DEX-TTS: Diffusion-based EXpressive Text-to-Speech with Style Modeling on Time Variability
2406.19135
0
0
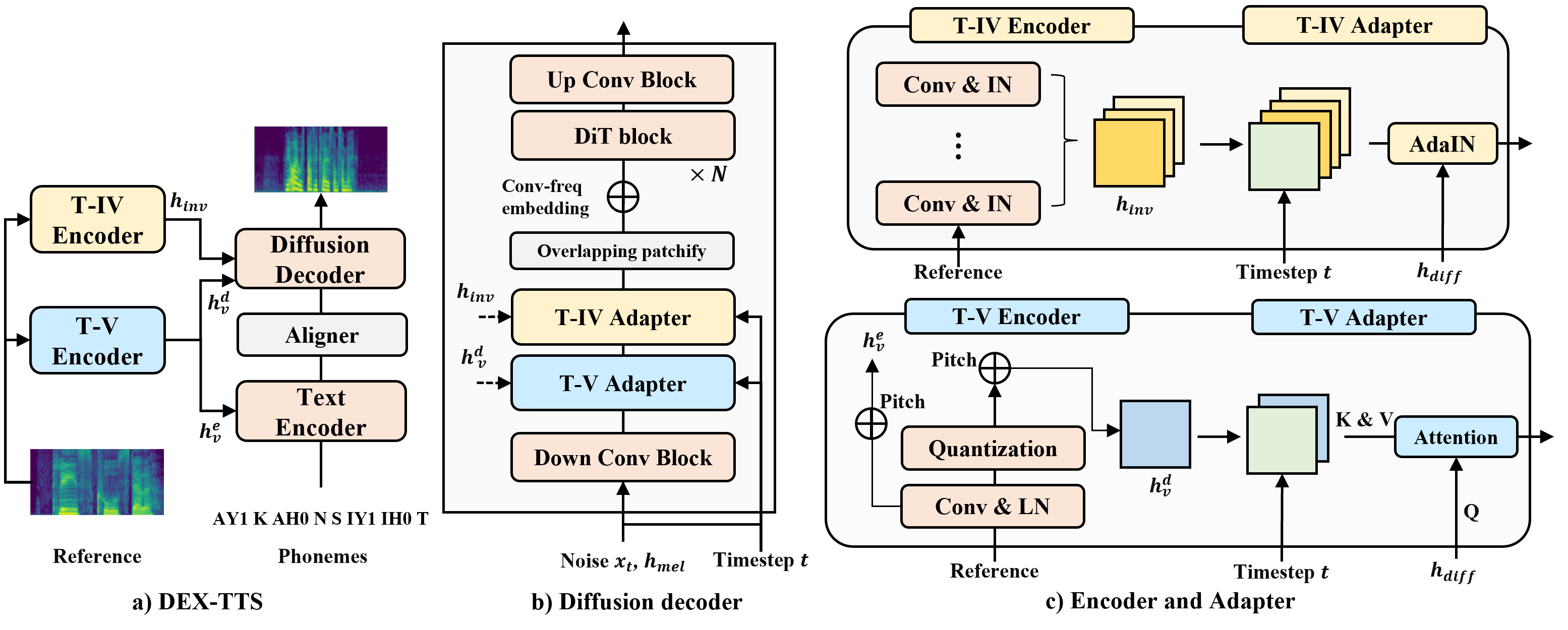
Abstract
Expressive Text-to-Speech (TTS) using reference speech has been studied extensively to synthesize natural speech, but there are limitations to obtaining well-represented styles and improving model generalization ability. In this study, we present Diffusion-based EXpressive TTS (DEX-TTS), an acoustic model designed for reference-based speech synthesis with enhanced style representations. Based on a general diffusion TTS framework, DEX-TTS includes encoders and adapters to handle styles extracted from reference speech. Key innovations contain the differentiation of styles into time-invariant and time-variant categories for effective style extraction, as well as the design of encoders and adapters with high generalization ability. In addition, we introduce overlapping patchify and convolution-frequency patch embedding strategies to improve DiT-based diffusion networks for TTS. DEX-TTS yields outstanding performance in terms of objective and subjective evaluation in English multi-speaker and emotional multi-speaker datasets, without relying on pre-training strategies. Lastly, the comparison results for the general TTS on a single-speaker dataset verify the effectiveness of our enhanced diffusion backbone. Demos are available here.
Create account to get full access
Overview
- This paper presents DEX-TTS, a novel diffusion-based text-to-speech (TTS) system that can generate expressive speech with time-varying styles.
- DEX-TTS models the time-varying nature of expressive speech by explicitly capturing the temporal dynamics of speech styles.
- The system leverages diffusion models, which have shown promising results in various generative tasks, to generate high-quality, expressive speech.
Plain English Explanation
DEX-TTS is a new type of text-to-speech (TTS) system that can produce expressive, emotion-filled speech. Traditional TTS systems often struggle to capture the nuances and changes in a speaker's voice over time, which is an important aspect of natural-sounding speech. DEX-TTS addresses this by explicitly modeling the temporal dynamics of different speech styles, such as happy, sad, or excited.
