DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories
2405.19856
0
0

Abstract
How to evaluate the coding abilities of Large Language Models (LLMs) remains an open question. We find that existing benchmarks are poorly aligned with real-world code repositories and are insufficient to evaluate the coding abilities of LLMs. To address the knowledge gap, we propose a new benchmark named DevEval, which has three advances. (1) DevEval aligns with real-world repositories in multiple dimensions, e.g., code distributions and dependency distributions. (2) DevEval is annotated by 13 developers and contains comprehensive annotations (e.g., requirements, original repositories, reference code, and reference dependencies). (3) DevEval comprises 1,874 testing samples from 117 repositories, covering 10 popular domains (e.g., Internet, Database). Based on DevEval, we propose repository-level code generation and evaluate 8 popular LLMs on DevEval (e.g., gpt-4, gpt-3.5, StarCoder 2, DeepSeek Coder, CodeLLaMa). Our experiments reveal these LLMs' coding abilities in real-world code repositories. For example, in our experiments, the highest Pass@1 of gpt-4-turbo is only 53.04%. We also analyze LLMs' failed cases and summarize their shortcomings. We hope DevEval can facilitate the development of LLMs in real code repositories. DevEval, prompts, and LLMs' predictions have been released.
Create account to get full access
Overview
- The paper introduces DevEval, a new manually-annotated code generation benchmark that aims to better align with real-world code repositories.
- The benchmark includes a diverse set of programming tasks and challenges, with annotations that provide detailed insights into the code generation process.
- The authors compare the performance of large language models on DevEval against other popular benchmarks, highlighting the potential mismatch between model performance on artificial tasks and real-world coding challenges.
Plain English Explanation
The paper presents a new benchmark for evaluating code generation models, called DevEval. Unlike other benchmarks that may not fully capture the complexities of real-world coding, DevEval is designed to be more representative of the types of tasks and challenges that developers face in their day-to-day work.
The benchmark includes a wide range of programming tasks, such as fixing bugs, improving code efficiency, and adding new features. These tasks are annotated with detailed information about the thought process and reasoning behind the expected solutions. This allows researchers and developers to gain deeper insights into how code generation models approach and solve these problems, rather than just looking at the final output.
The authors compare the performance of large language models on DevEval to their performance on other popular benchmarks, such as HumanEval and CodeEditorBench. They find that there can be a significant mismatch between a model's performance on these artificial benchmarks and its ability to handle the more realistic challenges presented in DevEval. This highlights the importance of using benchmarks that are closely aligned with real-world coding practices when evaluating the capabilities of code generation models.
Technical Explanation
The DevEval benchmark is designed to provide a more comprehensive assessment of code generation models by incorporating a diverse set of programming tasks and challenges that are closely aligned with real-world code repositories. The authors curate a dataset of over 1,000 code snippets from popular open-source projects, covering a wide range of programming languages, domains, and complexity levels.
Each code snippet in the DevEval dataset is manually annotated by expert developers, who provide detailed information about the intended functionality, potential issues or improvements, and the reasoning behind the expected solutions. This annotation process allows the benchmark to capture the nuances and tradeoffs that are often encountered in real-world software development.
To evaluate the performance of code generation models on DevEval, the authors compare the models' outputs to the annotated solutions, using a range of metrics that assess factors such as correctness, code quality, and the alignment with the developer's intent. They find that large language models, such as GPT-3 and Codex, can struggle to match the performance of human developers on the more realistic challenges presented in DevEval, even when they excel on other, more artificial benchmarks like HumanEval and CodeEditorBench.
The authors also explore the potential reasons for this performance gap, such as the models' inability to fully capture the contextual and domain-specific knowledge required to solve certain programming tasks, or their tendency to generate code that prioritizes syntactic correctness over semantic coherence with the given problem.
