Towards Diverse and Efficient Audio Captioning via Diffusion Models

0
Sign in to get full access
Overview
- This paper presents a novel approach to audio captioning using diffusion models, which can generate diverse and efficient captions for audio inputs.
- The proposed method aims to address the limitations of existing audio captioning models, which often struggle with generating diverse and engaging captions.
- The key contributions of this work include the development of a diffusion-based audio captioning model and various techniques to improve its performance and diversity.
Plain English Explanation
The paper introduces a new way to automatically generate text descriptions, or captions, for audio recordings. The authors use a type of machine learning model called a "diffusion model" to create these captions. Diffusion models work by gradually adding noise to an image or audio signal, and then learning to reverse that process to generate new, realistic content.
The researchers found that this diffusion-based approach can produce a wider variety of captions for the same audio input, compared to existing audio captioning models. This is important because it allows the system to be more flexible and creative in describing the audio, rather than just producing generic or repetitive captions.
Additionally, the authors experimented with different techniques to make the diffusion-based captioning model more efficient and effective. For example, they explored ways to better align the text captions with the audio content, and to generate captions more quickly and consistently.
Overall, this work represents an innovative application of diffusion models to the problem of audio captioning, with the goal of generating more diverse and useful descriptions of audio recordings. This could have applications in areas like automated media captioning, audio-visual understanding, and assistive technology.
Technical Explanation
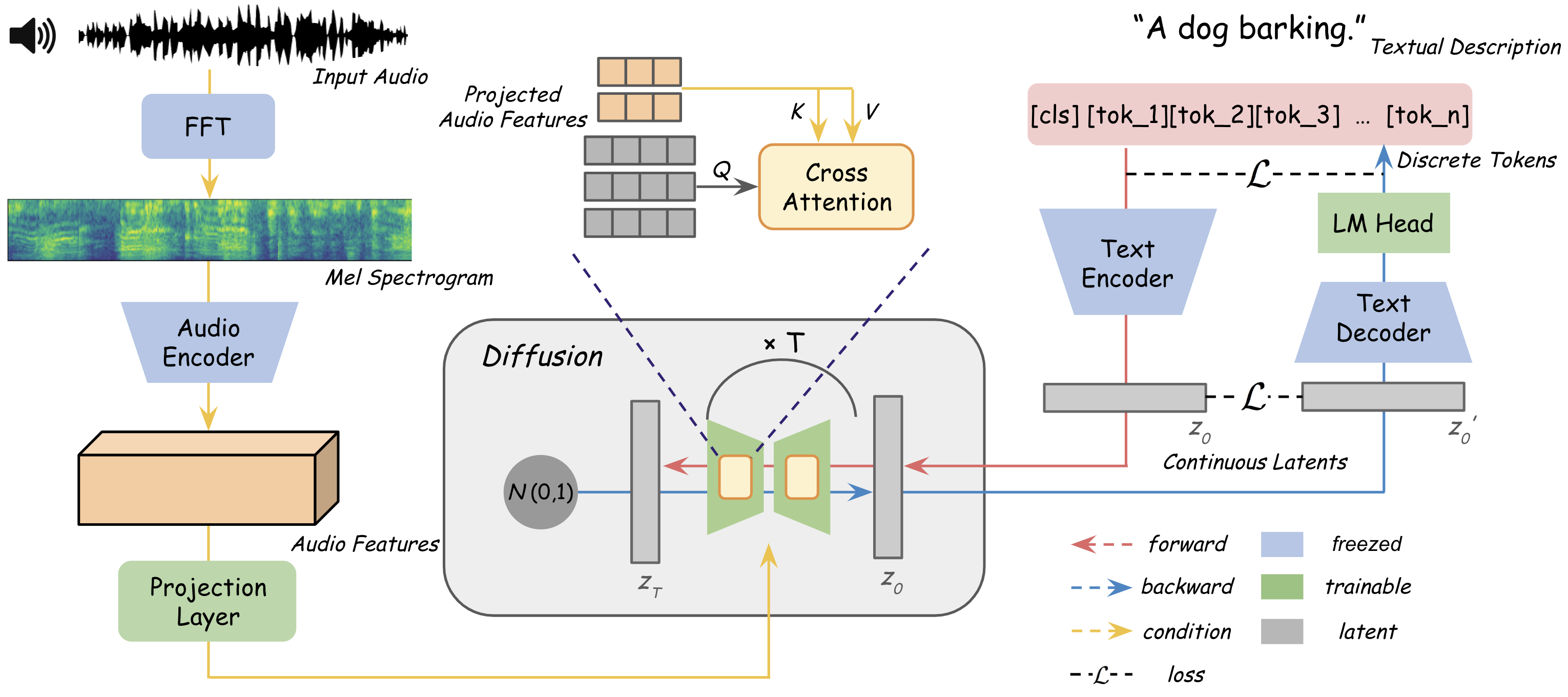
The paper proposes a diffusion-based audio captioning model to address the limitations of existing audio captioning approaches. Diffusion models work by gradually adding noise to an input, and then learning to reverse this noising process to generate new, realistic content.