The key innovation in DEX-TTS is the use of "diffusion models," a type of machine learning approach that has shown impressive results in generating high-quality images and other types of data. By applying diffusion models to the task of TTS, the researchers were able to generate speech that sounds more natural and expressive, with convincing changes in tone, pitch, and rhythm over the course of a sentence or paragraph.
This advance in TTS technology could have important applications in areas like virtual assistants, audiobook narration, and voice acting, where the ability to convey emotion and personality through the voice is crucial. By making speech synthesis more naturalistic and expressive, DEX-TTS represents an important step forward in making AI-generated speech sound more human-like and engaging.
Technical Explanation
The core of DEX-TTS is a diffusion-based generative model that is designed to capture the time-varying nature of expressive speech. Diffusion models work by gradually adding noise to the target data (in this case, speech features) and then learning to reverse the process to generate new, high-quality samples.
To model the temporal dynamics of speech styles, the researchers introduced a novel conditioning scheme that allows the diffusion model to generate speech features conditioned on both the text input and a time-dependent style representation. This style representation is learned by the model and can evolve over the course of the speech generation process, enabling the model to produce expressive speech with naturally changing characteristics.
The DEX-TTS architecture consists of several key components: a text encoder to represent the input text, a style encoder to capture the time-varying style information, and a diffusion-based speech decoder that generates the final audio waveform. The model is trained end-to-end on a large dataset of expressive speech recordings.
Experiments show that DEX-TTS outperforms previous state-of-the-art TTS models in terms of objective speech quality metrics, as well as subjective evaluations of expressiveness and naturalness. The system is also shown to be capable of generating diverse speech styles by simply conditioning on different style representations.
Critical Analysis
The DEX-TTS paper presents a compelling approach to improving the expressiveness and natural-sounding qualities of text-to-speech systems. By explicitly modeling the temporal dynamics of speech styles, the researchers have addressed a key limitation of many existing TTS models, which struggle to capture the nuanced changes in a speaker's voice over time.
That said, the paper does not thoroughly explore the limitations of the DEX-TTS approach. For example, it is unclear how well the system would perform on less common or more specialized speech styles, or how robust it is to noisy or low-quality input text. Additionally, the computational requirements and inference latency of the diffusion-based architecture are not discussed in depth.
Further research could also investigate ways to enhance the interpretability and controllability of the learned style representations, which currently act as a black box. Enabling users to more directly manipulate the expressive qualities of the generated speech could broaden the practical applications of the technology.
Overall, the DEX-TTS paper represents an important advance in text-to-speech research, demonstrating the potential of diffusion models to generate highly expressive and natural-sounding speech. As the field continues to evolve, it will be important for future work to address the remaining challenges and limitations to make this technology more robust and accessible.
Conclusion
The DEX-TTS system presented in this paper represents a significant advancement in text-to-speech technology, with its ability to generate expressive and time-varying speech that sounds more natural and human-like than previous TTS models. By leveraging diffusion models to capture the temporal dynamics of speech styles, the researchers have opened up new possibilities for more engaging and personalized voice interfaces in a wide range of applications, from virtual assistants to audiobook narration.
While the paper highlights the promising capabilities of DEX-TTS, it also points to areas for further research and improvement, such as enhancing the interpretability and controllability of the system's learned representations. As diffusion models and other generative techniques continue to evolve, we can expect to see even more advances in the field of expressive text-to-speech in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
Keon Lee, Dong Won Kim, Jaehyeon Kim, Jaewoong Cho
0
0
Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
6/18/2024
Diffusion Synthesizer for Efficient Multilingual Speech to Speech Translation
Nameer Hirschkind, Xiao Yu, Mahesh Kumar Nandwana, Joseph Liu, Eloi DuBois, Dao Le, Nicolas Thiebaut, Colin Sinclair, Kyle Spence, Charles Shang, Zoe Abrams, Morgan McGuire
0
0
We introduce DiffuseST, a low-latency, direct speech-to-speech translation system capable of preserving the input speaker's voice zero-shot while translating from multiple source languages into English. We experiment with the synthesizer component of the architecture, comparing a Tacotron-based synthesizer to a novel diffusion-based synthesizer. We find the diffusion-based synthesizer to improve MOS and PESQ audio quality metrics by 23% each and speaker similarity by 5% while maintaining comparable BLEU scores. Despite having more than double the parameter count, the diffusion synthesizer has lower latency, allowing the entire model to run more than 5$times$ faster than real-time.
