DiaHalu: A Dialogue-level Hallucination Evaluation Benchmark for Large Language Models
2403.00896
0
0

Abstract
Since large language models (LLMs) achieve significant success in recent years, the hallucination issue remains a challenge, numerous benchmarks are proposed to detect the hallucination. Nevertheless, some of these benchmarks are not naturally generated by LLMs but are intentionally induced. Also, many merely focus on the factuality hallucination while ignoring the faithfulness hallucination. Additionally, although dialogue pattern is more widely utilized in the era of LLMs, current benchmarks only concentrate on sentence-level and passage-level hallucination. In this study, we propose DiaHalu, the first dialogue-level hallucination evaluation benchmark to our knowledge. Initially, we integrate the collected topics into system prompts and facilitate a dialogue between two ChatGPT3.5. Subsequently, we manually modify the contents that do not adhere to human language conventions and then have LLMs re-generate, simulating authentic human-machine interaction scenarios. Finally, professional scholars annotate all the samples in the dataset. DiaHalu covers four common multi-turn dialogue domains and five hallucination subtypes, extended from factuality and faithfulness hallucination. Experiments through some well-known LLMs and detection methods on the dataset show that DiaHalu is a challenging benchmark, holding significant value for further research.
Create account to get full access
Overview
- This paper introduces DiaHalu, a new benchmark for evaluating the hallucination (generating false information) capabilities of large language models in a dialogue setting.
- The authors argue that existing hallucination evaluation benchmarks are limited to single-turn or monologue-style interactions, which may not capture the full complexity of multi-turn dialogues.
- DiaHalu aims to provide a more realistic and comprehensive assessment of language model hallucination by focusing on conversational contexts.
Plain English Explanation
The paper presents a new way to test how well large language models (like ChatGPT) can avoid hallucinating - that is, generating false or made-up information - during multi-turn conversations. Existing benchmarks for this only look at single responses or monologues, which doesn't fully capture the challenges of maintaining coherence and truthfulness over the course of a back-and-forth dialogue.
The DiaHalu benchmark aims to provide a more realistic and comprehensive assessment by focusing on conversational contexts. This allows researchers to better understand the hallucination tendencies of language models in more lifelike interactions, rather than just in isolated statements. The goal is to develop models that can engage in fluent and trustworthy dialogues, without making up facts or going off the rails.
Technical Explanation
The paper introduces the DiaHalu benchmark, which evaluates the hallucination capabilities of large language models in a dialogue setting. Existing hallucination benchmarks like HaluEval and Hallucinations Leaderboard focus on single-turn or monologue-style interactions, which may not capture the full complexity of multi-turn dialogues.
The DiaHalu benchmark consists of a dataset of human-written dialogues, with annotations identifying hallucinated statements. Models are evaluated on their ability to generate responses that avoid hallucinations and maintain coherence over the course of the conversation. The authors also introduce a new hallucination detection model called KnowHalu that leverages multiple knowledge sources to identify hallucinations.
Experiments show that state-of-the-art language models still struggle to avoid hallucinations in dialogue, highlighting the need for further research and development in this area. The authors argue that Small Agent approaches that empower smaller, more focused models may be a promising direction for improving hallucination robustness.
Critical Analysis
The DiaHalu benchmark represents an important step forward in evaluating the hallucination capabilities of language models in a more realistic, conversational setting. By focusing on multi-turn dialogues, the authors have identified a critical limitation in existing benchmarks and proposed a more comprehensive assessment framework.
One potential limitation of the DiaHalu dataset is that the dialogues may not fully capture the breadth of real-world conversational contexts. The authors acknowledge this and suggest that further expansion and diversification of the dataset could improve its representativeness.
Additionally, the KnowHalu hallucination detection model, while showing promising results, may still have room for improvement. Exploring other approaches to hallucination detection, perhaps leveraging more advanced reasoning or commonsense understanding capabilities, could further enhance the reliability of the benchmark.
Overall, the DiaHalu benchmark is a valuable contribution to the field of language model evaluation and development. By highlighting the importance of assessing hallucination in dialogues, it encourages researchers to pursue more robust and trustworthy conversational AI systems.
