Multimodal CLIP Inference for Meta-Few-Shot Image Classification
2405.10954
0
0
🤯
Abstract
In recent literature, few-shot classification has predominantly been defined by the N-way k-shot meta-learning problem. Models designed for this purpose are usually trained to excel on standard benchmarks following a restricted setup, excluding the use of external data. Given the recent advancements in large language and vision models, a question naturally arises: can these models directly perform well on meta-few-shot learning benchmarks? Multimodal foundation models like CLIP, which learn a joint (image, text) embedding, are of particular interest. Indeed, multimodal training has proven to enhance model robustness, especially regarding ambiguities, a limitation frequently observed in the few-shot setup. This study demonstrates that combining modalities from CLIP's text and image encoders outperforms state-of-the-art meta-few-shot learners on widely adopted benchmarks, all without additional training. Our results confirm the potential and robustness of multimodal foundation models like CLIP and serve as a baseline for existing and future approaches leveraging such models.
Create account to get full access
Overview
- Few-shot classification has traditionally been defined by the N-way k-shot meta-learning problem, where models are trained on standard benchmarks without using external data.
- With the recent advancements in large language and vision models, this study explores whether these models can directly perform well on meta-few-shot learning benchmarks, particularly multimodal foundation models like CLIP.
- Multimodal training has been shown to enhance model robustness, which is important in the few-shot learning setup where ambiguities are frequently observed.
Plain English Explanation
Few-shot classification is a machine learning task where a model needs to learn to classify objects into different categories using only a small number of examples for each category. Traditionally, models designed for this purpose are trained on standard benchmark datasets following a specific setup, and they are not allowed to use any additional external data.
However, with the recent advancements in large language and vision models, such as CLIP, the researchers in this study wanted to explore whether these powerful models can directly perform well on few-shot learning tasks without any additional training. CLIP is a multimodal model, meaning it can process both images and text, and this has been shown to make models more robust, especially when dealing with ambiguous information, which is a common challenge in few-shot learning.
The study found that by combining the features from CLIP's text and image encoders, the model outperformed state-of-the-art few-shot learning models on widely used benchmarks, all without any additional training. This suggests that multimodal foundation models like CLIP have the potential to excel at few-shot learning tasks and can serve as a strong baseline for future approaches in this area.
Technical Explanation
This study investigates the performance of multimodal foundation models, such as CLIP, on meta-few-shot learning benchmarks without any additional training. Traditionally, few-shot classification has been defined by the N-way k-shot meta-learning problem, where models are trained to excel on standard benchmarks following a restricted setup that excludes the use of external data.
The researchers hypothesized that with the recent advancements in large language and vision models, these models may be able to directly perform well on meta-few-shot learning tasks. Multimodal foundation models like CLIP, which learn a joint (image, text) embedding, are of particular interest because multimodal training has been shown to enhance model robustness, especially regarding ambiguities, a limitation frequently observed in the few-shot setup.
To test this hypothesis, the study combined the features from CLIP's text and image encoders and evaluated the performance on widely adopted meta-few-shot learning benchmarks. The results demonstrate that this approach outperforms state-of-the-art meta-few-shot learners on these benchmarks, without any additional training.
These findings confirm the potential and robustness of multimodal foundation models like CLIP and serve as a baseline for existing and future approaches leveraging such models for few-shot learning tasks. The study highlights the importance of exploring the capabilities of large language and vision models beyond their original training setups, as they may possess inherent few-shot learning abilities that can be exploited without the need for specialized meta-learning approaches.
Critical Analysis
The study provides a compelling demonstration of the capabilities of multimodal foundation models, such as CLIP, in the context of few-shot learning. By leveraging the joint (image, text) embedding learned by these models, the researchers were able to outperform state-of-the-art meta-few-shot learners on standard benchmarks without any additional training.
One potential limitation of this approach is that it may not capture the full extent of the model's few-shot learning abilities, as the study focused on combining the features from the text and image encoders rather than fine-tuning or adapting the model to the specific few-shot learning task. It would be interesting to see if further fine-tuning or task-specific training could lead to even better performance.
Additionally, the study did not explore the Devil is in the Few Shots: Iterative Visual Knowledge Acquisition for Multi-Modal Few-Shot Learning or the Eyes Wide Shut: Exploring Visual Shortcomings of Vision-Language Models papers, which may provide valuable insights into the limitations and potential pitfalls of using multimodal models for few-shot learning tasks.
