HalluDial: A Large-Scale Benchmark for Automatic Dialogue-Level Hallucination Evaluation
2406.07070
0
0

Abstract
Large Language Models (LLMs) have significantly advanced the field of Natural Language Processing (NLP), achieving remarkable performance across diverse tasks and enabling widespread real-world applications. However, LLMs are prone to hallucination, generating content that either conflicts with established knowledge or is unfaithful to the original sources. Existing hallucination benchmarks primarily focus on sentence- or passage-level hallucination detection, neglecting dialogue-level evaluation, hallucination localization, and rationale provision. They also predominantly target factuality hallucinations while underestimating faithfulness hallucinations, often relying on labor-intensive or non-specialized evaluators. To address these limitations, we propose HalluDial, the first comprehensive large-scale benchmark for automatic dialogue-level hallucination evaluation. HalluDial encompasses both spontaneous and induced hallucination scenarios, covering factuality and faithfulness hallucinations. The benchmark includes 4,094 dialogues with a total of 146,856 samples. Leveraging HalluDial, we conduct a comprehensive meta-evaluation of LLMs' hallucination evaluation capabilities in information-seeking dialogues and introduce a specialized judge language model, HalluJudge. The high data quality of HalluDial enables HalluJudge to achieve superior or competitive performance in hallucination evaluation, facilitating the automatic assessment of dialogue-level hallucinations in LLMs and providing valuable insights into this phenomenon. The dataset and the code are available at https://github.com/FlagOpen/HalluDial.
Create account to get full access
Overview
- This paper introduces a new benchmark called HalluDial for evaluating the ability of language models to avoid generating hallucinated content in dialogues.
- Hallucination refers to the generation of factually incorrect or nonsensical information that is not grounded in the given context.
- The HalluDial benchmark includes a large-scale dataset of human-written dialogues that have been carefully annotated for hallucinations.
- The paper also presents baselines for hallucination detection using state-of-the-art language models and discusses the challenges of this task.
Plain English Explanation
HalluDial: A Large-Scale Benchmark for Automatic Dialogue-Level Hallucination Evaluation introduces a new way to test how well AI language models can avoid generating false or nonsensical information in conversations. When language models "hallucinate" - produce content that is not grounded in the given context - it can be problematic, especially in applications like dialogue systems.
The researchers created a large dataset of human-written dialogues and carefully annotated them to identify instances of hallucination. This dataset, called HalluDial, can be used to evaluate how well different language models are able to avoid hallucinating during a conversation.
The paper also provides some initial baseline results using state-of-the-art language models to detect hallucinations. However, the authors note that this is a challenging task and there is still significant room for improvement.
By developing this benchmark and highlighting the challenges of avoiding hallucinations, the researchers hope to spur further advancements in the development of more robust and trustworthy conversational AI systems.
Technical Explanation
The HalluDial Benchmark is a new dataset and evaluation framework for assessing a language model's ability to avoid generating hallucinated content in dialogues. Hallucination refers to the production of factually incorrect or nonsensical information that is not grounded in the provided context.
The dataset consists of over 30,000 human-written dialogues across 6 different domains, including movies, books, and current events. Each dialogue has been manually annotated to identify hallucinated utterances, providing a high-quality ground truth for evaluating model performance.
The paper also presents baseline results using state-of-the-art language models like GPT-3 and T5 for the task of hallucination detection. These models achieve reasonable performance, but the authors note that there is significant room for improvement, as detecting hallucinations remains a challenging problem.
Critical Analysis
The HalluDial benchmark is a valuable contribution to the field of conversational AI, as it provides a standardized way to evaluate a model's ability to avoid hallucinating during dialogues. This is an important capability, as hallucinations can undermine the trustworthiness and usefulness of dialogue systems in real-world applications.
One potential limitation of the dataset is that it may not capture the full diversity of hallucination types that can occur in real-world conversations. The authors acknowledge this and suggest that future work could expand the dataset to include a wider range of dialogue scenarios and hallucination patterns.
