Rethinking Prior Information Generation with CLIP for Few-Shot Segmentation
2405.08458
0
0
🛸
Abstract
Few-shot segmentation remains challenging due to the limitations of its labeling information for unseen classes. Most previous approaches rely on extracting high-level feature maps from the frozen visual encoder to compute the pixel-wise similarity as a key prior guidance for the decoder. However, such a prior representation suffers from coarse granularity and poor generalization to new classes since these high-level feature maps have obvious category bias. In this work, we propose to replace the visual prior representation with the visual-text alignment capacity to capture more reliable guidance and enhance the model generalization. Specifically, we design two kinds of training-free prior information generation strategy that attempts to utilize the semantic alignment capability of the Contrastive Language-Image Pre-training model (CLIP) to locate the target class. Besides, to acquire more accurate prior guidance, we build a high-order relationship of attention maps and utilize it to refine the initial prior information. Experiments on both the PASCAL-5{i} and COCO-20{i} datasets show that our method obtains a clearly substantial improvement and reaches the new state-of-the-art performance.
Create account to get full access
Overview
- Few-shot segmentation remains a challenging task due to the limited labeling information for unseen classes.
- Previous approaches rely on extracting high-level feature maps from a frozen visual encoder to compute pixel-wise similarity as a key prior guidance for the decoder.
- However, this prior representation suffers from coarse granularity and poor generalization to new classes, as the feature maps have an inherent category bias.
Plain English Explanation
In few-shot segmentation, the goal is to teach an AI system to accurately segment objects in an image, but with only a small amount of labeled training data. This is a challenging task because the system has to generalize from limited information to recognize new types of objects.
Most previous approaches have tried to solve this by extracting high-level visual features from the image and using those to guide the segmentation process. However, these high-level features tend to be biased towards the specific object categories seen during training. This means the system struggles to generalize and accurately segment new types of objects that it hasn't been explicitly trained on.
To address this, the researchers in this paper propose replacing the visual feature-based prior with one that is based on the semantic alignment between the image and text. The idea is that by tapping into the language understanding capabilities of CLIP, the system can gain a more reliable and generalizable sense of what the target object is, without being as constrained by the training data.
Technical Explanation
The key innovation in this work is the use of visual-text alignment from a Contrastive Language-Image Pre-training (CLIP) model to provide the prior guidance for the few-shot segmentation task, rather than relying on high-level visual features.
Specifically, the authors propose two training-free strategies to generate this visual-text alignment-based prior information:
- Directly using the CLIP model's text-image similarity scores to identify the target object.
- Refining the initial CLIP-based prior by exploiting the higher-order relationships between different attention maps.
This visual-text alignment prior is then integrated into the segmentation model's decoder to provide more reliable and generalizable guidance, compared to the standard visual feature-based approach.
The authors evaluate their method on the PASCAL-5^i and COCO-20^i few-shot segmentation benchmarks, and show that it achieves state-of-the-art performance, significantly outperforming previous techniques.
Critical Analysis
While the proposed approach demonstrates impressive results on the few-shot segmentation task, there are a few potential limitations and areas for further research:
- The reliance on a pre-trained CLIP model means the performance is still constrained by the model's training data and biases. Exploring ways to further fine-tune or adapt the CLIP model for this specific task could lead to even better generalization.
- The higher-order attention map refinement strategy adds additional computational complexity. Investigating more efficient ways to incorporate the semantic alignment information could make the approach more scalable.
- The paper focuses on evaluating the method on standard few-shot segmentation benchmarks. Assessing its performance on more diverse or real-world datasets with greater class imbalance and occlusion would help validate its broader applicability.
Overall, this work represents an important step forward in leveraging language-vision models like CLIP to tackle the challenge of few-shot segmentation. The core idea of using semantic alignment as a more generalizable prior is promising and could inspire further research in this direction.
Conclusion
This paper presents a novel approach to few-shot segmentation that replaces the traditional visual feature-based prior with one derived from the semantic alignment between the image and text. By tapping into the language understanding capabilities of a pre-trained CLIP model, the system can gain a more reliable and generalizable sense of the target object, leading to improved performance on few-shot segmentation tasks.
