SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models
2406.02328
0
0
Abstract
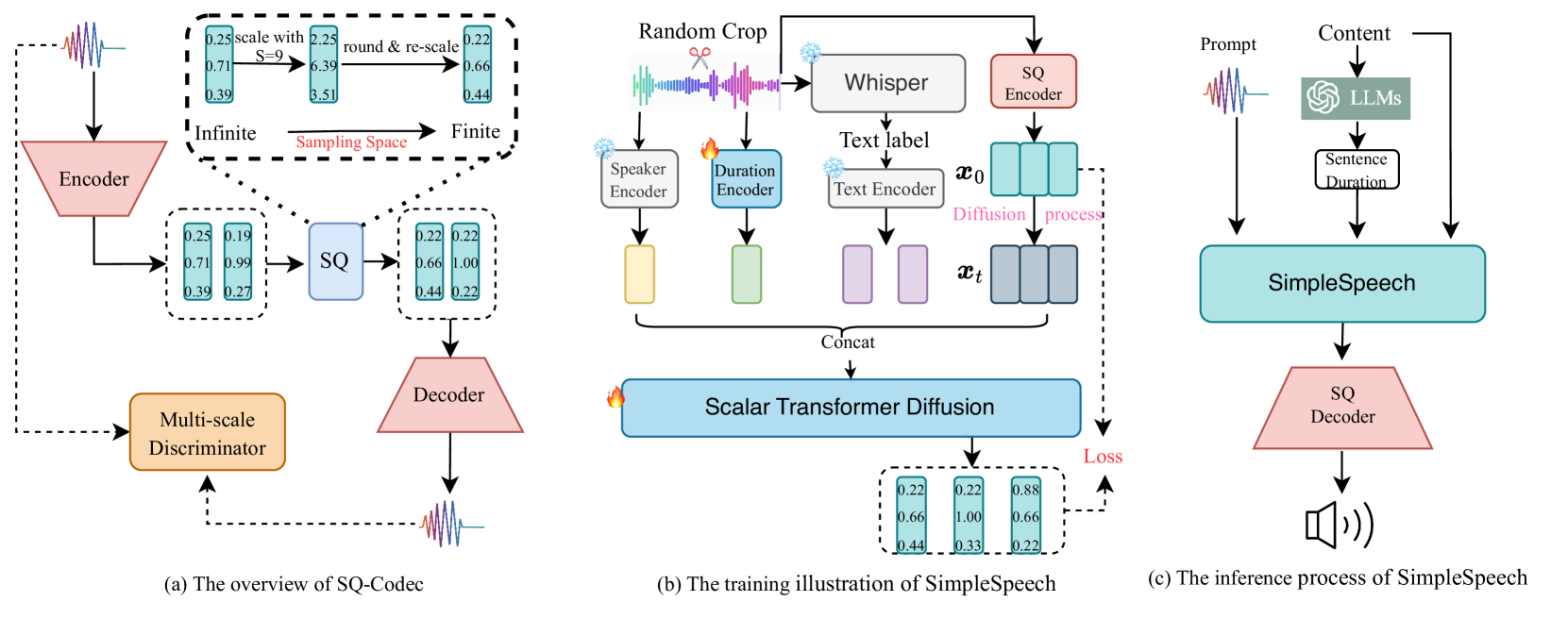
In this study, we propose a simple and efficient Non-Autoregressive (NAR) text-to-speech (TTS) system based on diffusion, named SimpleSpeech. Its simpleness shows in three aspects: (1) It can be trained on the speech-only dataset, without any alignment information; (2) It directly takes plain text as input and generates speech through an NAR way; (3) It tries to model speech in a finite and compact latent space, which alleviates the modeling difficulty of diffusion. More specifically, we propose a novel speech codec model (SQ-Codec) with scalar quantization, SQ-Codec effectively maps the complex speech signal into a finite and compact latent space, named scalar latent space. Benefits from SQ-Codec, we apply a novel transformer diffusion model in the scalar latent space of SQ-Codec. We train SimpleSpeech on 4k hours of a speech-only dataset, it shows natural prosody and voice cloning ability. Compared with previous large-scale TTS models, it presents significant speech quality and generation speed improvement. Demos are released.
