DiffATR: Diffusion-based Generative Modeling for Audio-Text Retrieval

0

Sign in to get full access
Overview
- The paper proposes a diffusion-based generative model called DiffATR for audio-text retrieval.
- DiffATR uses a diffusion process to generate text from audio, enabling cross-modal retrieval.
- The model outperforms existing approaches on benchmark datasets for audio-text retrieval.
Plain English Explanation
DiffATR: Diffusion-based Generative Modeling for Audio-Text Retrieval is a new model that can connect audio and text data. It uses a technique called "diffusion" to generate text from audio information.
Typically, audio-text retrieval models try to find the best match between an audio clip and a piece of text. DiffATR flips this around - instead of matching, it can generate relevant text from an audio input. This allows for more flexible and powerful cross-modal search and generation capabilities.
The key insight is that the diffusion process, which slowly adds noise to data and then tries to remove that noise, can be used to generate text that corresponds to audio. By training the model to do this diffusion process, it learns to translate between the audio and text domains.
This diffusion-based approach outperforms other methods for audio-text retrieval on standard benchmarks. It shows the potential of generative modeling techniques like diffusion for connecting different modalities of data in useful ways.
Technical Explanation
DiffATR is a novel diffusion-based generative model for audio-text retrieval. Diffusion models work by starting with random noise and gradually transforming it into a desired output, like text, through a number of denoising steps.
The key innovation of DiffATR is applying this diffusion process to generate text from audio inputs. The model first encodes the audio into a latent representation. It then uses a diffusion process to gradually transform this latent representation into a textual output.
During training, the model learns to undo the diffusion process, transforming noise back into text that corresponds to the input audio. This allows the model to effectively translate between the audio and text domains.
Experiments on benchmark datasets for audio-text retrieval show that DiffATR outperforms existing transformer-based hierarchical alignment models and other approaches. The diffusion-based generative modeling enables more flexible and powerful cross-modal capabilities compared to previous retrieval-focused methods.
Critical Analysis
The paper demonstrates the effectiveness of diffusion-based generative modeling for audio-text retrieval, but there are a few potential limitations and areas for further research:
-
Dataset Bias: The experiments are conducted on popular but potentially biased datasets like VATEX and AudioCaps. Further testing on more diverse datasets would help validate the model's generalization.
-
Computational Complexity: Diffusion models can be computationally intensive, especially for real-time applications. The authors do not provide detailed analysis of the model's efficiency and scalability.
-
Interpretability: As with many deep learning models, the inner workings of DiffATR may be difficult to interpret. Exploring ways to make the model more transparent could improve trust and understanding.
-
Multimodal Alignment: The paper focuses on audio-to-text translation, but extending the diffusion process to jointly model audio and text representations could lead to even stronger multimodal alignment.
Overall, the DiffATR model demonstrates the potential of diffusion-based techniques for connecting diverse data modalities. Further research addressing the limitations could lead to even more powerful and versatile multimodal systems.
Conclusion
The DiffATR paper introduces a novel diffusion-based generative model for audio-text retrieval. By using a diffusion process to translate between audio and text representations, the model achieves state-of-the-art performance on benchmark datasets.
This work shows the promise of generative modeling approaches, like diffusion, for bridging the gap between different data modalities. By going beyond simple retrieval to enable generation and translation, DiffATR opens up new possibilities for flexible and powerful multimodal applications.