Conclusion
The DiaHalu benchmark represents a significant advancement in the evaluation of hallucination in large language models, moving beyond single-turn or monologue-style assessments to focus on the more complex and realistic setting of multi-turn dialogues.
By providing a dataset and evaluation framework specifically designed to capture the challenges of maintaining coherence and truthfulness over the course of a conversation, the authors have laid the groundwork for further research and development in this important area of conversational AI. The insights and lessons learned from the DiaHalu benchmark can help drive progress towards language models that can engage in fluent and trustworthy dialogues, a crucial step in realizing the full potential of these advanced technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

HalluDial: A Large-Scale Benchmark for Automatic Dialogue-Level Hallucination Evaluation
Wen Luo, Tianshu Shen, Wei Li, Guangyue Peng, Richeng Xuan, Houfeng Wang, Xi Yang
0
0
Large Language Models (LLMs) have significantly advanced the field of Natural Language Processing (NLP), achieving remarkable performance across diverse tasks and enabling widespread real-world applications. However, LLMs are prone to hallucination, generating content that either conflicts with established knowledge or is unfaithful to the original sources. Existing hallucination benchmarks primarily focus on sentence- or passage-level hallucination detection, neglecting dialogue-level evaluation, hallucination localization, and rationale provision. They also predominantly target factuality hallucinations while underestimating faithfulness hallucinations, often relying on labor-intensive or non-specialized evaluators. To address these limitations, we propose HalluDial, the first comprehensive large-scale benchmark for automatic dialogue-level hallucination evaluation. HalluDial encompasses both spontaneous and induced hallucination scenarios, covering factuality and faithfulness hallucinations. The benchmark includes 4,094 dialogues with a total of 146,856 samples. Leveraging HalluDial, we conduct a comprehensive meta-evaluation of LLMs' hallucination evaluation capabilities in information-seeking dialogues and introduce a specialized judge language model, HalluJudge. The high data quality of HalluDial enables HalluJudge to achieve superior or competitive performance in hallucination evaluation, facilitating the automatic assessment of dialogue-level hallucinations in LLMs and providing valuable insights into this phenomenon. The dataset and the code are available at https://github.com/FlagOpen/HalluDial.
6/12/2024
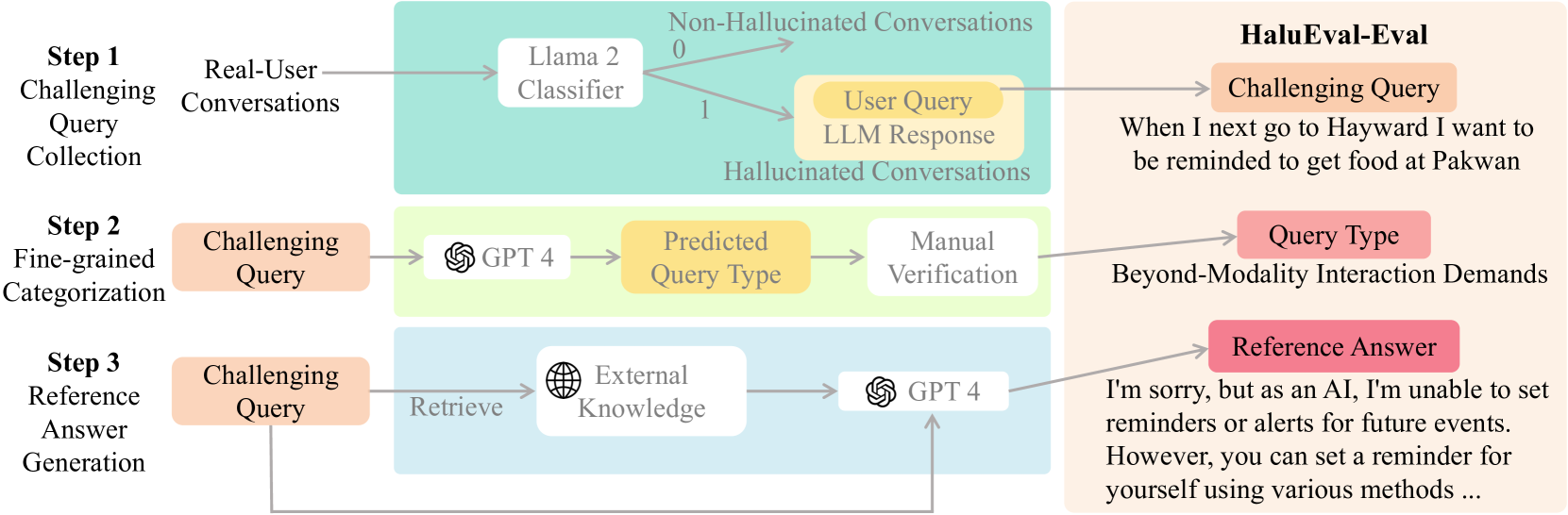
HaluEval-Wild: Evaluating Hallucinations of Language Models in the Wild
Zhiying Zhu, Yiming Yang, Zhiqing Sun
0
0
