Transductive Zero-Shot and Few-Shot CLIP
2405.18437
0
0
⛏️
Abstract
Transductive inference has been widely investigated in few-shot image classification, but completely overlooked in the recent, fast growing literature on adapting vision-langage models like CLIP. This paper addresses the transductive zero-shot and few-shot CLIP classification challenge, in which inference is performed jointly across a mini-batch of unlabeled query samples, rather than treating each instance independently. We initially construct informative vision-text probability features, leading to a classification problem on the unit simplex set. Inspired by Expectation-Maximization (EM), our optimization-based classification objective models the data probability distribution for each class using a Dirichlet law. The minimization problem is then tackled with a novel block Majorization-Minimization algorithm, which simultaneously estimates the distribution parameters and class assignments. Extensive numerical experiments on 11 datasets underscore the benefits and efficacy of our batch inference approach.On zero-shot tasks with test batches of 75 samples, our approach yields near 20% improvement in ImageNet accuracy over CLIP's zero-shot performance. Additionally, we outperform state-of-the-art methods in the few-shot setting. The code is available at: https://github.com/SegoleneMartin/transductive-CLIP.
Create account to get full access
Overview
- This paper addresses the problem of transductive zero-shot and few-shot learning using the CLIP vision-language model.
- Transductive learning involves jointly inferring the class labels of a batch of unlabeled query samples, rather than treating each instance independently.
- The authors propose a novel optimization-based approach inspired by Expectation-Maximization that models the data probability distribution for each class using a Dirichlet law.
Plain English Explanation
The paper focuses on a technique called transductive inference for few-shot image classification using CLIP, a popular vision-language model.
Traditionally, CLIP has been used for zero-shot and few-shot classification by treating each test image independently. In contrast, the authors propose a "batch" approach where the model looks at all the unlabeled test images together when making predictions.
The key idea is to model the probability distribution of each class using a mathematical concept called the Dirichlet distribution. This allows the model to exploit the relationships between the test images, rather than just considering them in isolation.
The authors develop a novel optimization algorithm to efficiently estimate the Dirichlet parameters and class assignments simultaneously. Their experiments show this transductive approach can significantly improve the zero-shot and few-shot performance of CLIP on a wide range of image classification tasks.
Technical Explanation
The paper starts by constructing informative vision-text probability features, which lead to a classification problem on the unit simplex set. Inspired by Expectation-Maximization (EM), the authors propose an optimization-based classification objective that models the data probability distribution for each class using a Dirichlet law.
The minimization problem is then tackled with a novel block Majorization-Minimization algorithm, which simultaneously estimates the Dirichlet distribution parameters and class assignments for the unlabeled query samples. This transductive learning approach allows the model to exploit the relationships between the test examples, rather than treating them independently.
Extensive experiments on 11 different datasets demonstrate the benefits of this batch inference approach. On zero-shot tasks with test batches of 75 samples, the authors' method yields nearly 20% improvement in ImageNet accuracy over CLIP's standard zero-shot performance. The approach also outperforms state-of-the-art few-shot classification methods.
Critical Analysis
The paper presents a novel and promising approach for leveraging transductive learning to boost the performance of CLIP in zero-shot and few-shot image classification. The authors convincingly demonstrate the advantages of their method through extensive experiments.
However, the paper does not address some potential limitations. For example, the computational complexity of the Majorization-Minimization algorithm may limit its scalability to larger batches or higher-dimensional feature spaces. The authors also do not discuss how their method might handle noisy or adversarial inputs, which is an important consideration for real-world deployment.
Additionally, while the paper focuses on CLIP, the transductive learning approach could potentially be applied to other vision-language models as well. It would be interesting to see how the method performs in that broader context.
Overall, this research makes a valuable contribution to the field of few-shot learning and opens up new directions for improving the capabilities of large-scale multimodal models like CLIP.
Conclusion
This paper presents a transductive inference approach for enhancing the zero-shot and few-shot performance of the CLIP vision-language model. By jointly modeling the data probability distributions for each class using a Dirichlet law, the authors develop a novel optimization-based classification method that can effectively exploit the relationships between unlabeled test samples.