While the paper has some limitations, the core ideas demonstrate an exciting direction for audio-text research. Continued advancements in diffusion-based multimodal modeling could lead to transformative technologies that seamlessly connect our world of audio and language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DiffATR: Diffusion-based Generative Modeling for Audio-Text Retrieval
Yifei Xin, Xuxin Cheng, Zhihong Zhu, Xusheng Yang, Yuexian Zou
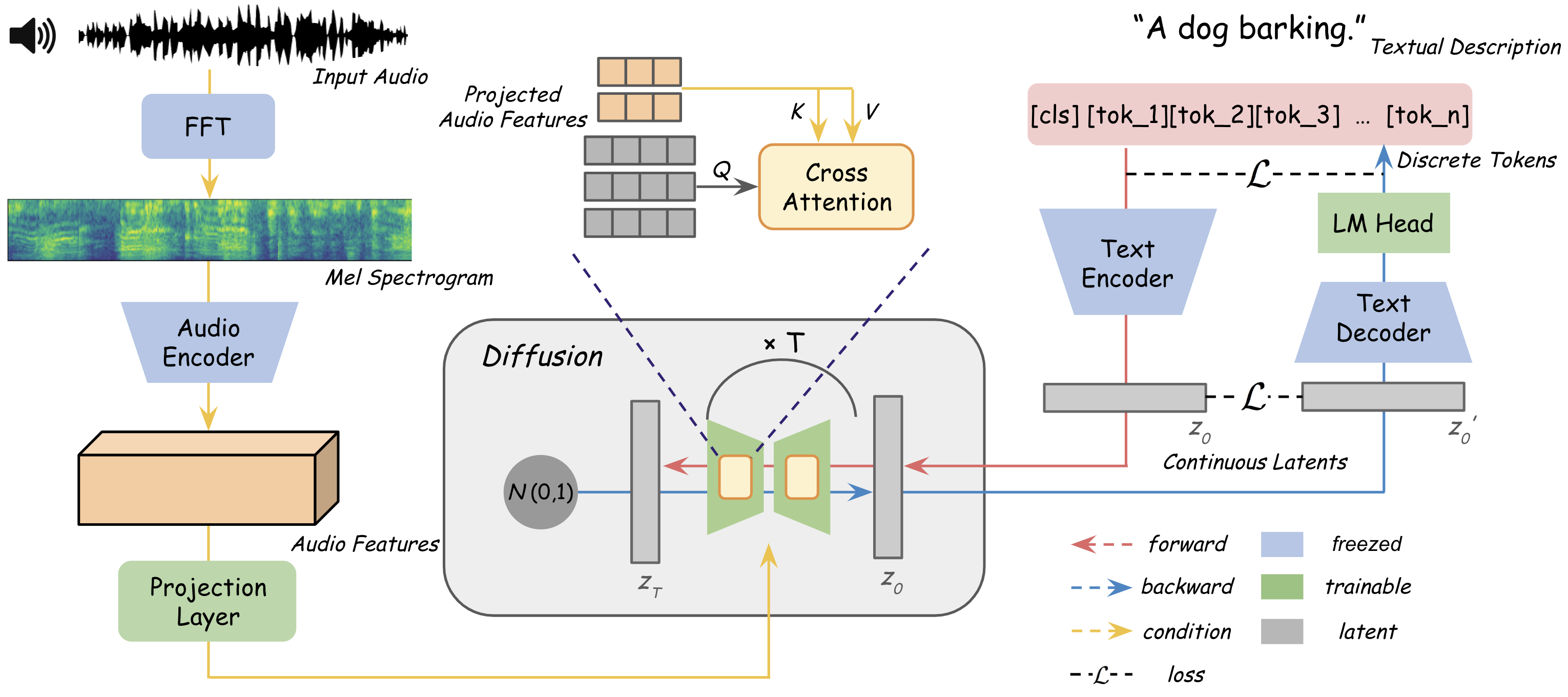
Existing audio-text retrieval (ATR) methods are essentially discriminative models that aim to maximize the conditional likelihood, represented as p(candidates|query). Nevertheless, this methodology fails to consider the intrinsic data distribution p(query), leading to difficulties in discerning out-of-distribution data. In this work, we attempt to tackle this constraint through a generative perspective and model the relationship between audio and text as their joint probability p(candidates,query). To this end, we present a diffusion-based ATR framework (DiffATR), which models ATR as an iterative procedure that progressively generates joint distribution from noise. Throughout its training phase, DiffATR is optimized from both generative and discriminative viewpoints: the generator is refined through a generation loss, while the feature extractor benefits from a contrastive loss, thus combining the merits of both methodologies. Experiments on the AudioCaps and Clotho datasets with superior performances, verify the effectiveness of our approach. Notably, without any alterations, our DiffATR consistently exhibits strong performance in out-of-domain retrieval settings.