Critical Analysis
The DevEval benchmark represents a significant advance in the evaluation of code generation models, as it provides a more realistic and comprehensive assessment of their capabilities. By incorporating a diverse set of programming tasks and detailed annotations, the benchmark helps to uncover important limitations and mismatch between model performance on artificial tasks and real-world coding challenges.
However, the authors acknowledge that DevEval is not without its own limitations. For example, the dataset may not fully capture the full breadth and complexity of real-world software development, and the manual annotation process can be time-consuming and potentially subject to human bias.
Additionally, while the authors compare the performance of large language models on DevEval, they do not provide a detailed analysis of the specific strengths and weaknesses of these models in handling different types of programming tasks or code structures. Further research could explore these nuances and potentially uncover opportunities for improving the performance of code generation models on more realistic benchmarks like InfiCoder-Eval and NaturalCodeBench.
It would also be valuable to investigate the potential synergies between human developers and code generation models, as the latter may be able to augment and enhance the former's capabilities in certain contexts, particularly when dealing with repetitive or mundane coding tasks. Exploring this human-AI collaboration could lead to more effective and efficient software development workflows.
Conclusion
The DevEval benchmark represents an important step forward in the evaluation of code generation models, providing a more realistic assessment of their capabilities and highlighting the potential mismatch between model performance on artificial tasks and real-world coding challenges. By incorporating detailed annotations and a diverse set of programming tasks, DevEval offers researchers and developers deeper insights into the strengths and limitations of these models, ultimately paving the way for the development of more robust and practical code generation systems.
As the field of AI-assisted software development continues to evolve, benchmarks like DevEval will play a crucial role in ensuring that the technology is aligned with the needs and practices of real-world developers, CyberSecEval-2 and helping to unlock the full potential of human-AI collaboration in the software engineering domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
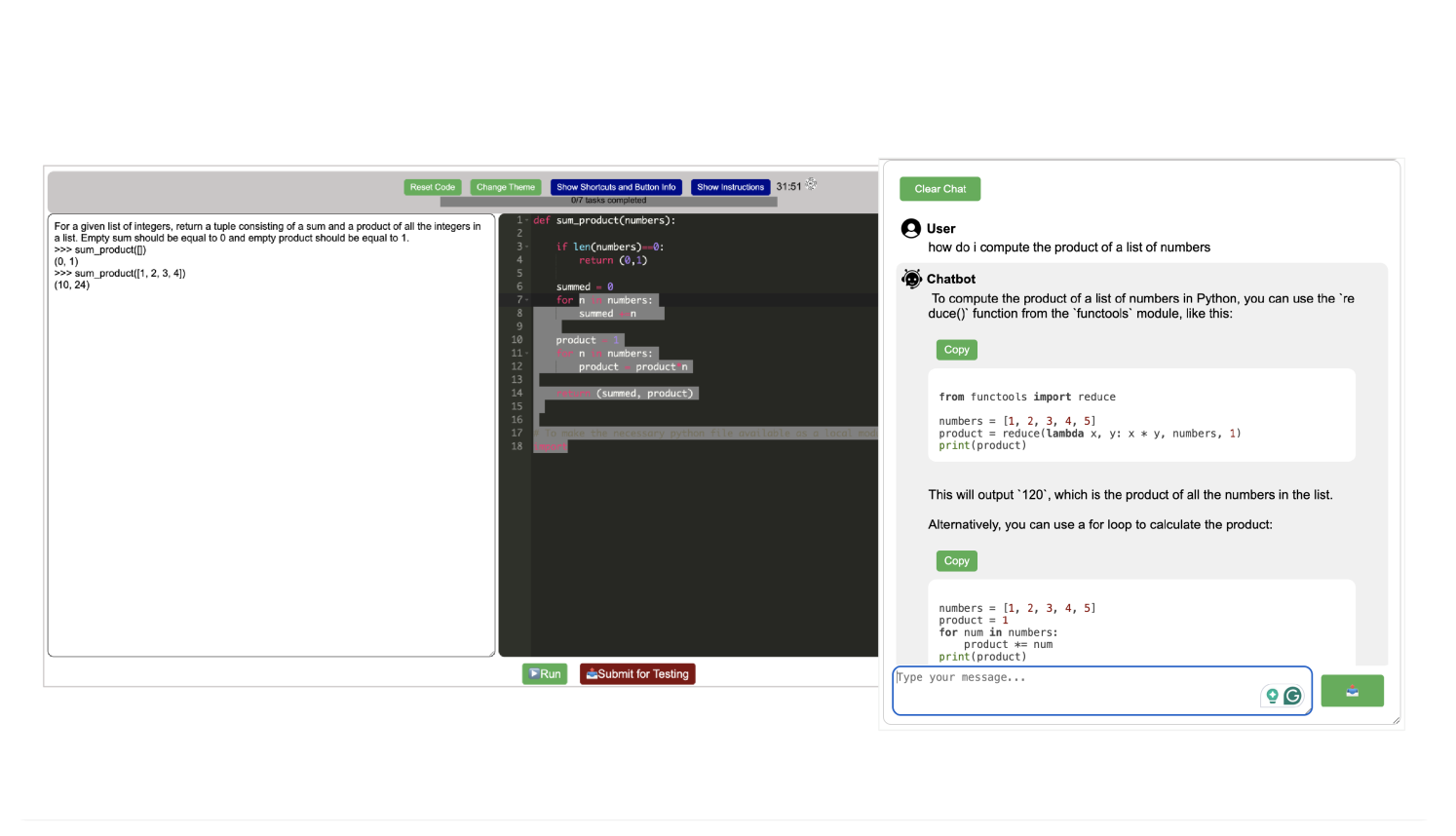
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Hussein Mozannar, Valerie Chen, Mohammed Alsobay, Subhro Das, Sebastian Zhao, Dennis Wei, Manish Nagireddy, Prasanna Sattigeri, Ameet Talwalkar, David Sontag
0
0
Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
4/4/2024
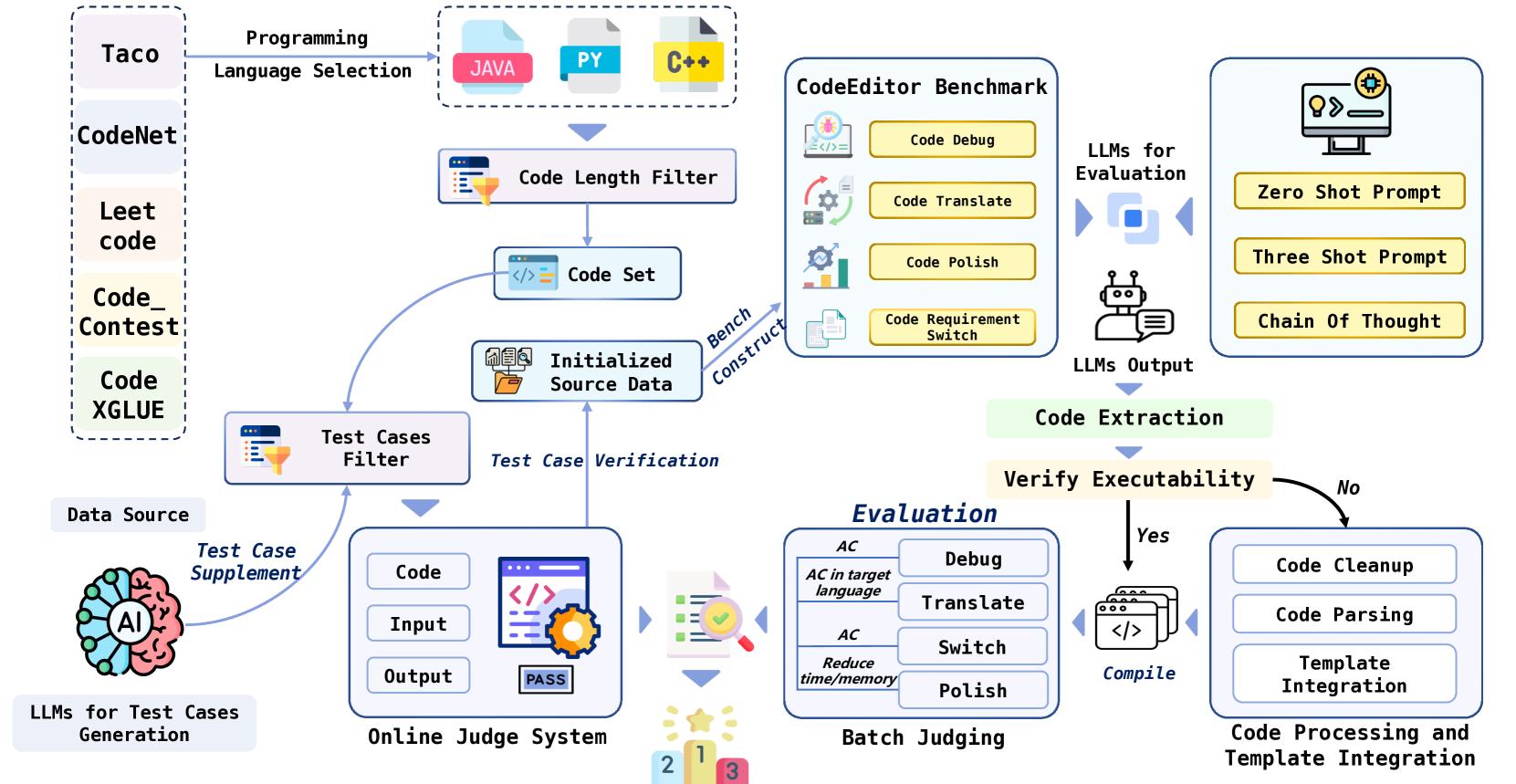
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
0
0
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
4/9/2024
🎲
Benchmarks and Metrics for Evaluations of Code Generation: A Critical Review
Debalina Ghosh Paul, Hong Zhu, Ian Bayley
0
0
With the rapid development of Large Language Models (LLMs), a large number of machine learning models have been developed to assist programming tasks including the generation of program code from natural language input. However, how to evaluate such LLMs for this task is still an open problem despite of the great amount of research efforts