DIDI: Diffusion-Guided Diversity for Offline Behavioral Generation
2405.14790
0
0
🛸
Abstract
In this paper, we propose a novel approach called DIffusion-guided DIversity (DIDI) for offline behavioral generation. The goal of DIDI is to learn a diverse set of skills from a mixture of label-free offline data. We achieve this by leveraging diffusion probabilistic models as priors to guide the learning process and regularize the policy. By optimizing a joint objective that incorporates diversity and diffusion-guided regularization, we encourage the emergence of diverse behaviors while maintaining the similarity to the offline data. Experimental results in four decision-making domains (Push, Kitchen, Humanoid, and D4RL tasks) show that DIDI is effective in discovering diverse and discriminative skills. We also introduce skill stitching and skill interpolation, which highlight the generalist nature of the learned skill space. Further, by incorporating an extrinsic reward function, DIDI enables reward-guided behavior generation, facilitating the learning of diverse and optimal behaviors from sub-optimal data.
Create account to get full access
Overview
- Proposes a novel approach called Diffusion-guided Diversity (DIDI) for offline behavioral generation
- Aims to learn a diverse set of skills from unlabeled offline data
- Leverages diffusion probabilistic models as priors to guide the learning process and regularize the policy
- Optimizes a joint objective that incorporates diversity and diffusion-guided regularization
- Experiments show DIDI is effective in discovering diverse and discriminative skills
Plain English Explanation
The paper presents a new method called DIDI: Diffusion-guided Diversity that can learn a wide range of skills from a collection of unlabeled data. The key idea is to use a special type of machine learning model called a "diffusion model" as a guide to help the system discover diverse and useful skills.
Diffusion models are a powerful tool for generating new data that is similar to the examples in the training set. In this case, the researchers use the diffusion model as a kind of "teacher" to ensure that the skills learned by the system stay close to the original offline data, while also encouraging the system to explore a wide range of different behaviors.
By optimizing a joint objective that balances diversity and similarity to the data, the DIDI method is able to discover a diverse set of discriminative skills from the unlabeled offline data. The system can then use these learned skills in creative ways, like stitching them together or interpolating between them.
The researchers also show that by incorporating an external reward function, the DIDI method can be used to learn diverse and optimal behaviors from sub-optimal data, which could be very useful in real-world applications.
Technical Explanation
The core of the DIDI approach is the use of diffusion probabilistic models as priors to guide the learning process and regularize the policy. Diffusion models are a type of generative model that learns to transform simple noise distributions into complex data distributions through a process of gradual refinement.
By leveraging the diffusion model as a prior, the DIDI method encourages the learned policies to stay close to the offline data distribution while also exploring a diverse range of behaviors. This is achieved by optimizing a joint objective that incorporates both diversity and diffusion-guided regularization.
The diversity objective encourages the policies to exhibit a wide range of distinct skills, while the diffusion-guided regularization term ensures that the learned behaviors remain similar to the original offline data. By balancing these two forces, the DIDI method is able to discover a diverse set of discriminative skills that capture the rich structure of the offline dataset.
The researchers demonstrate the effectiveness of DIDI on a variety of decision-making domains, including robotic manipulation tasks (Push, Kitchen) and locomotion tasks (Humanoid, D4RL). The results show that DIDI outperforms existing methods in terms of both skill diversity and task performance.
Critical Analysis
The paper presents a compelling and technically sound approach for learning diverse skills from offline data. However, there are a few potential limitations and areas for further research that could be explored:
-
Reliance on Diffusion Models: The performance of DIDI is heavily dependent on the quality of the diffusion model used as a prior. If the diffusion model is not well-suited to the task domain, it may not provide an effective guide for the skill learning process. Exploring alternative ways to incorporate domain knowledge or other types of priors could be an interesting direction for future research.
-
Scalability to High-Dimensional Domains: The experiments in the paper focus on relatively low-dimensional decision-making tasks. It's unclear how well the DIDI approach would scale to more complex, high-dimensional domains, such as those involving rich sensory inputs or long-horizon planning. Investigating the performance and computational feasibility of DIDI in these settings would be valuable.