Additionally, while the baseline results provide a useful starting point, the authors note that the task of hallucination detection remains quite challenging. Further research is needed to develop more robust and accurate methods for identifying and mitigating hallucinations in conversational AI systems.
A related paper, "Unified Hallucination Detection for Multimodal Large Language Models", explores the use of multimodal information to improve hallucination detection, which could be a promising direction for future work.
Conclusion
The HalluDial benchmark represents an important step forward in the development of more trustworthy and reliable conversational AI systems. By providing a standardized dataset and evaluation framework for assessing a model's ability to avoid hallucinations, the researchers have created a valuable tool for the research community.
Continued advancements in this area could have significant implications for the real-world deployment of dialogue systems, helping to ensure that they provide users with accurate and grounded information. As the Hallucinations Leaderboard and other related efforts demonstrate, this is an active area of research with the potential to drive transformative progress in the field of conversational AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DiaHalu: A Dialogue-level Hallucination Evaluation Benchmark for Large Language Models
Kedi Chen, Qin Chen, Jie Zhou, Yishen He, Liang He
0
0
Since large language models (LLMs) achieve significant success in recent years, the hallucination issue remains a challenge, numerous benchmarks are proposed to detect the hallucination. Nevertheless, some of these benchmarks are not naturally generated by LLMs but are intentionally induced. Also, many merely focus on the factuality hallucination while ignoring the faithfulness hallucination. Additionally, although dialogue pattern is more widely utilized in the era of LLMs, current benchmarks only concentrate on sentence-level and passage-level hallucination. In this study, we propose DiaHalu, the first dialogue-level hallucination evaluation benchmark to our knowledge. Initially, we integrate the collected topics into system prompts and facilitate a dialogue between two ChatGPT3.5. Subsequently, we manually modify the contents that do not adhere to human language conventions and then have LLMs re-generate, simulating authentic human-machine interaction scenarios. Finally, professional scholars annotate all the samples in the dataset. DiaHalu covers four common multi-turn dialogue domains and five hallucination subtypes, extended from factuality and faithfulness hallucination. Experiments through some well-known LLMs and detection methods on the dataset show that DiaHalu is a challenging benchmark, holding significant value for further research.