The results demonstrate significant improvements over CLIP's standard independent-instance predictions, underscoring the benefits of batch-level inference. This work advances the state of the art in few-shot image classification and highlights the potential of transductive learning techniques for adapting large-scale multimodal models to new tasks and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Boosting Vision-Language Models with Transduction
Maxime Zanella, Beno^it G'erin, Ismail Ben Ayed
0
0
Transduction is a powerful paradigm that leverages the structure of unlabeled data to boost predictive accuracy. We present TransCLIP, a novel and computationally efficient transductive approach designed for Vision-Language Models (VLMs). TransCLIP is applicable as a plug-and-play module on top of popular inductive zero- and few-shot models, consistently improving their performances. Our new objective function can be viewed as a regularized maximum-likelihood estimation, constrained by a KL divergence penalty that integrates the text-encoder knowledge and guides the transductive learning process. We further derive an iterative Block Majorize-Minimize (BMM) procedure for optimizing our objective, with guaranteed convergence and decoupled sample-assignment updates, yielding computationally efficient transduction for large-scale datasets. We report comprehensive evaluations, comparisons, and ablation studies that demonstrate: (i) Transduction can greatly enhance the generalization capabilities of inductive pretrained zero- and few-shot VLMs; (ii) TransCLIP substantially outperforms standard transductive few-shot learning methods relying solely on vision features, notably due to the KL-based language constraint.
6/5/2024
🤯
Multimodal CLIP Inference for Meta-Few-Shot Image Classification
Constance Ferragu, Philomene Chagniot, Vincent Coyette
0
0
In recent literature, few-shot classification has predominantly been defined by the N-way k-shot meta-learning problem. Models designed for this purpose are usually trained to excel on standard benchmarks following a restricted setup, excluding the use of external data. Given the recent advancements in large language and vision models, a question naturally arises: can these models directly perform well on meta-few-shot learning benchmarks? Multimodal foundation models like CLIP, which learn a joint (image, text) embedding, are of particular interest. Indeed, multimodal training has proven to enhance model robustness, especially regarding ambiguities, a limitation frequently observed in the few-shot setup. This study demonstrates that combining modalities from CLIP's text and image encoders outperforms state-of-the-art meta-few-shot learners on widely adopted benchmarks, all without additional training. Our results confirm the potential and robustness of multimodal foundation models like CLIP and serve as a baseline for existing and future approaches leveraging such models.
5/21/2024
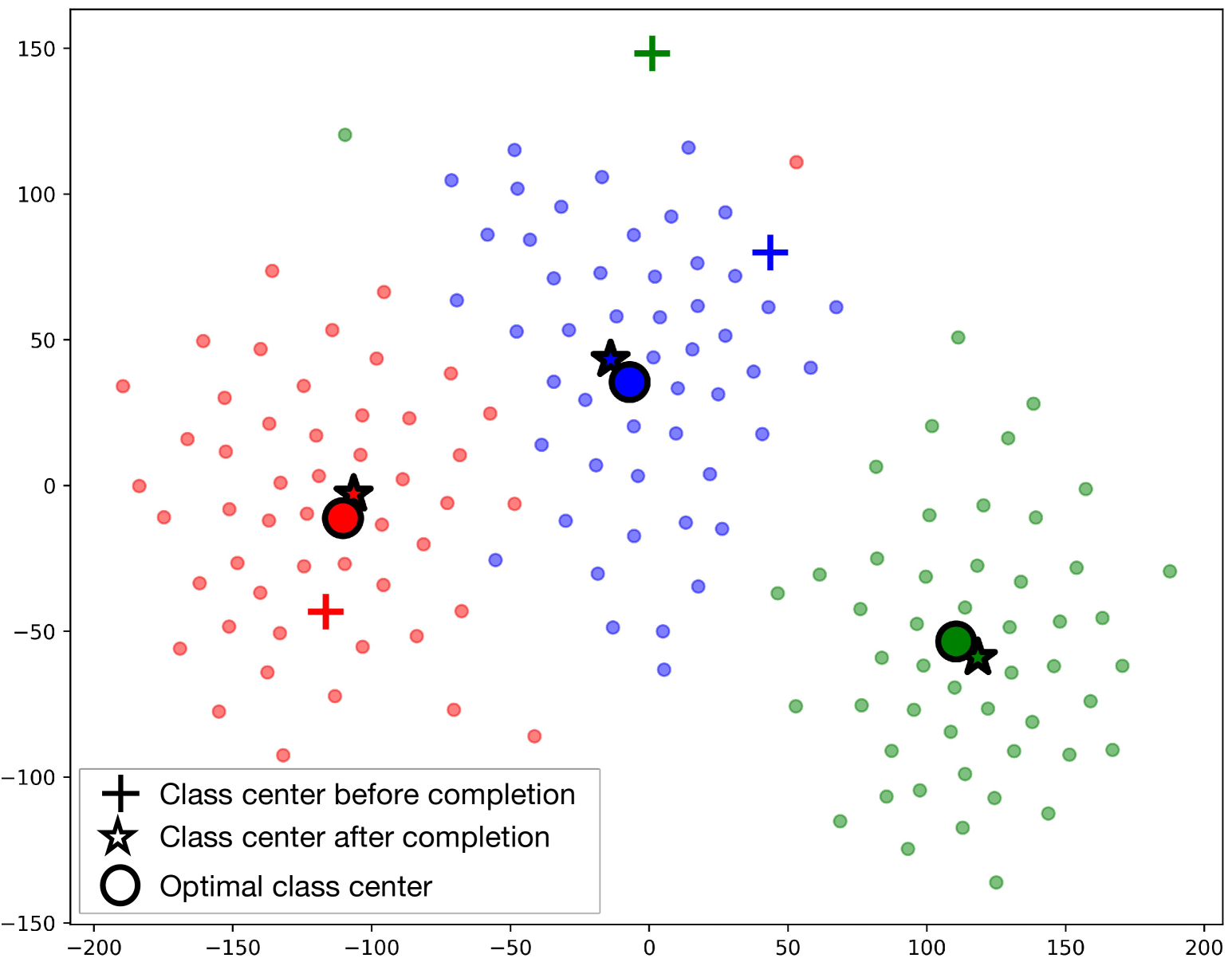
The Devil is in the Few Shots: Iterative Visual Knowledge Completion for Few-shot Learning
Yaohui Li, Qifeng Zhou, Haoxing Chen, Jianbing Zhang, Xinyu Dai, Hao Zhou
0
0
