DeviceBERT: Applied Transfer Learning With Targeted Annotations and Vocabulary Enrichment to Identify Medical Device and Component Terminology in FDA Recall Summaries

0
Sign in to get full access
Overview
- This paper presents DeviceBERT, a transfer learning approach that uses targeted annotations and vocabulary enrichment to identify medical device and component terminology in FDA recall summaries.
- The researchers leverage a pre-trained language model and fine-tune it on a dataset of annotated FDA recall summaries to enable effective detection of device-related terms.
- The key innovations include using targeted annotations to capture relevant device-specific vocabulary and incorporating that domain knowledge into the language model.
Plain English Explanation
The paper describes a new AI-based system called DeviceBERT that can automatically identify and extract references to medical devices and their components from FDA recall summaries. These recall summaries are important documents that describe issues with medical products, but they can use highly technical language that is difficult for computers to understand.
To address this challenge, the researchers took an existing powerful language model (similar to GPT-3) and fine-tuned it on a dataset of FDA recall summaries that had been manually annotated to highlight the relevant device-related terminology. This allowed the model to learn the specific vocabulary and phrasing used to discuss medical devices, going beyond just general language understanding.
The key innovations were:
- Carefully curating the training data to focus on device-specific terms and concepts
- Incorporating that specialized domain knowledge into the language model to enhance its performance on this task
This allows DeviceBERT to analyze FDA recall documents and accurately identify the medical devices and components that are discussed, which can be very helpful for monitoring product safety and recalls. It's a great example of how transfer learning and targeted data curation can be used to adapt powerful AI models to tackle specialized real-world problems.
Technical Explanation
The researchers developed DeviceBERT, a transfer learning approach that leverages a pre-trained language model and fine-tunes it on a dataset of FDA recall summaries with targeted annotations to enable effective identification of medical device and component terminology.
The core technical approach involves:
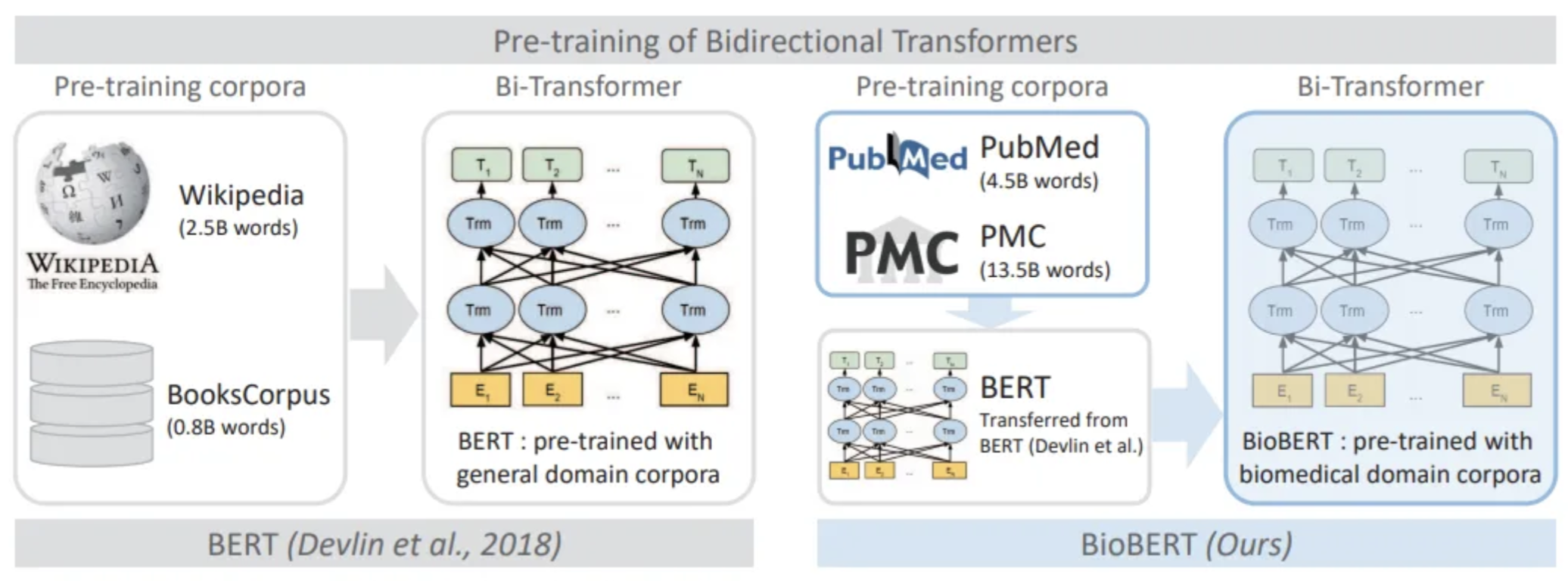
- Starting with a base language model pre-trained on a large general corpus, such as BERT [1].