Hallucinations pose a significant challenge to the reliability of large language models (LLMs) in critical domains. Recent benchmarks designed to assess LLM hallucinations within conventional NLP tasks, such as knowledge-intensive question answering (QA) and summarization, are insufficient for capturing the complexities of user-LLM interactions in dynamic, real-world settings. To address this gap, we introduce HaluEval-Wild, the first benchmark specifically designed to evaluate LLM hallucinations in the wild. We meticulously collect challenging (adversarially filtered by Alpaca) user queries from existing real-world user-LLM interaction datasets, including ShareGPT, to evaluate the hallucination rates of various LLMs. Upon analyzing the collected queries, we categorize them into five distinct types, which enables a fine-grained analysis of the types of hallucinations LLMs exhibit, and synthesize the reference answers with the powerful GPT-4 model and retrieval-augmented generation (RAG). Our benchmark offers a novel approach towards enhancing our comprehension and improvement of LLM reliability in scenarios reflective of real-world interactions. Our benchmark is available at https://github.com/Dianezzy/HaluEval-Wild.
5/7/2024

New!ToolBeHonest: A Multi-level Hallucination Diagnostic Benchmark for Tool-Augmented Large Language Models
Yuxiang Zhang, Jing Chen, Junjie Wang, Yaxin Liu, Cheng Yang, Chufan Shi, Xinyu Zhu, Zihao Lin, Hanwen Wan, Yujiu Yang, Tetsuya Sakai, Tian Feng, Hayato Yamana
0
0
Tool-augmented large language models (LLMs) are rapidly being integrated into real-world applications. Due to the lack of benchmarks, the community still needs to fully understand the hallucination issues within these models. To address this challenge, we introduce a comprehensive diagnostic benchmark, ToolBH. Specifically, we assess the LLM's hallucinations through two perspectives: depth and breadth. In terms of depth, we propose a multi-level diagnostic process, including (1) solvability detection, (2) solution planning, and (3) missing-tool analysis. For breadth, we consider three scenarios based on the characteristics of the toolset: missing necessary tools, potential tools, and limited functionality tools. Furthermore, we developed seven tasks and collected 700 evaluation samples through multiple rounds of manual annotation. The results show the significant challenges presented by the ToolBH benchmark. The current advanced models Gemini-1.5-Pro and GPT-4o only achieve a total score of 45.3 and 37.0, respectively, on a scale of 100. In this benchmark, larger model parameters do not guarantee better performance; the training data and response strategies also play a crucial role in tool-enhanced LLM scenarios. Our diagnostic analysis indicates that the primary reason for model errors lies in assessing task solvability. Additionally, open-weight models suffer from performance drops with verbose replies, whereas proprietary models excel with longer reasoning.