Overall, this study serves as an important baseline for understanding the few-shot learning capabilities of large language and vision models, and it highlights the potential of leveraging multimodal training to enhance model robustness in the few-shot learning domain. Future research could explore more advanced fine-tuning or adaptation techniques to further unlock the potential of these powerful models for few-shot learning applications.
Conclusion
This study demonstrates that combining the modalities from CLIP's text and image encoders can outperform state-of-the-art meta-few-shot learners on widely adopted benchmarks, without any additional training. These findings confirm the potential and robustness of multimodal foundation models like CLIP and serve as a baseline for existing and future approaches leveraging such models for few-shot learning tasks.
The ability of these large language and vision models to excel at few-shot learning without specialized training has significant implications for the field of machine learning. It suggests that these models may possess inherent few-shot learning capabilities that can be exploited without the need for complex meta-learning approaches, potentially leading to more efficient and accessible few-shot learning solutions. As the field continues to advance, further research into the few-shot learning abilities of multimodal foundation models could pave the way for more robust and versatile machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multimodal Multilabel Classification by CLIP
Yanming Guo
0
0
Multimodal multilabel classification (MMC) is a challenging task that aims to design a learning algorithm to handle two data sources, the image and text, and learn a comprehensive semantic feature presentation across the modalities. In this task, we review the extensive number of state-of-the-art approaches in MMC and leverage a novel technique that utilises the Contrastive Language-Image Pre-training (CLIP) as the feature extractor and fine-tune the model by exploring different classification heads, fusion methods and loss functions. Finally, our best result achieved more than 90% F_1 score in the public Kaggle competition leaderboard. This paper provides detailed descriptions of novel training methods and quantitative analysis through the experimental results.
6/26/2024
⛏️
Transductive Zero-Shot and Few-Shot CLIP
S'egol`ene Martin (OPIS, CVN), Yunshi Huang (ETS), Fereshteh Shakeri (ETS), Jean-Christophe Pesquet (OPIS, CVN), Ismail Ben Ayed (ETS)
0
0
Transductive inference has been widely investigated in few-shot image classification, but completely overlooked in the recent, fast growing literature on adapting vision-langage models like CLIP. This paper addresses the transductive zero-shot and few-shot CLIP classification challenge, in which inference is performed jointly across a mini-batch of unlabeled query samples, rather than treating each instance independently. We initially construct informative