technique called Deterministic Reversible Data Augmentation (DRDA) that can significantly improve the performance of neural machine translation (NMT) models. The key idea behind DRDA is to apply a series of deterministic and reversible transformations to the input sentences, which allows the model to learn from a larger and more diverse set of training examples without introducing ambiguity or changing the original meaning.
The authors demonstrate the effectiveness of DRDA through extensive experiments on multiple language pairs, showing that it outperforms traditional data augmentation techniques. This is an important advance, as data augmentation is a widely used technique for improving the performance of NMT and other deep learning models.
While the paper presents a well-designed and thorough evaluation, there are some potential limitations and areas for further research, such as the scalability of DRDA and the exploration of additional transformation types. Nonetheless, the DRDA approach represents a significant contribution to the field of machine translation and could inspire further innovations in data augmentation techniques for natural language processing tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deterministic Reversible Data Augmentation for Neural Machine Translation
Jiashu Yao, Heyan Huang, Zeming Liu, Yuhang Guo
Data augmentation is an effective way to diversify corpora in machine translation, but previous methods may introduce semantic inconsistency between original and augmented data because of irreversible operations and random subword sampling procedures. To generate both symbolically diverse and semantically consistent augmentation data, we propose Deterministic Reversible Data Augmentation (DRDA), a simple but effective data augmentation method for neural machine translation. DRDA adopts deterministic segmentations and reversible operations to generate multi-granularity subword representations and pulls them closer together with multi-view techniques. With no extra corpora or model changes required, DRDA outperforms strong baselines on several translation tasks with a clear margin (up to 4.3 BLEU gain over Transformer) and exhibits good robustness in noisy, low-resource, and cross-domain datasets.
Read more6/5/2024
0
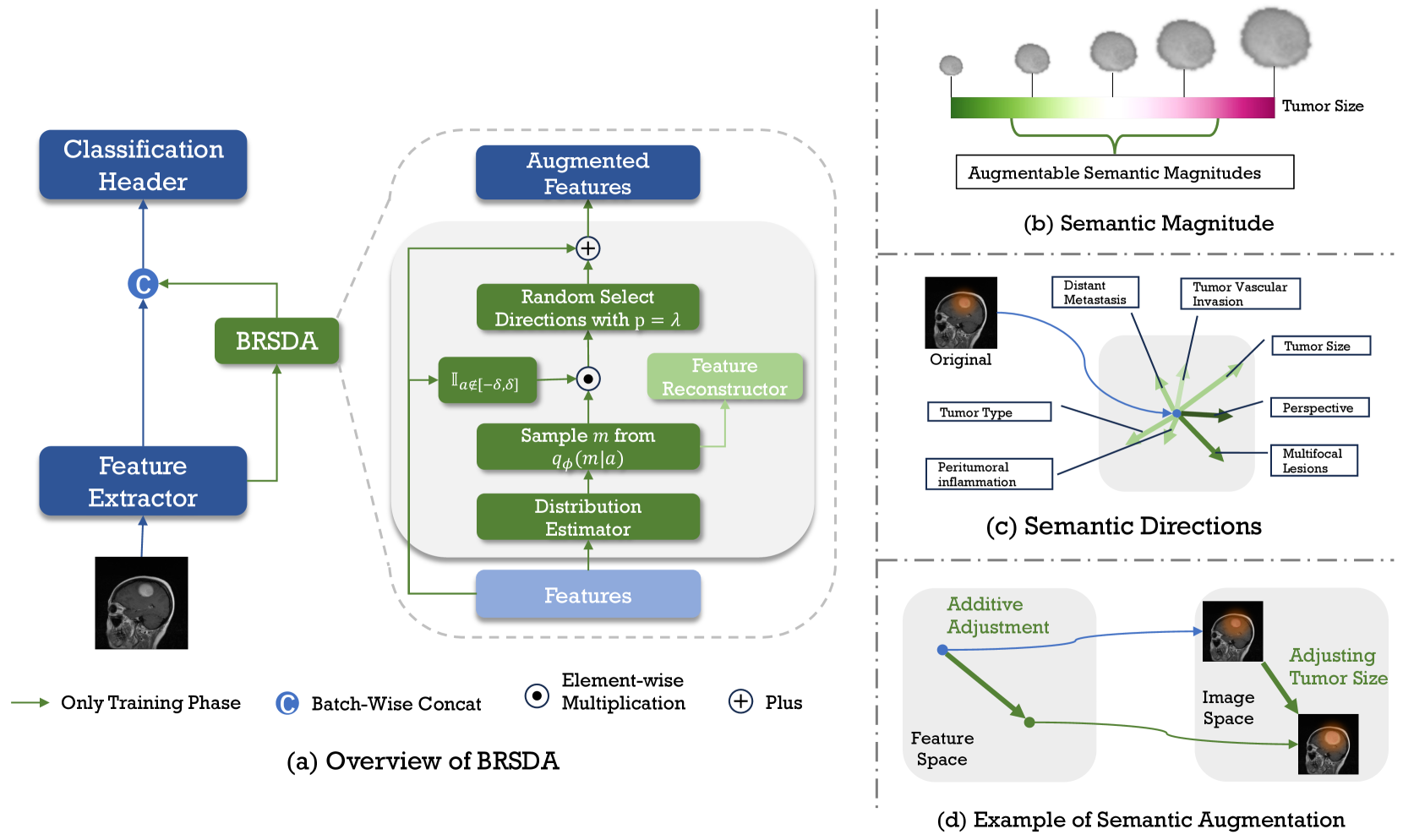
BSDA: Bayesian Random Semantic Data Augmentation for Medical Image Classification
Yaoyao Zhu, Xiuding Cai, Xueyao Wang, Xiaoqing Chen, Yu Yao, Zhongliang Fu
Data augmentation is a crucial regularization technique for deep neural networks, particularly in medical image classification. Mainstream data augmentation (DA) methods are usually applied at the image level. Due to the specificity and diversity of medical imaging, expertise is often required to design effective DA strategies, and improper augmentation operations can degrade model performance. Although automatic augmentation methods exist, they are computationally intensive. Semantic data augmentation can implemented by translating features in feature space. However, over-translation may violate the image label. To address these issues, we propose emph{Bayesian Random Semantic Data Augmentation} (BSDA), a