The authors first train a diffusion model to generate text captions conditioned on audio features extracted from the input audio. They explore various techniques to improve the alignment between the generated captions and the audio, such as consistency-based text-to-audio alignment.
To improve the diversity and efficiency of the captions, the researchers experiment with different sampling strategies during the diffusion process. This includes using adversarial training to encourage the model to generate more varied captions.
The paper presents extensive experiments on benchmark audio captioning datasets, demonstrating that the proposed diffusion-based approach outperforms previous state-of-the-art methods in terms of caption diversity, quality, and efficiency.
Critical Analysis
The paper presents a promising approach to audio captioning, but there are a few potential limitations and areas for further research:
-
The authors focus on improving caption diversity, but do not extensively analyze the accuracy or relevance of the generated captions. More work may be needed to ensure the captions accurately describe the audio content.
-
The proposed methods rely on complex architectural choices and training techniques, which may make the model more difficult to deploy or adapt to new domains. Simpler, more robust models could be an area for further exploration.
-
The paper does not discuss potential biases or ethical considerations that may arise from using diffusion models for audio captioning, such as the propagation of harmful stereotypes or the privacy implications of generating captions for sensitive audio recordings.
Overall, the work represents an innovative application of diffusion models to audio captioning, but more research is needed to fully understand the strengths, limitations, and broader implications of this approach.
Conclusion
This paper presents a novel diffusion-based approach to audio captioning that can generate diverse and efficient captions for audio inputs. The key contributions include the development of a diffusion-based audio captioning model and various techniques to improve its performance and diversity.
The results demonstrate that the proposed method outperforms previous state-of-the-art approaches on benchmark datasets. This work could have important applications in areas like automated media captioning, audio-visual understanding, and assistive technology, by providing more flexible and engaging descriptions of audio content.
However, the paper also highlights the need for further research to address potential limitations, such as ensuring caption accuracy and considering the ethical implications of this technology. Overall, this paper represents an exciting step forward in the field of audio captioning and the application of diffusion models to creative tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Diverse and Efficient Audio Captioning via Diffusion Models
Manjie Xu, Chenxing Li, Xinyi Tu, Yong Ren, Ruibo Fu, Wei Liang, Dong Yu
We introduce Diffusion-based Audio Captioning (DAC), a non-autoregressive diffusion model tailored for diverse and efficient audio captioning. Although existing captioning models relying on language backbones have achieved remarkable success in various captioning tasks, their insufficient performance in terms of generation speed and diversity impede progress in audio understanding and multimedia applications. Our diffusion-based framework offers unique advantages stemming from its inherent stochasticity and holistic context modeling in captioning. Through rigorous evaluation, we demonstrate that DAC not only achieves SOTA performance levels compared to existing benchmarks in the caption quality, but also significantly outperforms them in terms of generation speed and diversity. The success of DAC illustrates that text generation can also be seamlessly integrated with audio and visual generation tasks using a diffusion backbone, paving the way for a unified, audio-related generative model across different modalities.