vision-text probability features, leading to a classification problem on the unit simplex set. Inspired by Expectation-Maximization (EM), our optimization-based classification objective models the data probability distribution for each class using a Dirichlet law. The minimization problem is then tackled with a novel block Majorization-Minimization algorithm, which simultaneously estimates the distribution parameters and class assignments. Extensive numerical experiments on 11 datasets underscore the benefits and efficacy of our batch inference approach.On zero-shot tasks with test batches of 75 samples, our approach yields near 20% improvement in ImageNet accuracy over CLIP's zero-shot performance. Additionally, we outperform state-of-the-art methods in the few-shot setting. The code is available at: https://github.com/SegoleneMartin/transductive-CLIP.
5/30/2024
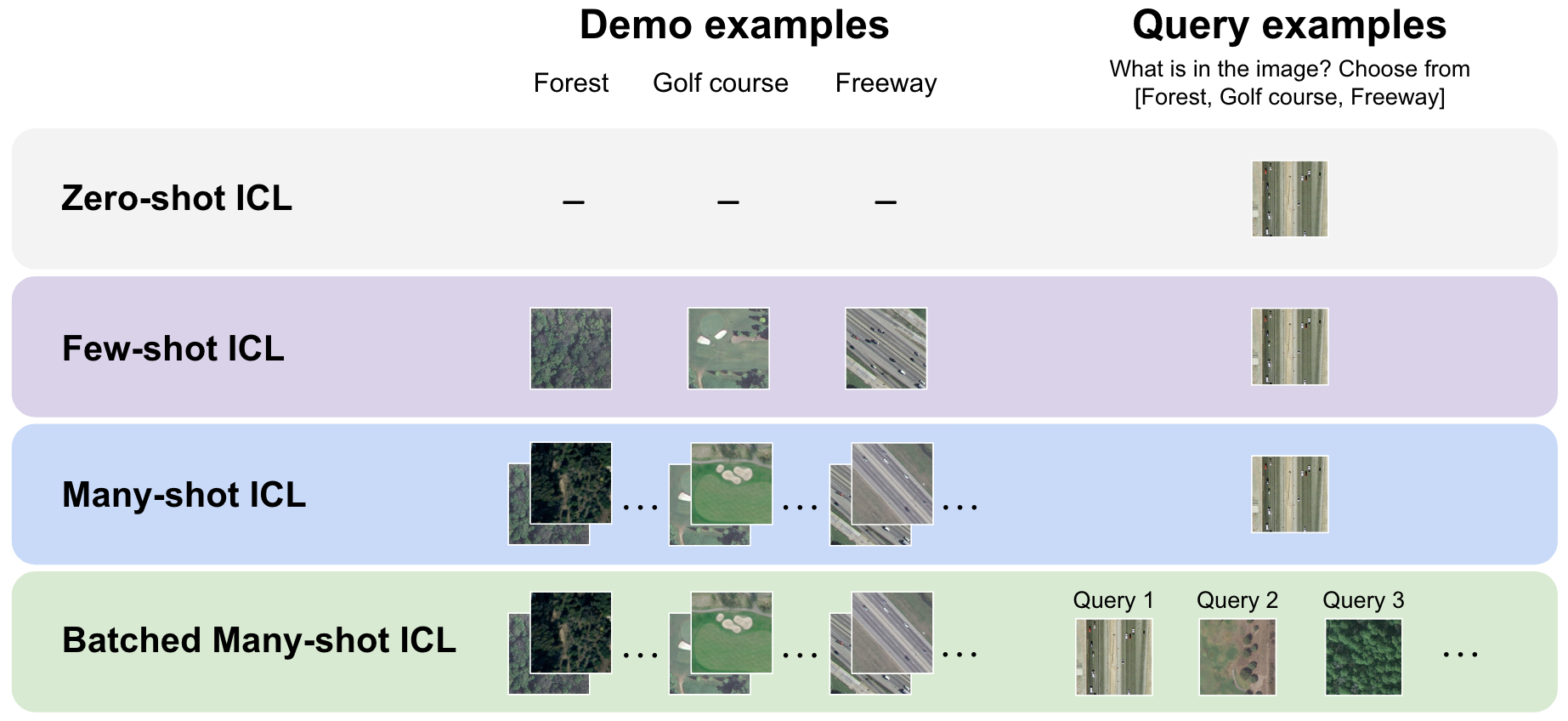
Many-Shot In-Context Learning in Multimodal Foundation Models
Yixing Jiang, Jeremy Irvin, Ji Hun Wang, Muhammad Ahmed Chaudhry, Jonathan H. Chen, Andrew Y. Ng
0
0
Large language models are well-known to be effective at few-shot in-context learning (ICL). Recent advancements in multimodal foundation models have enabled unprecedentedly long context windows, presenting an opportunity to explore their capability to perform ICL with many more demonstrating examples. In this work, we evaluate the performance of multimodal foundation models scaling from few-shot to many-shot ICL. We benchmark GPT-4o and Gemini 1.5 Pro across 10 datasets spanning multiple domains (natural imagery, medical imagery, remote sensing, and molecular imagery) and tasks (multi-class, multi-label, and fine-grained classification). We observe that many-shot ICL, including up to almost 2,000 multimodal demonstrating examples, leads to substantial improvements compared to few-shot (<100 examples) ICL across all of the datasets. Further, Gemini 1.5 Pro performance continues to improve log-linearly up to the maximum number of tested examples on many datasets. Given the high inference costs associated with the long prompts required for many-shot ICL, we also explore the impact of batching multiple queries in a single API call. We show that batching up to 50 queries can lead to performance improvements under zero-shot and many-shot ICL, with substantial gains in the zero-shot setting on multiple datasets, while drastically reducing per-query cost and latency. Finally, we measure ICL data efficiency of the models, or the rate at which the models learn from more demonstrating examples. We find that while GPT-4o and Gemini 1.5 Pro achieve similar zero-shot performance across the datasets, Gemini 1.5 Pro exhibits higher ICL data efficiency than GPT-4o on most datasets. Our results suggest that many-shot ICL could enable users to efficiently adapt multimodal foundation models to new applications and domains. Our codebase is publicly available at https://github.com/stanfordmlgroup/ManyICL .