6/17/2024
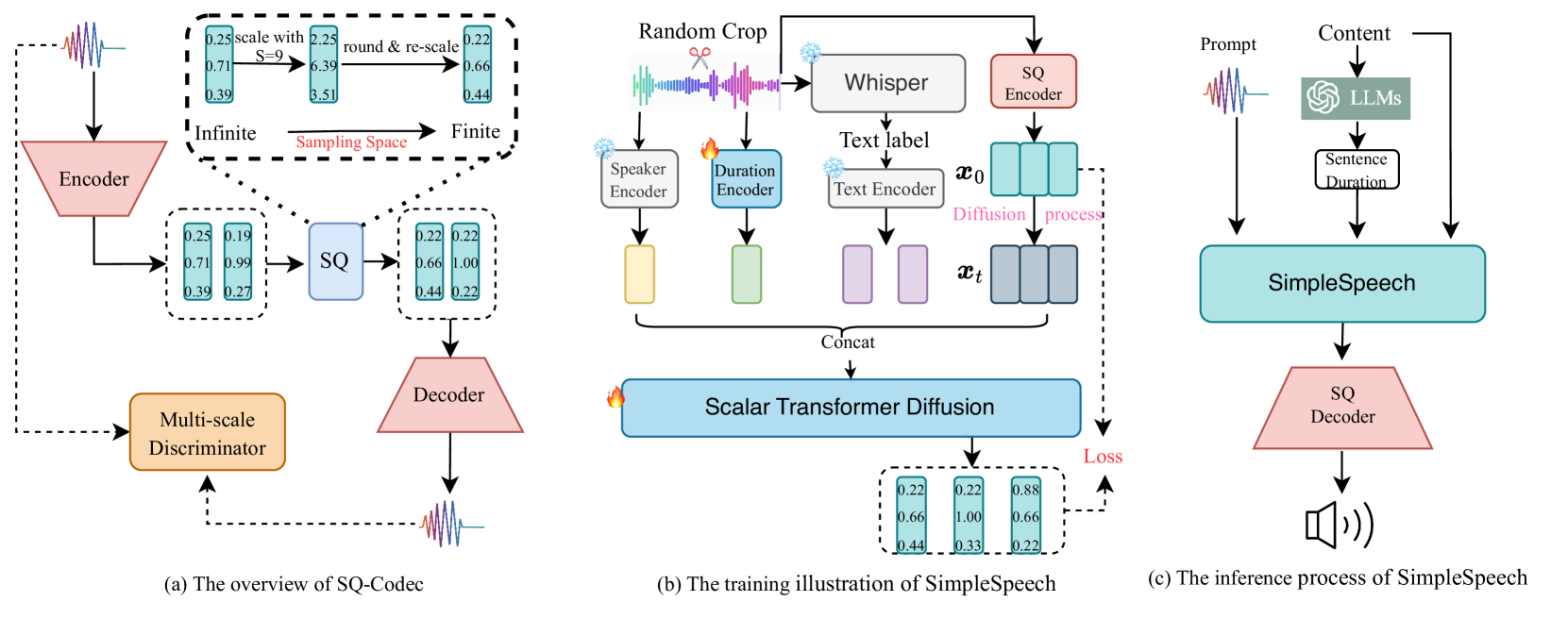
SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models
Dongchao Yang, Dingdong Wang, Haohan Guo, Xueyuan Chen, Xixin Wu, Helen Meng
0
0
In this study, we propose a simple and efficient Non-Autoregressive (NAR) text-to-speech (TTS) system based on diffusion, named SimpleSpeech. Its simpleness shows in three aspects: (1) It can be trained on the speech-only dataset, without any alignment information; (2) It directly takes plain text as input and generates speech through an NAR way; (3) It tries to model speech in a finite and compact latent space, which alleviates the modeling difficulty of diffusion. More specifically, we propose a novel speech codec model (SQ-Codec) with scalar quantization, SQ-Codec effectively maps the complex speech signal into a finite and compact latent space, named scalar latent space. Benefits from SQ-Codec, we apply a novel transformer diffusion model in the scalar latent space of SQ-Codec. We train SimpleSpeech on 4k hours of a speech-only dataset, it shows natural prosody and voice cloning ability. Compared with previous large-scale TTS models, it presents significant speech quality and generation speed improvement. Demos are released.
6/17/2024

Text-aware and Context-aware Expressive Audiobook Speech Synthesis
Dake Guo, Xinfa Zhu, Liumeng Xue, Yongmao Zhang, Wenjie Tian, Lei Xie
0
0
Recent advances in text-to-speech have significantly improved the expressiveness of synthetic speech. However, a major challenge remains in generating speech that captures the diverse styles exhibited by professional narrators in audiobooks without relying on manually labeled data or reference speech. To address this problem, we propose a text-aware and context-aware(TACA) style modeling approach for expressive audiobook speech synthesis. We first establish a text-aware style space to cover diverse styles via contrastive learning with the supervision of the speech style. Meanwhile, we adopt a context encoder to incorporate cross-sentence information and the style embedding obtained from text. Finally, we introduce the context encoder to two typical TTS models, VITS-based TTS and language model-based TTS. Experimental results demonstrate that our proposed approach can effectively capture diverse styles and coherent prosody, and consequently improves naturalness and expressiveness in audiobook speech synthesis.
6/13/2024