6/18/2024
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
Jiawei Chen, Dingkang Yang, Tong Wu, Yue Jiang, Xiaolu Hou, Mingcheng Li, Shunli Wang, Dongling Xiao, Ke Li, Lihua Zhang
0
0
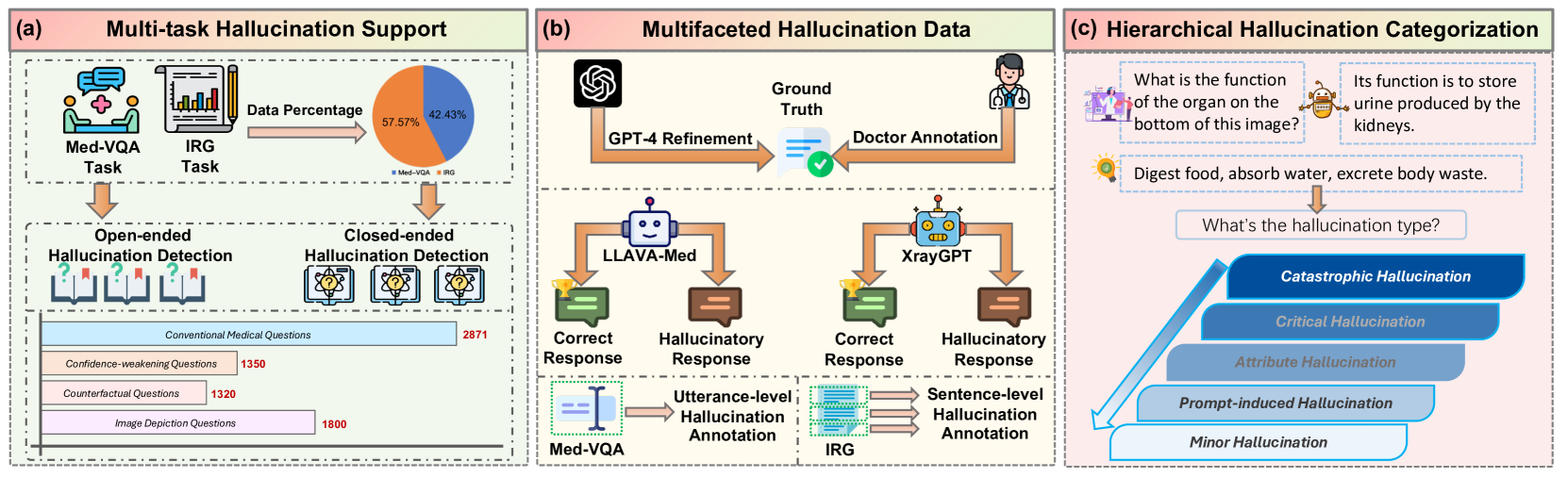
Large Vision Language Models (LVLMs) are increasingly integral to healthcare applications, including medical visual question answering and imaging report generation. While these models inherit the robust capabilities of foundational Large Language Models (LLMs), they also inherit susceptibility to hallucinations-a significant concern in high-stakes medical contexts where the margin for error is minimal. However, currently, there are no dedicated methods or benchmarks for hallucination detection and evaluation in the medical field. To bridge this gap, we introduce Med-HallMark, the first benchmark specifically designed for hallucination detection and evaluation within the medical multimodal domain. This benchmark provides multi-tasking hallucination support, multifaceted hallucination data, and hierarchical hallucination categorization. Furthermore, we propose the MediHall Score, a new medical evaluative metric designed to assess LVLMs' hallucinations through a hierarchical scoring system that considers the severity and type of hallucination, thereby enabling a granular assessment of potential clinical impacts. We also present MediHallDetector, a novel Medical LVLM engineered for precise hallucination detection, which employs multitask training for hallucination detection. Through extensive experimental evaluations, we establish baselines for popular LVLMs using our benchmark. The findings indicate that MediHall Score provides a more nuanced understanding of hallucination impacts compared to traditional metrics and demonstrate the enhanced performance of MediHallDetector. We hope this work can significantly improve the reliability of LVLMs in medical applications. All resources of this work will be released soon.
6/17/2024
HaluEval-Wild: Evaluating Hallucinations of Language Models in the Wild
Zhiying Zhu, Yiming Yang, Zhiqing Sun
0
0
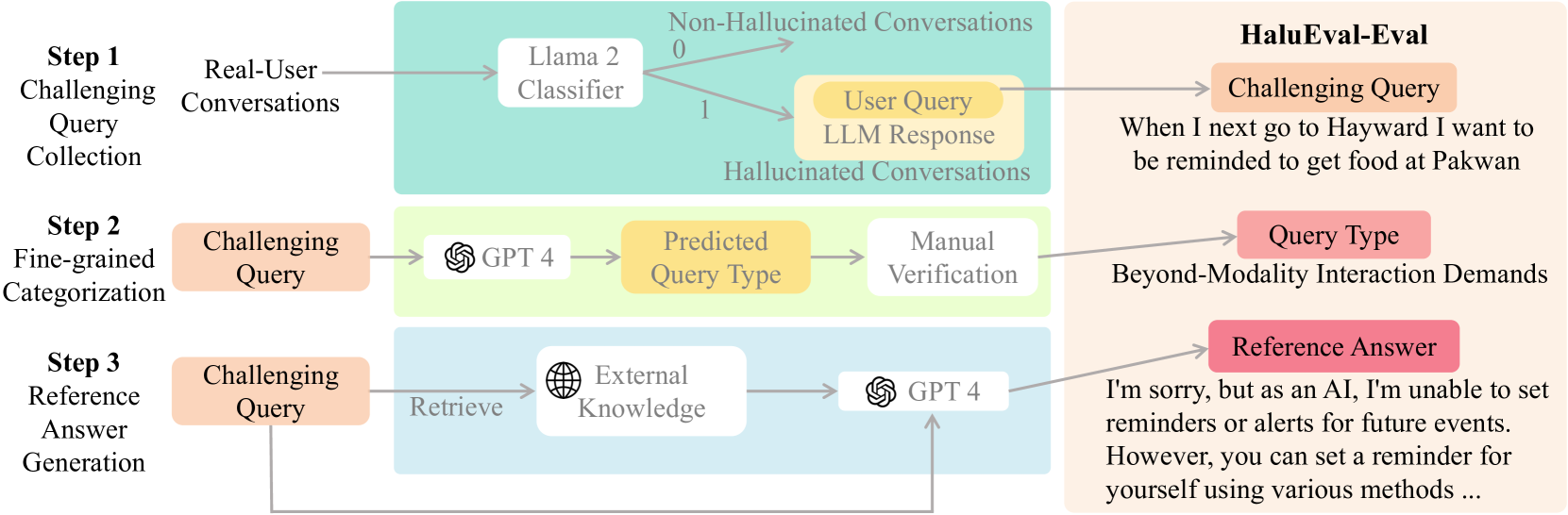