5/17/2024
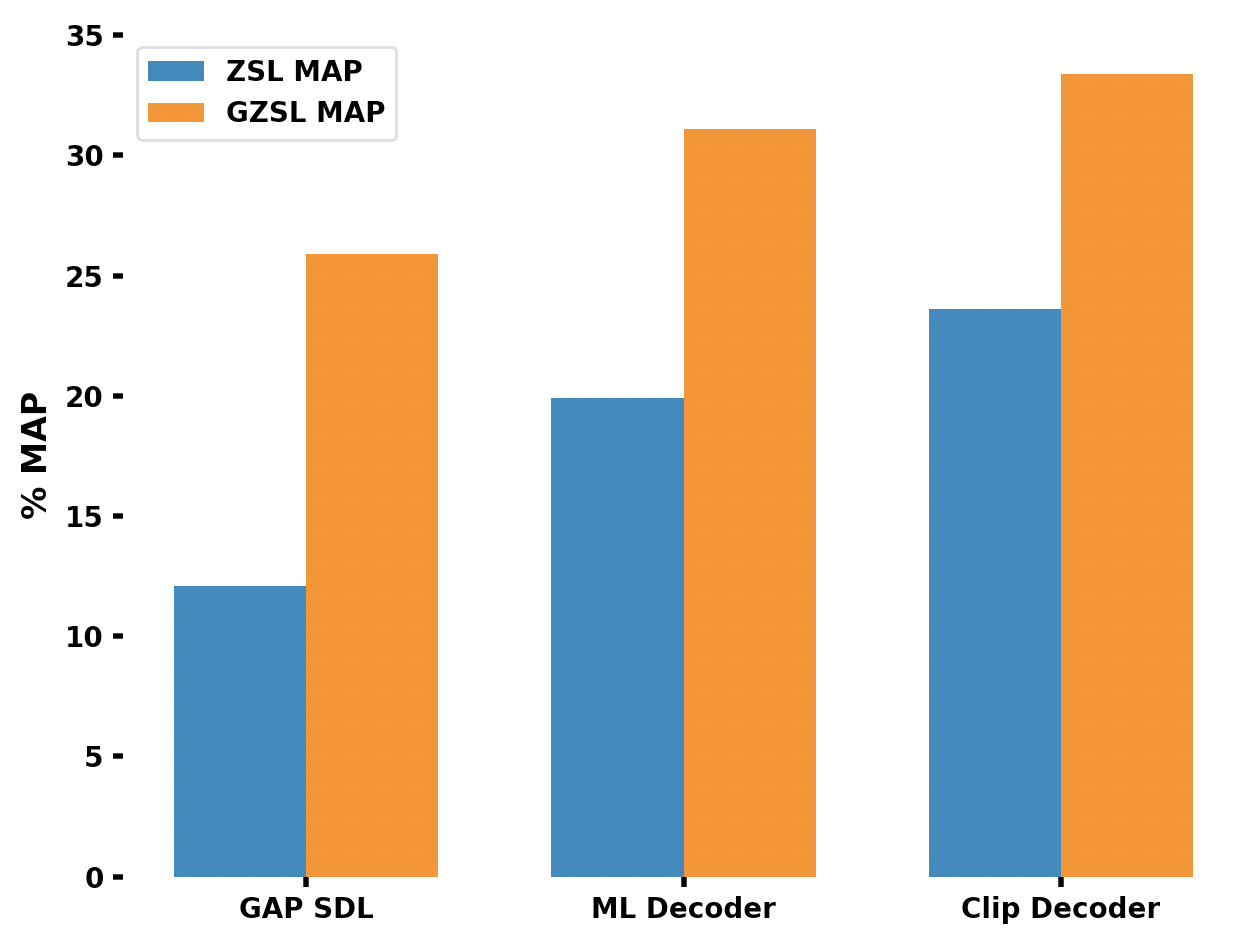
CLIP-Decoder : ZeroShot Multilabel Classification using Multimodal CLIP Aligned Representation
Muhammad Ali, Salman Khan
0
0
Multi-label classification is an essential task utilized in a wide variety of real-world applications. Multi-label zero-shot learning is a method for classifying images into multiple unseen categories for which no training data is available, while in general zero-shot situations, the test set may include observed classes. The CLIP-Decoder is a novel method based on the state-of-the-art ML-Decoder attention-based head. We introduce multi-modal representation learning in CLIP-Decoder, utilizing the text encoder to extract text features and the image encoder for image feature extraction. Furthermore, we minimize semantic mismatch by aligning image and word embeddings in the same dimension and comparing their respective representations using a combined loss, which comprises classification loss and CLIP loss. This strategy outperforms other methods and we achieve cutting-edge results on zero-shot multilabel classification tasks using CLIP-Decoder. Our method achieves an absolute increase of 3.9% in performance compared to existing methods for zero-shot learning multi-label classification tasks. Additionally, in the generalized zero-shot learning multi-label classification task, our method shows an impressive increase of almost 2.3%.
6/24/2024