-
Interpretability and Controllability: While the paper highlights the diverse and discriminative nature of the learned skills, it does not provide much insight into the underlying structure or interpretability of these skills. Developing methods to better understand and control the skill discovery process could enhance the practical utility of the DIDI approach.
-
Handling Suboptimal Data: The paper demonstrates DIDI's ability to learn diverse and optimal behaviors from sub-optimal data by incorporating an extrinsic reward function. However, the specific challenges and limitations of this approach in the face of severely suboptimal data are not fully explored.
Overall, the DIDI method presents a promising direction for offline behavioral generation and skill discovery. By leveraging diffusion models as priors, the approach shows the potential to unlock diverse and useful skills from unlabeled datasets. Continued research in this area could yield valuable insights and advancements in the field of reinforcement learning and robotic control.
Conclusion
The DIDI: Diffusion-guided Diversity paper introduces a novel approach for learning a diverse set of skills from offline, unlabeled data. By using diffusion probabilistic models as priors to guide the learning process, the DIDI method is able to discover a wide range of discriminative skills that capture the rich structure of the original dataset.
The key contributions of this work include:
- Diverse Skill Discovery: DIDI is effective in learning a diverse set of skills from offline data, outperforming existing methods in both skill diversity and task performance.
- Skill Stitching and Interpolation: The learned skill space supports creative applications like skill stitching and interpolation, highlighting the generalist nature of the skills.
- Reward-Guided Behavior Generation: By incorporating an extrinsic reward function, DIDI can enable the learning of diverse and optimal behaviors from sub-optimal data.
Overall, the DIDI approach represents an important step forward in the field of offline behavioral generation, with the potential to unlock new possibilities for skill-based control and decision-making systems. As the research in this area continues to evolve, the insights and techniques presented in this paper could have far-reaching implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
Offline Diversity Maximization Under Imitation Constraints
Marin Vlastelica, Jin Cheng, Georg Martius, Pavel Kolev
0
0
There has been significant recent progress in the area of unsupervised skill discovery, utilizing various information-theoretic objectives as measures of diversity. Despite these advances, challenges remain: current methods require significant online interaction, fail to leverage vast amounts of available task-agnostic data and typically lack a quantitative measure of skill utility. We address these challenges by proposing a principled offline algorithm for unsupervised skill discovery that, in addition to maximizing diversity, ensures that each learned skill imitates state-only expert demonstrations to a certain degree. Our main analytical contribution is to connect Fenchel duality, reinforcement learning, and unsupervised skill discovery to maximize a mutual information objective subject to KL-divergence state occupancy constraints. Furthermore, we demonstrate the effectiveness of our method on the standard offline benchmark D4RL and on a custom offline dataset collected from a 12-DoF quadruped robot for which the policies trained in simulation transfer well to the real robotic system.
6/24/2024
📊
MADiff: Offline Multi-agent Learning with Diffusion Models
Zhengbang Zhu, Minghuan Liu, Liyuan Mao, Bingyi Kang, Minkai Xu, Yong Yu, Stefano Ermon, Weinan Zhang
0
0
Diffusion model (DM) recently achieved huge success in various scenarios including offline reinforcement learning, where the diffusion planner learn to generate desired trajectories during online evaluations. However, despite the effectiveness in single-agent learning, it remains unclear how DMs can operate in multi-agent problems, where agents can hardly complete teamwork without good coordination by independently modeling each agent's trajectories. In this paper, we propose MADiff, a novel generative multi-agent learning framework to tackle this problem. MADiff is realized with an attention-based diffusion model to model the complex coordination among behaviors of multiple agents. To the best of our knowledge, MADiff is the first diffusion-based multi-agent learning framework, which behaves as both a decentralized policy and a centralized controller. During decentralized executions, MADiff simultaneously performs teammate modeling, and the centralized controller can also be applied in multi-agent trajectory predictions. Our experiments show the superior performance of MADiff compared to baseline algorithms in a wide range of multi-agent learning tasks, which emphasizes the effectiveness of MADiff in modeling complex multi-agent interactions. Our code is available at https://github.com/zbzhu99/madiff.
