Data Augmentation for Text-based Person Retrieval Using Large Language Models

0

Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) for data augmentation in text-based person retrieval tasks.
- The researchers leverage the ability of LLMs to generate diverse and coherent text to create augmented training data, which can improve the performance of person retrieval models.
- The proposed approach is evaluated on several benchmarks, demonstrating its effectiveness in boosting the accuracy of text-based person retrieval.
Plain English Explanation
The paper focuses on using large language models (LLMs) to improve the performance of systems that can find and retrieve information about specific people based on textual descriptions. LLMs are powerful AI models that can generate human-like text, and the researchers in this paper found a way to use them to create additional training data for person retrieval models.
Typically, training data for these types of systems is limited, as it can be time-consuming and expensive to gather and label large amounts of text about people. By using LLMs to generate new, realistic-sounding text samples about people, the researchers were able to expand the training data available, leading to better performance of the person retrieval models.
The researchers tested their approach on several standard benchmarks for text-based person retrieval, and the results showed that the models trained on the augmented data were able to retrieve the correct person more accurately than models trained on the original, limited data. This suggests that the LLM-generated text was effective at capturing the key information needed to identify and retrieve people based on textual descriptions.
Technical Explanation
The paper proposes a data augmentation approach for text-based person retrieval that leverages the capabilities of large language models (LLMs). The researchers first fine-tune an LLM on the target person retrieval dataset, allowing the model to learn the textual patterns and characteristics associated with the people in the dataset.
They then use this fine-tuned LLM to generate new, synthetic text samples about people, which are added to the original training data. This augmented dataset is used to train the person retrieval model, with the goal of improving its ability to match textual descriptions to the correct person.
The effectiveness of this approach is evaluated on several person retrieval benchmarks, including COCO-Person, VisualGenome-Person, and IMDB-Person. The results show that the person retrieval models trained on the augmented data outperform models trained on the original data, demonstrating the value of the LLM-based data augmentation. The augmented data helps the models better capture the textual characteristics associated with different people, leading to improved retrieval accuracy.
Critical Analysis
The paper presents a promising approach for addressing the data scarcity issue in text-based person retrieval tasks, but it also raises some potential concerns and areas for further research.
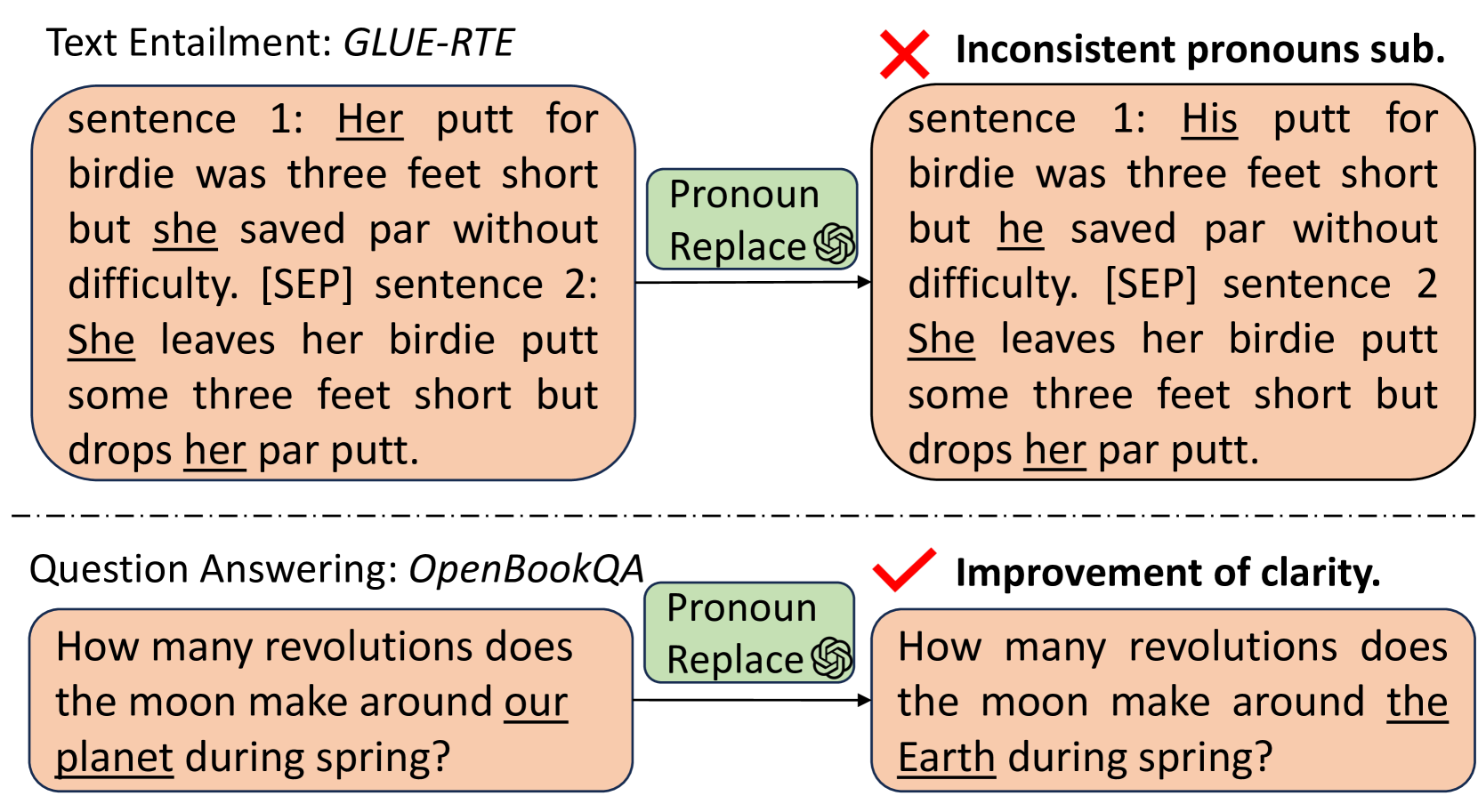
One limitation is that the quality and relevance of the LLM-generated text samples may vary depending on the initial fine-tuning of the LLM on the target dataset. If the fine-tuning process does not adequately capture the nuances and complexities of the people in the dataset, the generated text may not be as useful for improving the person retrieval model.
Additionally, the paper does not explore the impact of personalization on the LLM-based data augmentation. Personalizing the LLM to individual users or use cases could potentially lead to even more relevant and effective synthetic text samples.
Further research could also investigate the use of LLMs as a source of targeted, synthetic text for other text-based retrieval or understanding tasks, beyond just person retrieval.
Conclusion
This paper presents a novel approach to address the data scarcity challenge in text-based person retrieval by leveraging the power of large language models (LLMs) for data augmentation. The researchers demonstrate that using LLMs to generate synthetic text samples about people can effectively boost the performance of person retrieval models across multiple benchmark datasets.
The findings of this study highlight the potential of LLMs to serve as a versatile tool for enhancing the capabilities of text-based retrieval systems, particularly in domains where labeled data is scarce. The insights gained from this work could inspire further research into the applications of LLMs for data augmentation and the development of more robust and accurate text-based retrieval systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data Augmentation for Text-based Person Retrieval Using Large Language Models
Zheng Li, Lijia Si, Caili Guo, Yang Yang, Qiushi Cao
Text-based Person Retrieval (TPR) aims to retrieve person images that match the description given a text query. The performance improvement of the TPR model relies on high-quality data for supervised training. However, it is difficult to construct a large-scale, high-quality TPR dataset due to expensive annotation and privacy protection. Recently, Large Language Models (LLMs) have approached or even surpassed human performance on many NLP tasks, creating the possibility to expand high-quality TPR datasets. This paper proposes an LLM-based Data Augmentation (LLM-DA) method for TPR. LLM-DA uses LLMs to rewrite the text in the current TPR dataset, achieving high-quality expansion of the dataset concisely and efficiently. These rewritten texts are able to increase the diversity of vocabulary and sentence structure while retaining the original key concepts and semantic information. In order to alleviate the hallucinations of LLMs, LLM-DA introduces a Text Faithfulness Filter (TFF) to filter out unfaithful rewritten text. To balance the contributions of original text and augmented text, a Balanced Sampling Strategy (BSS) is proposed to control the proportion of original text and augmented text used for training. LLM-DA is a plug-and-play method that can be easily integrated into various TPR models. Comprehensive experiments on three TPR benchmarks show that LLM-DA can improve the retrieval performance of current TPR models.
Read more5/21/2024