computationally efficient and handcraft-free feature-level DA method. BSDA uses variational Bayesian to estimate the distribution of the augmentable magnitudes, and then a sample from this distribution is added to the original features to perform semantic data augmentation. We performed experiments on nine 2D and five 3D medical image datasets. Experimental results show that BSDA outperforms current DA methods. Additionally, BSDA can be easily assembled into CNNs or Transformers as a plug-and-play module, improving the network's performance. The code is available online at url{https://github.com/YaoyaoZhu19/BSDA}.
Read more6/28/2024

0
On Evaluation Protocols for Data Augmentation in a Limited Data Scenario
Fr'ed'eric Piedboeuf, Philippe Langlais
Textual data augmentation (DA) is a prolific field of study where novel techniques to create artificial data are regularly proposed, and that has demonstrated great efficiency on small data settings, at least for text classification tasks. In this paper, we challenge those results, showing that classical data augmentation (which modify sentences) is simply a way of performing better fine-tuning, and that spending more time doing so before applying data augmentation negates its effect. This is a significant contribution as it answers several questions that were left open in recent years, namely~: which DA technique performs best (all of them as long as they generate data close enough to the training set, as to not impair training) and why did DA show positive results (facilitates training of network). We further show that zero- and few-shot DA via conversational agents such as ChatGPT or LLama2 can increase performances, confirming that this form of data augmentation is preferable to classical methods.
Read more9/18/2024
🎲
0
SDA: Simple Discrete Augmentation for Contrastive Sentence Representation Learning
Dongsheng Zhu, Zhenyu Mao, Jinghui Lu, Rui Zhao, Fei Tan
Contrastive learning has recently achieved compelling performance in unsupervised sentence representation. As an essential element, data augmentation protocols, however, have not been well explored. The pioneering work SimCSE resorting to a simple dropout mechanism (viewed as continuous augmentation) surprisingly dominates discrete augmentations such as cropping, word deletion, and synonym replacement as reported. To understand the underlying rationales, we revisit existing approaches and attempt to hypothesize the desiderata of reasonable data augmentation methods: balance of semantic consistency and expression diversity. We then develop three simple yet effective discrete sentence augmentation schemes: punctuation insertion, modal verbs, and double negation. They act as minimal noises at lexical level to produce diverse forms of sentences. Furthermore, standard negation is capitalized on to generate negative samples for alleviating feature suppression involved in contrastive learning. We experimented extensively with semantic textual similarity on diverse datasets. The results support the superiority of the proposed methods consistently. Our key code is available at https://github.com/Zhudongsheng75/SDA
Read more6/17/2024