7/1/2024
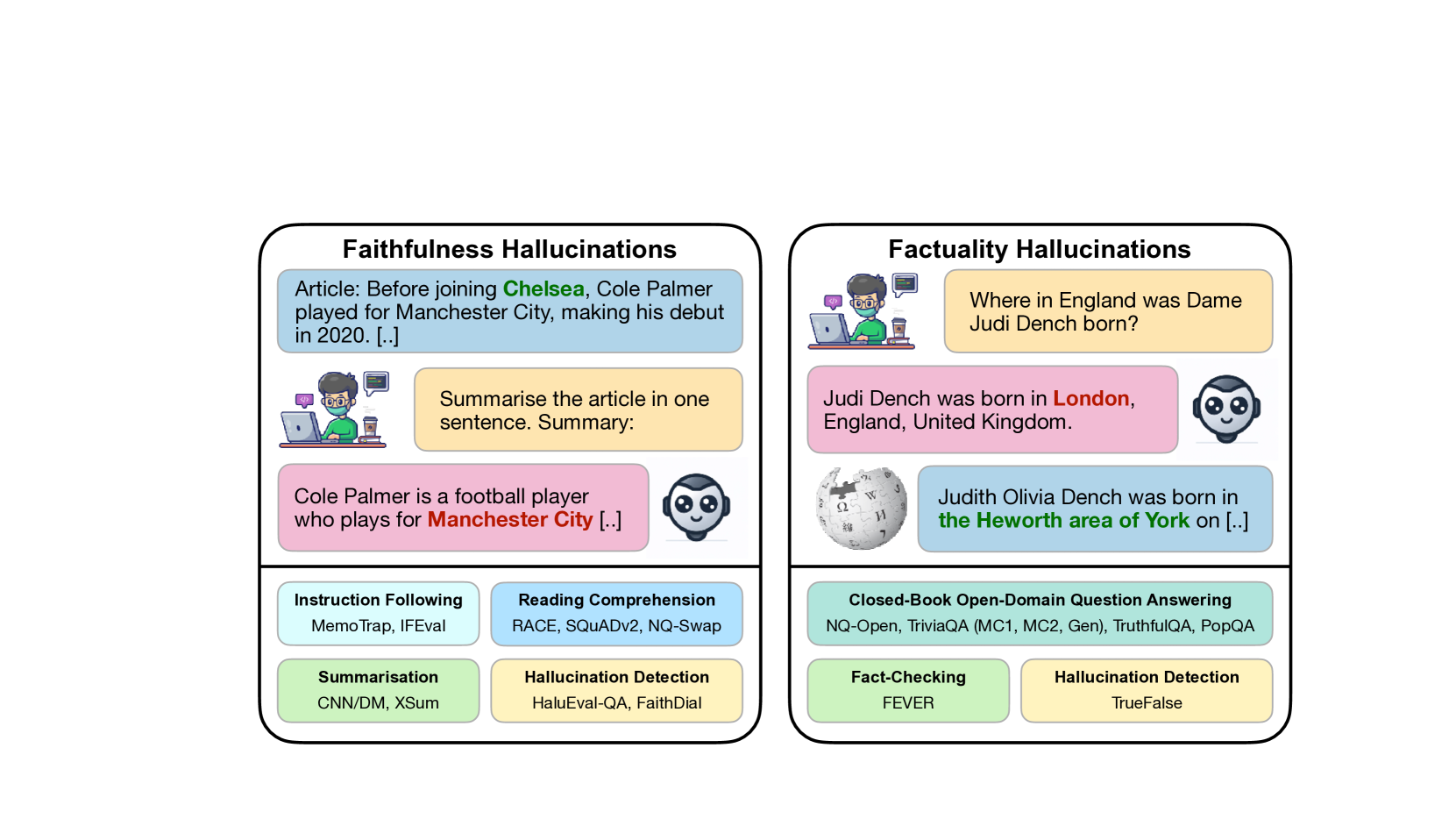
The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models
Giwon Hong, Aryo Pradipta Gema, Rohit Saxena, Xiaotang Du, Ping Nie, Yu Zhao, Laura Perez-Beltrachini, Max Ryabinin, Xuanli He, Pasquale Minervini
0
0
Large Language Models (LLMs) have transformed the Natural Language Processing (NLP) landscape with their remarkable ability to understand and generate human-like text. However, these models are prone to ``hallucinations'' -- outputs that do not align with factual reality or the input context. This paper introduces the Hallucinations Leaderboard, an open initiative to quantitatively measure and compare the tendency of each model to produce hallucinations. The leaderboard uses a comprehensive set of benchmarks focusing on different aspects of hallucinations, such as factuality and faithfulness, across various tasks, including question-answering, summarisation, and reading comprehension. Our analysis provides insights into the performance of different models, guiding researchers and practitioners in choosing the most reliable models for their applications.
4/10/2024