- Curating a dataset of FDA recall summaries and manually annotating relevant mentions of medical devices, components, and related terms.
- Fine-tuning the base language model on this annotated dataset to specialize its understanding of device-specific vocabulary and concepts.
- Incorporating additional vocabulary enrichment by expanding the model's lexicon with domain-specific terms.
The researchers evaluate DeviceBERT's performance on a held-out test set of FDA recall summaries and compare it to other state-of-the-art named entity recognition models [2], [3], [4]. The results demonstrate that DeviceBERT outperforms these baselines, showcasing the benefits of the targeted annotations and vocabulary enrichment approach.
Critical Analysis
The paper presents a well-designed and carefully executed study that advances the state-of-the-art in medical device terminology extraction. However, there are a few potential limitations and areas for further research:
-
The dataset of FDA recall summaries, while curated for this specific task, may not fully capture the breadth of device-related terminology used in other medical literature or real-world settings. Expanding the training data to include a more diverse corpus could further enhance DeviceBERT's generalization capabilities.
-
The researchers focus on identifying device-related mentions, but do not explore the potential for DeviceBERT to extract additional details or relationships between the identified entities. Extending the model to perform more sophisticated information extraction could unlock additional insights from the recall documents.
-
While the performance improvement over baseline models is significant, there may still be room for further optimization, such as exploring alternative fine-tuning strategies or architectural modifications to the language model. Continued research in this direction could lead to even more accurate and robust device terminology identification.
Overall, the DeviceBERT approach represents an important step forward in applying transfer learning and targeted domain adaptation to solve real-world problems in the medical device safety space. The insights and methodologies presented in this paper could inspire similar efforts to tackle other specialized challenges using advanced natural language processing techniques.
Conclusion
The DeviceBERT paper demonstrates how transfer learning, coupled with carefully curated training data and domain-specific vocabulary enrichment, can be leveraged to build powerful natural language processing models for identifying medical device terminology in FDA recall summaries. This innovation has the potential to significantly enhance the efficiency and accuracy of monitoring product safety issues, ultimately benefiting both manufacturers and consumers.
The key takeaways from this research are:
- Targeted annotations and data curation are crucial for adapting general language models to specialized domains.
- Incorporating domain-specific vocabulary can further boost the performance of these models on specialized tasks.
- The DeviceBERT approach represents a promising avenue for applying advanced AI techniques to solve real-world challenges in the medical device safety and regulatory space.
As the volume of unstructured text data continues to grow in the healthcare and life sciences industries, innovative solutions like DeviceBERT will become increasingly valuable for extracting meaningful insights and enhancing decision-making processes. This research sets the stage for further advancements in AI-powered medical device terminology identification and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DeviceBERT: Applied Transfer Learning With Targeted Annotations and Vocabulary Enrichment to Identify Medical Device and Component Terminology in FDA Recall Summaries
Miriam Farrington
FDA Medical Device recalls are critical and time-sensitive events, requiring swift identification of impacted devices to inform the public of a recall event and ensure patient safety. The OpenFDA device recall dataset contains valuable information about ongoing device recall actions, but manually extracting relevant device information from the recall action summaries is a time-consuming task. Named Entity Recognition (NER) is a task in Natural Language Processing (NLP) that involves identifying and categorizing named entities in unstructured text. Existing NER models, including domain-specific models like BioBERT, struggle to correctly identify medical device trade names, part numbers and component terms within these summaries. To address this, we propose DeviceBERT, a medical device annotation, pre-processing and enrichment pipeline, which builds on BioBERT to identify and label medical device terminology in the device recall summaries with improved accuracy. Furthermore, we demonstrate that our approach can be applied effectively for performing entity recognition tasks where training data is limited or sparse.