Create account to get full access
Overview
- This paper introduces SimpleSpeech, a new text-to-speech (TTS) system that aims to be simple and efficient.
- It uses a scalar latent transformer diffusion model, which is a type of generative model, to generate high-quality speech from text.
- The authors claim SimpleSpeech achieves state-of-the-art performance on several TTS benchmarks while being more computationally efficient than previous methods.
Plain English Explanation
The SimpleSpeech paper describes a new way to convert written text into natural-sounding speech. Current text-to-speech (TTS) systems can produce high-quality audio, but they often require a lot of computing power. The researchers behind SimpleSpeech have developed a more efficient approach that uses a type of machine learning model called a "diffusion model."
Diffusion models work by gradually adding random noise to an image or audio signal, then learning how to reverse that process and generate new content from scratch. In the case of SimpleSpeech, the diffusion model learns to convert text into a compact "latent" representation, which is then used to produce the final speech audio.
The key innovation is that SimpleSpeech uses a "scalar" latent representation, meaning it represents the speech signal with a single value at each time step, rather than a more complex vector. This makes the model simpler and faster to run, while still allowing it to generate high-fidelity speech.
The authors show that SimpleSpeech matches or outperforms other state-of-the-art TTS models on standard benchmarks, while being more efficient in terms of computational resources required. This could make it useful for applications like mobile devices or embedded systems, where power and memory constraints are important.
Technical Explanation
The core of SimpleSpeech is a scalar latent transformer diffusion model that generates speech audio from text inputs. Unlike previous TTS systems that used complex vector-based representations, SimpleSpeech represents the speech signal as a sequence of scalar (single-value) latent codes.
The model works by first encoding the input text into a sequence of latent codes using a transformer-based encoder. It then applies a diffusion process to gradually add noise to these latent codes, and learns to reverse this diffusion to generate the final speech audio.
A key innovation is the use of a scalar latent representation, rather than a vector-based one. This allows the model to be more computationally efficient, as it only needs to predict a single value at each time step, rather than a higher-dimensional vector. The authors show that this scalar approach maintains high speech quality while significantly reducing the model's parameter count and inference time.
In their experiments, the authors evaluate SimpleSpeech on several TTS benchmarks, including LJSpeech, Blizzard, and M-AILABS. They demonstrate that SimpleSpeech achieves state-of-the-art performance on these datasets, matching or exceeding the quality of previous vector-based TTS models. At the same time, SimpleSpeech is more efficient, requiring less memory and computational resources during both training and inference.
Critical Analysis
The SimpleSpeech paper presents a promising approach to efficient text-to-speech generation, but there are a few potential limitations and areas for further research:
-
Generalization to other languages: The paper focuses on English TTS, and it's unclear how well the scalar latent diffusion approach would generalize to other languages with different phonetic and prosodic characteristics. Further research is needed to assess the cross-lingual capabilities of SimpleSpeech.
-
Impact of scalar latent representation: While the authors claim the scalar latent approach maintains high speech quality, it's possible that some nuances or details of the original speech signal may be lost compared to vector-based representations. The long-term impact of this simplification on perceived speech quality and intelligibility should be further investigated.
-
Subjective evaluation: The paper relies primarily on objective metrics like mean opinion score (MOS) to evaluate the quality of the generated speech. However, subjective human evaluation is also important to fully assess the naturalness and listenability of the output. Additional user studies could provide deeper insights into the perceptual qualities of SimpleSpeech.
-
Power and memory constraints: While the authors claim SimpleSpeech is more efficient in terms of computational resources, the specific power and memory savings for real-world deployment scenarios (e.g., on mobile devices) are not quantified. Further analysis of the practical implications of the efficiency gains would be valuable.
Overall, the SimpleSpeech approach is an interesting and potentially valuable contribution to the field of text-to-speech generation, particularly for applications where efficiency is a key concern. However, the limitations and areas for further research highlighted above suggest that additional work is needed to fully understand the capabilities and tradeoffs of this new TTS system.