While the method shows promising results, there are opportunities for further refinement and exploration of its broader applicability. Overall, this work highlights the potential of leveraging language-vision models to tackle challenging computer vision problems, and could have important implications for the field of few-shot learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Unsupervised Image Prior via Prompt Learning and CLIP Semantic Guidance for Low-Light Image Enhancement
Igor Morawski, Kai He, Shusil Dangi, Winston H. Hsu
0
0
Currently, low-light conditions present a significant challenge for machine cognition. In this paper, rather than optimizing models by assuming that human and machine cognition are correlated, we use zero-reference low-light enhancement to improve the performance of downstream task models. We propose to improve the zero-reference low-light enhancement method by leveraging the rich visual-linguistic CLIP prior without any need for paired or unpaired normal-light data, which is laborious and difficult to collect. We propose a simple but effective strategy to learn prompts that help guide the enhancement method and experimentally show that the prompts learned without any need for normal-light data improve image contrast, reduce over-enhancement, and reduce noise over-amplification. Next, we propose to reuse the CLIP model for semantic guidance via zero-shot open vocabulary classification to optimize low-light enhancement for task-based performance rather than human visual perception. We conduct extensive experimental results showing that the proposed method leads to consistent improvements across various datasets regarding task-based performance and compare our method against state-of-the-art methods, showing favorable results across various low-light datasets.
5/21/2024

CLIP with Quality Captions: A Strong Pretraining for Vision Tasks
Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Oncel Tuzel
0
0
CLIP models perform remarkably well on zero-shot classification and retrieval tasks. But recent studies have shown that learnt representations in CLIP are not well suited for dense prediction tasks like object detection, semantic segmentation or depth estimation. More recently, multi-stage training methods for CLIP models was introduced to mitigate the weak performance of CLIP on downstream tasks. In this work, we find that simply improving the quality of captions in image-text datasets improves the quality of CLIP's visual representations, resulting in significant improvement on downstream dense prediction vision tasks. In fact, we find that CLIP pretraining with good quality captions can surpass recent supervised, self-supervised and weakly supervised