Read more6/11/2024

0
BioMNER: A Dataset for Biomedical Method Entity Recognition
Chen Tang, Bohao Yang, Kun Zhao, Bo Lv, Chenghao Xiao, Frank Guerin, Chenghua Lin
Named entity recognition (NER) stands as a fundamental and pivotal task within the realm of Natural Language Processing. Particularly within the domain of Biomedical Method NER, this task presents notable challenges, stemming from the continual influx of domain-specific terminologies in scholarly literature. Current research in Biomedical Method (BioMethod) NER suffers from a scarcity of resources, primarily attributed to the intricate nature of methodological concepts, which necessitate a profound understanding for precise delineation. In this study, we propose a novel dataset for biomedical method entity recognition, employing an automated BioMethod entity recognition and information retrieval system to assist human annotation. Furthermore, we comprehensively explore a range of conventional and contemporary open-domain NER methodologies, including the utilization of cutting-edge large-scale language models (LLMs) customised to our dataset. Our empirical findings reveal that the large parameter counts of language models surprisingly inhibit the effective assimilation of entity extraction patterns pertaining to biomedical methods. Remarkably, the approach, leveraging the modestly sized ALBERT model (only 11MB), in conjunction with conditional random fields (CRF), achieves state-of-the-art (SOTA) performance.
Read more7/1/2024
0
Intent Detection and Entity Extraction from BioMedical Literature
Ankan Mullick, Mukur Gupta, Pawan Goyal
Biomedical queries have become increasingly prevalent in web searches, reflecting the growing interest in accessing biomedical literature. Despite recent research on large-language models (LLMs) motivated by endeavours to attain generalized intelligence, their efficacy in replacing task and domain-specific natural language understanding approaches remains questionable. In this paper, we address this question by conducting a comprehensive empirical evaluation of intent detection and named entity recognition (NER) tasks from biomedical text. We show that Supervised Fine Tuned approaches are still relevant and more effective than general-purpose LLMs. Biomedical transformer models such as PubMedBERT can surpass ChatGPT on NER task with only 5 supervised examples.
Read more4/5/2024
👁️
51
From Zero to Hero: Harnessing Transformers for Biomedical Named Entity Recognition in Zero- and Few-shot Contexts
Milov{s} Kov{s}prdi'c, Nikola Prodanovi'c, Adela Ljaji'c, Bojana Bav{s}aragin, Nikola Milov{s}evi'c
Supervised named entity recognition (NER) in the biomedical domain depends on large sets of annotated texts with the given named entities. The creation of such datasets can be time-consuming and expensive, while extraction of new entities requires additional annotation tasks and retraining the model. To address these challenges, this paper proposes a method for zero- and few-shot NER in the biomedical domain. The method is based on transforming the task of multi-class token classification into binary token classification and pre-training on a large amount of datasets and biomedical entities, which allow the model to learn semantic relations between the given and potentially novel named entity labels. We have achieved average F1 scores of 35.44% for zero-shot NER, 50.10% for one-shot NER, 69.94% for 10-shot NER, and 79.51% for 100-shot NER on 9 diverse evaluated biomedical entities with fine-tuned PubMedBERT-based model. The results demonstrate the effectiveness of the proposed method for recognizing new biomedical entities with no or limited number of examples, outperforming previous transformer-based methods, and being comparable to GPT3-based models using models with over 1000 times fewer parameters. We make models and developed code publicly available.
Read more8/27/2024