Read more9/17/2024
🏋️
0
Towards Generating Diverse Audio Captions via Adversarial Training
Xinhao Mei, Xubo Liu, Jianyuan Sun, Mark D. Plumbley, Wenwu Wang
Automated audio captioning is a cross-modal translation task for describing the content of audio clips with natural language sentences. This task has attracted increasing attention and substantial progress has been made in recent years. Captions generated by existing models are generally faithful to the content of audio clips, however, these machine-generated captions are often deterministic (e.g., generating a fixed caption for a given audio clip), simple (e.g., using common words and simple grammar), and generic (e.g., generating the same caption for similar audio clips). When people are asked to describe the content of an audio clip, different people tend to focus on different sound events and describe an audio clip diversely from various aspects using distinct words and grammar. We believe that an audio captioning system should have the ability to generate diverse captions, either for a fixed audio clip, or across similar audio clips. To this end, we propose an adversarial training framework based on a conditional generative adversarial network (C-GAN) to improve diversity of audio captioning systems. A caption generator and two hybrid discriminators compete and are learned jointly, where the caption generator can be any standard encoder-decoder captioning model used to generate captions, and the hybrid discriminators assess the generated captions from different criteria, such as their naturalness and semantics. We conduct experiments on the Clotho dataset. The results show that our proposed model can generate captions with better diversity as compared to state-of-the-art methods.
Read more7/2/2024

0
EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer
Jiarui Hai, Yong Xu, Hao Zhang, Chenxing Li, Helin Wang, Mounya Elhilali, Dong Yu
Latent diffusion models have shown promising results in text-to-audio (T2A) generation tasks, yet previous models have encountered difficulties in generation quality, computational cost, diffusion sampling, and data preparation. In this paper, we introduce EzAudio, a transformer-based T2A diffusion model, to handle these challenges. Our approach includes several key innovations: (1) We build the T2A model on the latent space of a 1D waveform Variational Autoencoder (VAE), avoiding the complexities of handling 2D spectrogram representations and using an additional neural vocoder. (2) We design an optimized diffusion transformer architecture specifically tailored for audio latent representations and diffusion modeling, which enhances convergence speed, training stability, and memory usage, making the training process easier and more efficient. (3) To tackle data scarcity, we adopt a data-efficient training strategy that leverages unlabeled data for learning acoustic dependencies, audio caption data annotated by audio-language models for text-to-audio alignment learning, and human-labeled data for fine-tuning. (4) We introduce a classifier-free guidance (CFG) rescaling method that simplifies EzAudio by achieving strong prompt alignment while preserving great audio quality when using larger CFG scores, eliminating the need to struggle with finding the optimal CFG score to balance this trade-off. EzAudio surpasses existing open-source models in both objective metrics and subjective evaluations, delivering realistic listening experiences while maintaining a streamlined model structure, low training costs, and an easy-to-follow training pipeline. Code, data, and pre-trained models are released at: https://haidog-yaqub.github.io/EzAudio-Page/.
Read more9/18/2024

0
Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
Navonil Majumder, Chia-Yu Hung, Deepanway Ghosal, Wei-Ning Hsu, Rada Mihalcea, Soujanya Poria
Generative multimodal content is increasingly prevalent in much of the content creation arena, as it has the potential to allow artists and media personnel to create pre-production mockups by quickly bringing their ideas to life. The generation of audio from text prompts is an important aspect of such processes in the music and film industry. Many of the recent diffusion-based text-to-audio models focus on training increasingly sophisticated diffusion models on a large set of datasets of prompt-audio pairs. These models do not explicitly focus on the presence of concepts or events and their temporal ordering in the output audio with respect to the input prompt. Our hypothesis is focusing on how these aspects of audio generation could improve audio generation performance in the presence of limited data. As such, in this work, using an existing text-to-audio model Tango, we synthetically create a preference dataset where each prompt has a winner audio output and some loser audio outputs for the diffusion model to learn from. The loser outputs, in theory, have some concepts from the prompt missing or in an incorrect order. We fine-tune the publicly available Tango text-to-audio model using diffusion-DPO (direct preference optimization) loss on our preference dataset and show that it leads to improved audio output over Tango and AudioLDM2, in terms of both automatic- and manual-evaluation metrics.
Read more7/18/2024