pretraining methods. We show that when CLIP model with ViT-B/16 as image encoder is trained on well aligned image-text pairs it obtains 12.1% higher mIoU and 11.5% lower RMSE on semantic segmentation and depth estimation tasks over recent state-of-the-art Masked Image Modeling (MIM) pretraining methods like Masked Autoencoder (MAE). We find that mobile architectures also benefit significantly from CLIP pretraining. A recent mobile vision architecture, MCi2, with CLIP pretraining obtains similar performance as Swin-L, pretrained on ImageNet-22k for semantic segmentation task while being 6.1$times$ smaller. Moreover, we show that improving caption quality results in $10times$ data efficiency when finetuning for dense prediction tasks.
5/16/2024

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
6/21/2024
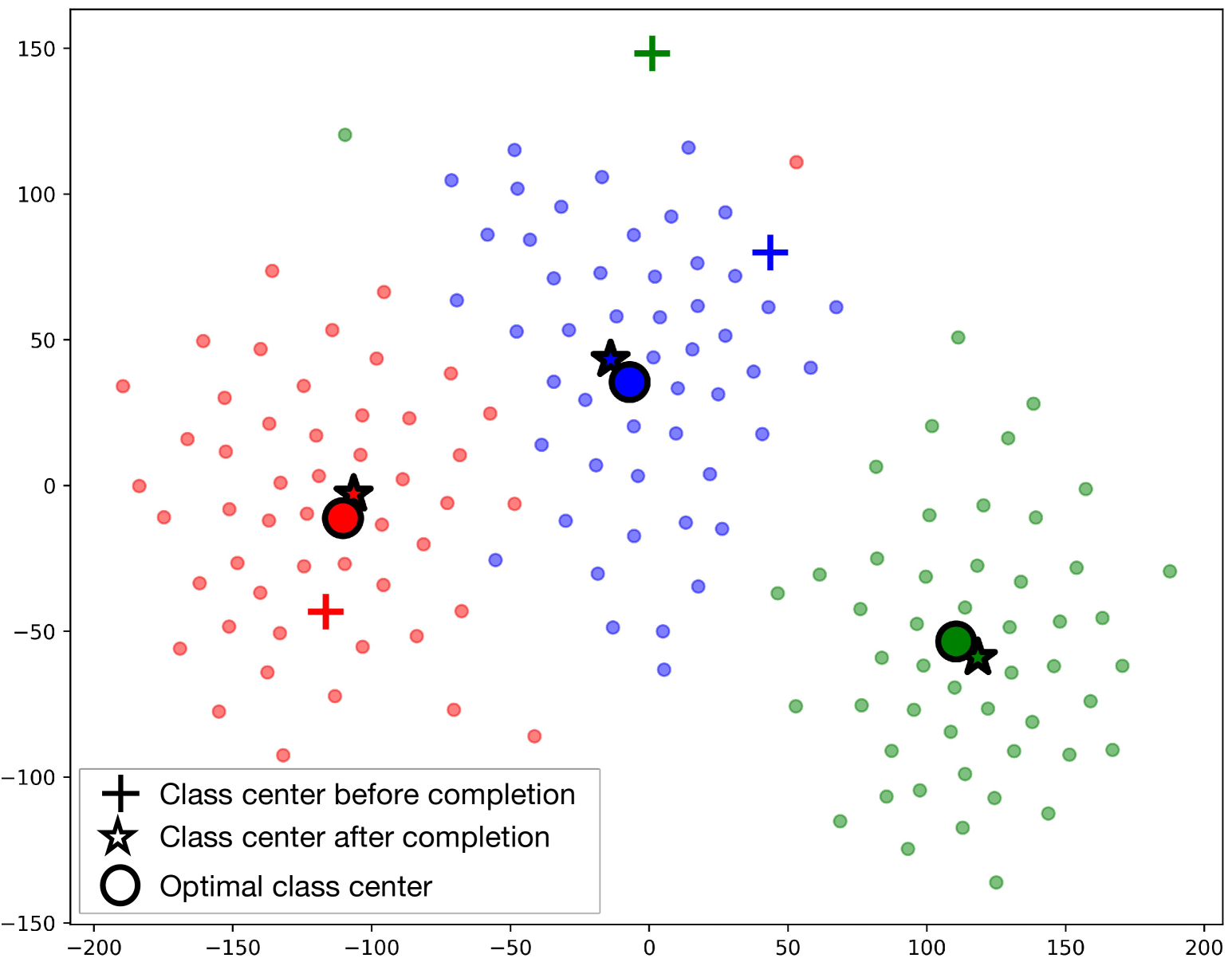
The Devil is in the Few Shots: Iterative Visual Knowledge Completion for Few-shot Learning
Yaohui Li, Qifeng Zhou, Haoxing Chen, Jianbing Zhang, Xinyu Dai, Hao Zhou
0
0
Contrastive Language-Image Pre-training (CLIP) has shown powerful zero-shot learning performance. Few-shot learning aims to further enhance the transfer capability of CLIP by giving few images in each class, aka 'few shots'. Most existing methods either implicitly learn from the few shots by incorporating learnable prompts or adapters, or explicitly embed them in a cache model for inference. However, the narrow distribution of few shots often contains incomplete class information, leading to biased visual knowledge with high risk of misclassification. To tackle this problem, recent methods propose to supplement visual knowledge by generative models or extra databases, which can be costly and time-consuming. In this paper, we propose an Iterative Visual Knowledge CompLetion (KCL) method to complement visual knowledge by properly taking advantages of unlabeled samples without access to any auxiliary or synthetic data. Specifically, KCL first measures the similarities between unlabeled samples and each category. Then, the samples with top confidence to each category is selected and collected by a designed confidence criterion. Finally, the collected samples are treated as labeled ones and added to few shots to jointly re-estimate the remaining unlabeled ones. The above procedures will be repeated for a certain number of iterations with more and more samples being collected until convergence, ensuring a progressive and robust knowledge completion process. Extensive experiments on 11 benchmark datasets demonstrate the effectiveness and efficiency of KCL as a plug-and-play module under both few-shot and zero-shot learning settings. Code is available at https://github.com/Mark-Sky/KCL.
4/22/2024