0
Data Augmentation using LLMs: Data Perspectives, Learning Paradigms and Challenges
Bosheng Ding, Chengwei Qin, Ruochen Zhao, Tianze Luo, Xinze Li, Guizhen Chen, Wenhan Xia, Junjie Hu, Anh Tuan Luu, Shafiq Joty
In the rapidly evolving field of large language models (LLMs), data augmentation (DA) has emerged as a pivotal technique for enhancing model performance by diversifying training examples without the need for additional data collection. This survey explores the transformative impact of LLMs on DA, particularly addressing the unique challenges and opportunities they present in the context of natural language processing (NLP) and beyond. From both data and learning perspectives, we examine various strategies that utilize LLMs for data augmentation, including a novel exploration of learning paradigms where LLM-generated data is used for diverse forms of further training. Additionally, this paper highlights the primary open challenges faced in this domain, ranging from controllable data augmentation to multi-modal data augmentation. This survey highlights a paradigm shift introduced by LLMs in DA, and aims to serve as a comprehensive guide for researchers and practitioners.
Read more7/1/2024
0
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
Read more4/30/2024

0
On Evaluation Protocols for Data Augmentation in a Limited Data Scenario
Fr'ed'eric Piedboeuf, Philippe Langlais
Textual data augmentation (DA) is a prolific field of study where novel techniques to create artificial data are regularly proposed, and that has demonstrated great efficiency on small data settings, at least for text classification tasks. In this paper, we challenge those results, showing that classical data augmentation (which modify sentences) is simply a way of performing better fine-tuning, and that spending more time doing so before applying data augmentation negates its effect. This is a significant contribution as it answers several questions that were left open in recent years, namely~: which DA technique performs best (all of them as long as they generate data close enough to the training set, as to not impair training) and why did DA show positive results (facilitates training of network). We further show that zero- and few-shot DA via conversational agents such as ChatGPT or LLama2 can increase performances, confirming that this form of data augmentation is preferable to classical methods.
Read more9/18/2024