Conclusion
The SimpleSpeech paper introduces a novel text-to-speech system that aims to be both high-quality and computationally efficient. By using a scalar latent transformer diffusion model, the authors have developed a TTS approach that matches or exceeds the performance of previous state-of-the-art methods while requiring significantly fewer computing resources.
This efficiency improvement could make SimpleSpeech a valuable tool for a wide range of TTS applications, from mobile devices to embedded systems, where power and memory constraints are crucial. While the paper highlights some potential limitations, such as the generalization to other languages and the impact of the scalar latent representation, the core ideas behind SimpleSpeech represent an important step forward in the quest for simple and effective text-to-speech technology.
As the field of artificial intelligence continues to advance, innovations like SimpleSpeech will likely play a crucial role in making high-quality speech synthesis more accessible and practical for a variety of real-world use cases. The insights and techniques presented in this paper could inspire further research and development in the area of efficient and versatile text-to-speech systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
Keon Lee, Dong Won Kim, Jaehyeon Kim, Jaewoong Cho
0
0
Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
6/18/2024
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Yanqing Liu, Yichong Leng, Kaitao Song, Siliang Tang, Zhizheng Wu, Tao Qin, Xiang-Yang Li, Wei Ye, Shikun Zhang, Jiang Bian, Lei He, Jinyu Li, Sheng Zhao
0
0
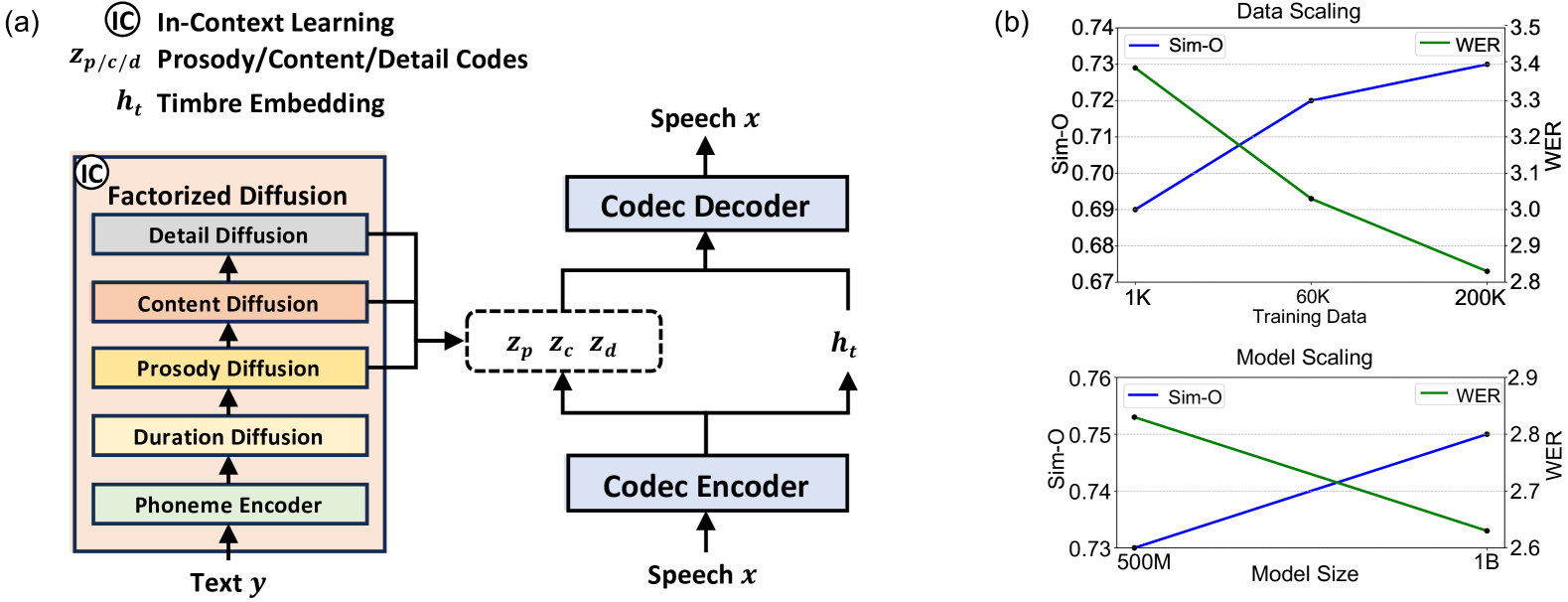
While recent large-scale text-to-speech (TTS) models have achieved significant progress, they still fall short in speech quality, similarity, and prosody. Considering speech intricately encompasses various attributes (e.g., content, prosody, timbre, and acoustic details) that pose significant challenges for generation, a natural idea is to factorize speech into individual subspaces representing different attributes and generate them individually. Motivated by it, we propose NaturalSpeech 3, a TTS system with novel factorized diffusion models to generate natural speech in a zero-shot way. Specifically, 1) we design a neural codec with factorized vector quantization (FVQ) to disentangle speech waveform into subspaces of content, prosody, timbre, and acoustic details; 2) we propose a factorized diffusion model to generate attributes in each subspace following its corresponding prompt. With this factorization design, NaturalSpeech 3 can effectively and efficiently model intricate speech with disentangled subspaces in a divide-and-conquer way. Experiments show that NaturalSpeech 3 outperforms the state-of-the-art TTS systems on quality, similarity, prosody, and intelligibility, and achieves on-par quality with human recordings. Furthermore, we achieve better performance by scaling to 1B parameters and 200K hours of training data.
4/24/2024
📈
Boosting Diffusion Model for Spectrogram Up-sampling in Text-to-speech: An Empirical Study