Hallucinations pose a significant challenge to the reliability of large language models (LLMs) in critical domains. Recent benchmarks designed to assess LLM hallucinations within conventional NLP tasks, such as knowledge-intensive question answering (QA) and summarization, are insufficient for capturing the complexities of user-LLM interactions in dynamic, real-world settings. To address this gap, we introduce HaluEval-Wild, the first benchmark specifically designed to evaluate LLM hallucinations in the wild. We meticulously collect challenging (adversarially filtered by Alpaca) user queries from existing real-world user-LLM interaction datasets, including ShareGPT, to evaluate the hallucination rates of various LLMs. Upon analyzing the collected queries, we categorize them into five distinct types, which enables a fine-grained analysis of the types of hallucinations LLMs exhibit, and synthesize the reference answers with the powerful GPT-4 model and retrieval-augmented generation (RAG). Our benchmark offers a novel approach towards enhancing our comprehension and improvement of LLM reliability in scenarios reflective of real-world interactions. Our benchmark is available at https://github.com/Dianezzy/HaluEval-Wild.
5/7/2024
🔎
Unified Hallucination Detection for Multimodal Large Language Models
Xiang Chen, Chenxi Wang, Yida Xue, Ningyu Zhang, Xiaoyan Yang, Qiang Li, Yue Shen, Lei Liang, Jinjie Gu, Huajun Chen
0
0
Despite significant strides in multimodal tasks, Multimodal Large Language Models (MLLMs) are plagued by the critical issue of hallucination. The reliable detection of such hallucinations in MLLMs has, therefore, become a vital aspect of model evaluation and the safeguarding of practical application deployment. Prior research in this domain has been constrained by a narrow focus on singular tasks, an inadequate range of hallucination categories addressed, and a lack of detailed granularity. In response to these challenges, our work expands the investigative horizons of hallucination detection. We present a novel meta-evaluation benchmark, MHaluBench, meticulously crafted to facilitate the evaluation of advancements in hallucination detection methods. Additionally, we unveil a novel unified multimodal hallucination detection framework, UNIHD, which leverages a suite of auxiliary tools to validate the occurrence of hallucinations robustly. We demonstrate the effectiveness of UNIHD through meticulous evaluation and comprehensive analysis. We also provide strategic insights on the application of specific tools for addressing various categories of hallucinations.
5/28/2024