that have been made and reported to evaluate and compare them. This paper provides a critical review of the existing work on the testing and evaluation of these tools with a focus on two key aspects: the benchmarks and the metrics used in the evaluations. Based on the review, further research directions are discussed.
6/19/2024

REPOEXEC: Evaluate Code Generation with a Repository-Level Executable Benchmark
Nam Le Hai, Dung Manh Nguyen, Nghi D. Q. Bui
0
0
The ability of CodeLLMs to generate executable and functionally correct code at the repository-level scale remains largely unexplored. We introduce RepoExec, a novel benchmark for evaluating code generation at the repository-level scale. RepoExec focuses on three main aspects: executability, functional correctness through automated test case generation with high coverage rate, and carefully crafted cross-file contexts to accurately generate code. Our work explores a controlled scenario where developers specify necessary code dependencies, challenging the model to integrate these accurately. Experiments show that while pretrained LLMs outperform instruction-tuned models in correctness, the latter excel in utilizing provided dependencies and demonstrating debugging capabilities. We also introduce a new instruction-tuned dataset that focuses on code dependencies and demonstrate that CodeLLMs fine-tuned on our dataset have a better capability to leverage these dependencies effectively. RepoExec aims to provide a comprehensive evaluation of code functionality and alignment with developer intent, paving the way for more reliable and applicable CodeLLMs in real-world scenarios. The dataset and source code can be found at~url{https://github.com/FSoft-AI4Code/RepoExec}.
6/21/2024