Chong Zhang, Yanqing Liu, Yang Zheng, Sheng Zhao
0
0
Scaling text-to-speech (TTS) with autoregressive language model (LM) to large-scale datasets by quantizing waveform into discrete speech tokens is making great progress to capture the diversity and expressiveness in human speech, but the speech reconstruction quality from discrete speech token is far from satisfaction depending on the compressed speech token compression ratio. Generative diffusion models trained with score-matching loss and continuous normalized flow trained with flow-matching loss have become prominent in generation of images as well as speech. LM based TTS systems usually quantize speech into discrete tokens and generate these tokens autoregressively, and finally use a diffusion model to up sample coarse-grained speech tokens into fine-grained codec features or mel-spectrograms before reconstructing into waveforms with vocoder, which has a high latency and is not realistic for real time speech applications. In this paper, we systematically investigate varied diffusion models for up sampling stage, which is the main bottleneck for streaming synthesis of LM and diffusion-based architecture, we present the model architecture, objective and subjective metrics to show quality and efficiency improvement.
6/10/2024

Autoregressive Diffusion Transformer for Text-to-Speech Synthesis
Zhijun Liu, Shuai Wang, Sho Inoue, Qibing Bai, Haizhou Li
0
0
Audio language models have recently emerged as a promising approach for various audio generation tasks, relying on audio tokenizers to encode waveforms into sequences of discrete symbols. Audio tokenization often poses a necessary compromise between code bitrate and reconstruction accuracy. When dealing with low-bitrate audio codes, language models are constrained to process only a subset of the information embedded in the audio, which in turn restricts their generative capabilities. To circumvent these issues, we propose encoding audio as vector sequences in continuous space $mathbb R^d$ and autoregressively generating these sequences using a decoder-only diffusion transformer (ARDiT). Our findings indicate that ARDiT excels in zero-shot text-to-speech and exhibits performance that compares to or even surpasses that of state-of-the-art models. High-bitrate continuous speech representation enables almost flawless reconstruction, allowing our model to achieve nearly perfect speech editing. Our experiments reveal that employing Integral Kullback-Leibler (IKL) divergence for distillation at each autoregressive step significantly boosts the perceived quality of the samples. Simultaneously, it condenses the iterative sampling process of the diffusion model into a single step. Furthermore, ARDiT can be trained to predict several continuous vectors in one step, significantly reducing latency during sampling. Impressively, one of our models can generate $170$ ms of $24$ kHz speech per evaluation step with minimal degradation in performance. Audio samples are available at http://ardit-tts.github.io/ .
6/11/2024