5/28/2024
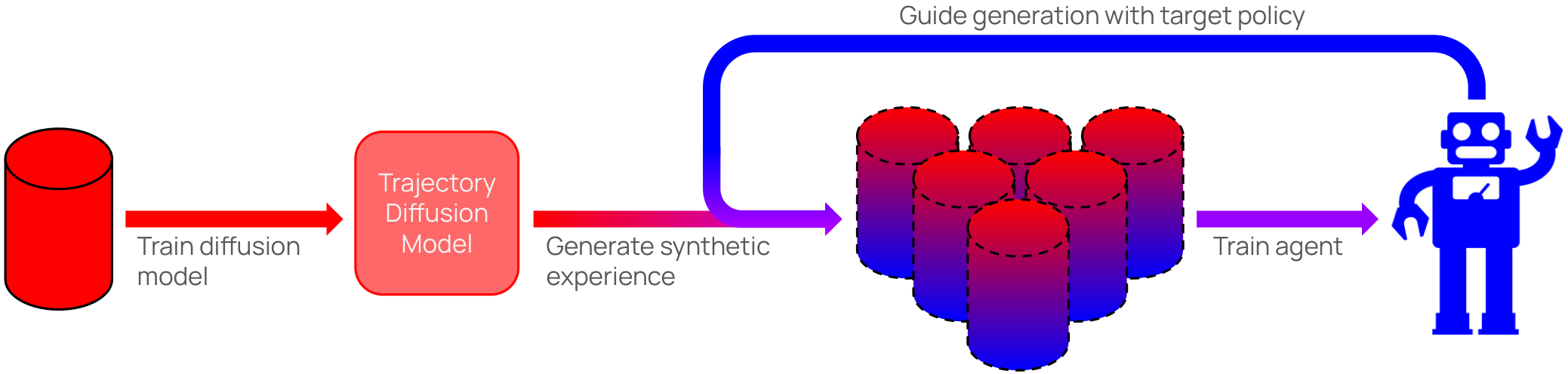
Policy-Guided Diffusion
Matthew Thomas Jackson, Michael Tryfan Matthews, Cong Lu, Benjamin Ellis, Shimon Whiteson, Jakob Foerster
0
0
In many real-world settings, agents must learn from an offline dataset gathered by some prior behavior policy. Such a setting naturally leads to distribution shift between the behavior policy and the target policy being trained - requiring policy conservatism to avoid instability and overestimation bias. Autoregressive world models offer a different solution to this by generating synthetic, on-policy experience. However, in practice, model rollouts must be severely truncated to avoid compounding error. As an alternative, we propose policy-guided diffusion. Our method uses diffusion models to generate entire trajectories under the behavior distribution, applying guidance from the target policy to move synthetic experience further on-policy. We show that policy-guided diffusion models a regularized form of the target distribution that balances action likelihood under both the target and behavior policies, leading to plausible trajectories with high target policy probability, while retaining a lower dynamics error than an offline world model baseline. Using synthetic experience from policy-guided diffusion as a drop-in substitute for real data, we demonstrate significant improvements in performance across a range of standard offline reinforcement learning algorithms and environments. Our approach provides an effective alternative to autoregressive offline world models, opening the door to the controllable generation of synthetic training data.
4/10/2024

Dreamguider: Improved Training free Diffusion-based Conditional Generation
Nithin Gopalakrishnan Nair, Vishal M Patel
0
0
Diffusion models have emerged as a formidable tool for training-free conditional generation.However, a key hurdle in inference-time guidance techniques is the need for compute-heavy backpropagation through the diffusion network for estimating the guidance direction. Moreover, these techniques often require handcrafted parameter tuning on a case-by-case basis. Although some recent works have introduced minimal compute methods for linear inverse problems, a generic lightweight guidance solution to both linear and non-linear guidance problems is still missing. To this end, we propose Dreamguider, a method that enables inference-time guidance without compute-heavy backpropagation through the diffusion network. The key idea is to regulate the gradient flow through a time-varying factor. Moreover, we propose an empirical guidance scale that works for a wide variety of tasks, hence removing the need for handcrafted parameter tuning. We further introduce an effective lightweight augmentation strategy that significantly boosts the performance during inference-time guidance. We present experiments using Dreamguider on multiple tasks across multiple datasets and models to show the effectiveness of the proposed modules. To facilitate further research, we will make the code public after the review process.
6/5/2024