Read more9/17/2024

0
Audio-text Retrieval with Transformer-based Hierarchical Alignment and Disentangled Cross-modal Representation
Yifei Xin, Zhihong Zhu, Xuxin Cheng, Xusheng Yang, Yuexian Zou
Most existing audio-text retrieval (ATR) approaches typically rely on a single-level interaction to associate audio and text, limiting their ability to align different modalities and leading to suboptimal matches. In this work, we present a novel ATR framework that leverages two-stream Transformers in conjunction with a Hierarchical Alignment (THA) module to identify multi-level correspondences of different Transformer blocks between audio and text. Moreover, current ATR methods mainly focus on learning a global-level representation, missing out on intricate details to capture audio occurrences that correspond to textual semantics. To bridge this gap, we introduce a Disentangled Cross-modal Representation (DCR) approach that disentangles high-dimensional features into compact latent factors to grasp fine-grained audio-text semantic correlations. Additionally, we develop a confidence-aware (CA) module to estimate the confidence of each latent factor pair and adaptively aggregate cross-modal latent factors to achieve local semantic alignment. Experiments show that our THA effectively boosts ATR performance, with the DCR approach further contributing to consistent performance gains.
Read more9/17/2024
0
Towards Diverse and Efficient Audio Captioning via Diffusion Models
Manjie Xu, Chenxing Li, Xinyi Tu, Yong Ren, Ruibo Fu, Wei Liang, Dong Yu
We introduce Diffusion-based Audio Captioning (DAC), a non-autoregressive diffusion model tailored for diverse and efficient audio captioning. Although existing captioning models relying on language backbones have achieved remarkable success in various captioning tasks, their insufficient performance in terms of generation speed and diversity impede progress in audio understanding and multimedia applications. Our diffusion-based framework offers unique advantages stemming from its inherent stochasticity and holistic context modeling in captioning. Through rigorous evaluation, we demonstrate that DAC not only achieves SOTA performance levels compared to existing benchmarks in the caption quality, but also significantly outperforms them in terms of generation speed and diversity. The success of DAC illustrates that text generation can also be seamlessly integrated with audio and visual generation tasks using a diffusion backbone, paving the way for a unified, audio-related generative model across different modalities.
Read more9/17/2024

0
Autoregressive Diffusion Transformer for Text-to-Speech Synthesis
Zhijun Liu, Shuai Wang, Sho Inoue, Qibing Bai, Haizhou Li
Audio language models have recently emerged as a promising approach for various audio generation tasks, relying on audio tokenizers to encode waveforms into sequences of discrete symbols. Audio tokenization often poses a necessary compromise between code bitrate and reconstruction accuracy. When dealing with low-bitrate audio codes, language models are constrained to process only a subset of the information embedded in the audio, which in turn restricts their generative capabilities. To circumvent these issues, we propose encoding audio as vector sequences in continuous space $mathbb R^d$ and autoregressively generating these sequences using a decoder-only diffusion transformer (ARDiT). Our findings indicate that ARDiT excels in zero-shot text-to-speech and exhibits performance that compares to or even surpasses that of state-of-the-art models. High-bitrate continuous speech representation enables almost flawless reconstruction, allowing our model to achieve nearly perfect speech editing. Our experiments reveal that employing Integral Kullback-Leibler (IKL) divergence for distillation at each autoregressive step significantly boosts the perceived quality of the samples. Simultaneously, it condenses the iterative sampling process of the diffusion model into a single step. Furthermore, ARDiT can be trained to predict several continuous vectors in one step, significantly reducing latency during sampling. Impressively, one of our models can generate $170$ ms of $24$ kHz speech per evaluation step with minimal degradation in performance. Audio samples are available at http://ardit-tts.github.io/ .
Read more6/11/2024