Contrastive Language-Image Pre-training (CLIP) has shown powerful zero-shot learning performance. Few-shot learning aims to further enhance the transfer capability of CLIP by giving few images in each class, aka 'few shots'. Most existing methods either implicitly learn from the few shots by incorporating learnable prompts or adapters, or explicitly embed them in a cache model for inference. However, the narrow distribution of few shots often contains incomplete class information, leading to biased visual knowledge with high risk of misclassification. To tackle this problem, recent methods propose to supplement visual knowledge by generative models or extra databases, which can be costly and time-consuming. In this paper, we propose an Iterative Visual Knowledge CompLetion (KCL) method to complement visual knowledge by properly taking advantages of unlabeled samples without access to any auxiliary or synthetic data. Specifically, KCL first measures the similarities between unlabeled samples and each category. Then, the samples with top confidence to each category is selected and collected by a designed confidence criterion. Finally, the collected samples are treated as labeled ones and added to few shots to jointly re-estimate the remaining unlabeled ones. The above procedures will be repeated for a certain number of iterations with more and more samples being collected until convergence, ensuring a progressive and robust knowledge completion process. Extensive experiments on 11 benchmark datasets demonstrate the effectiveness and efficiency of KCL as a plug-and-play module under both few-shot and zero-shot learning settings. Code is available at https://github.com/Mark-Sky/KCL.
4/22/2024

Mining Open Semantics from CLIP: A Relation Transition Perspective for Few-Shot Learning
Cilin Yan, Haochen Wang, Xiaolong Jiang, Yao Hu, Xu Tang, Guoliang Kang, Efstratios Gavves
0
0
Contrastive Vision-Language Pre-training(CLIP) demonstrates impressive zero-shot capability. The key to improve the adaptation of CLIP to downstream task with few exemplars lies in how to effectively model and transfer the useful knowledge embedded in CLIP. Previous work mines the knowledge typically based on the limited visual samples and close-set semantics (i.e., within target category set of downstream task). However, the aligned CLIP image/text encoders contain abundant relationships between visual features and almost infinite open semantics, which may benefit the few-shot learning but remains unexplored. In this paper, we propose to mine open semantics as anchors to perform a relation transition from image-anchor relationship to image-target relationship to make predictions. Specifically, we adopt a transformer module which takes the visual feature as Query, the text features of the anchors as Key and the similarity matrix between the text features of anchor and target classes as Value. In this way, the output of such a transformer module represents the relationship between the image and target categories, i.e., the classification predictions. To avoid manually selecting the open semantics, we make the [CLASS] token of input text embedding learnable. We conduct extensive experiments on eleven representative classification datasets. The results show that our method performs favorably against previous state-of-the-arts considering few-shot classification settings.
6/18/2024