DiffuseHigh: Training-free Progressive High-Resolution Image Synthesis through Structure Guidance
2406.18459
0
0

Abstract
Recent surge in large-scale generative models has spurred the development of vast fields in computer vision. In particular, text-to-image diffusion models have garnered widespread adoption across diverse domain due to their potential for high-fidelity image generation. Nonetheless, existing large-scale diffusion models are confined to generate images of up to 1K resolution, which is far from meeting the demands of contemporary commercial applications. Directly sampling higher-resolution images often yields results marred by artifacts such as object repetition and distorted shapes. Addressing the aforementioned issues typically necessitates training or fine-tuning models on higher resolution datasets. However, this undertaking poses a formidable challenge due to the difficulty in collecting large-scale high-resolution contents and substantial computational resources. While several preceding works have proposed alternatives, they often fail to produce convincing results. In this work, we probe the generative ability of diffusion models at higher resolution beyond its original capability and propose a novel progressive approach that fully utilizes generated low-resolution image to guide the generation of higher resolution image. Our method obviates the need for additional training or fine-tuning which significantly lowers the burden of computational costs. Extensive experiments and results validate the efficiency and efficacy of our method.
Create account to get full access
Overview
- The paper "DiffuseHigh: Training-free Progressive High-Resolution Image Synthesis through Structure Guidance" presents a novel approach to generating high-resolution images without the need for extensive training.
- The method, called DiffuseHigh, leverages pre-trained diffusion models and a structure guidance mechanism to enable progressive image synthesis at high resolutions.
- This approach aims to address the challenges of training large-scale diffusion models for high-resolution image generation, which can be computationally intensive and time-consuming.
Plain English Explanation
The paper introduces a new technique called DiffuseHigh that can generate high-quality, high-resolution images without requiring extensive training. Traditional approaches to generating high-resolution images often involve training large and complex machine learning models, which can be a time-consuming and resource-intensive process.
DiffuseHigh takes a different approach by building on pre-trained diffusion models, which are a type of machine learning model that can be used to generate images. The key innovation in DiffuseHigh is the use of a "structure guidance" mechanism, which helps the model to generate images that are coherent and realistic at high resolutions.
The structure guidance mechanism works by providing the model with additional information about the structure and composition of the images it should generate. This helps the model to create images that have a natural and believable appearance, even at high resolutions.
By leveraging pre-trained diffusion models and the structure guidance mechanism, DiffuseHigh can generate high-resolution images without the need for lengthy and expensive training. This makes it a potentially valuable tool for a wide range of applications, from digital art and photography to medical imaging and scientific visualization.
Technical Explanation
The paper presents the DiffuseHigh framework, which builds on the success of diffusion models for image generation. Diffusion models are a type of generative model that can produce high-quality images by learning to reverse a process of gradual noise addition.
To address the challenge of generating high-resolution images, the authors propose a progressive upsampling approach along with a structure guidance mechanism. The structure guidance is designed to help the diffusion model maintain coherent and realistic image structures during the progressive upsampling process.
The DiffuseHigh framework consists of a pre-trained diffusion model and a structure guidance network. The structure guidance network takes in a low-resolution input image and generates a high-resolution guidance map, which is then used to guide the diffusion model's image generation process. This approach aims to unlock higher-resolution creativity and efficiency compared to previous diffusion-based methods.
The authors conduct extensive experiments to demonstrate the effectiveness of DiffuseHigh in generating high-quality, high-resolution images across various datasets. They also compare DiffuseHigh to other state-of-the-art methods for high-resolution image synthesis, showcasing its improved performance and efficiency.
Critical Analysis
The paper presents a promising approach to high-resolution image synthesis, addressing the challenges of training large-scale diffusion models for this task. The authors' use of a pre-trained diffusion model and the structure guidance mechanism is a clever way to leverage existing models and reduce the computational burden of training new ones from scratch.
One potential limitation of the DiffuseHigh approach is that it still requires the training of the structure guidance network, which could be time-consuming and resource-intensive, especially for large-scale datasets or high-resolution target resolutions. The authors mention that further research is needed to explore more efficient ways of generating the guidance maps.
Additionally, the paper does not provide a detailed analysis of the types of artifacts or distortions that may arise in the generated images, particularly at the highest resolutions. It would be valuable for the authors to discuss any such limitations and potential avenues for further improvement.
The paper also does not explore the potential applications or use cases of the DiffuseHigh framework beyond image synthesis. Discussing how this approach could be leveraged in domains such as image-neural-field diffusion models, medical imaging, or scientific visualization could help to broaden the impact and relevance of the research.
Conclusion
The "DiffuseHigh: Training-free Progressive High-Resolution Image Synthesis through Structure Guidance" paper presents a novel approach to generating high-resolution images without the need for extensive training. By combining pre-trained diffusion models with a structure guidance mechanism, the authors have developed a framework that can produce coherent and realistic high-resolution images efficiently.
This work addresses a significant challenge in the field of generative modeling and has the potential to enable a wide range of applications, from digital art and photography to medical imaging and scientific visualization. While the paper identifies areas for further research, the DiffuseHigh framework represents an important step forward in advancing the state-of-the-art in high-resolution image synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
Upsample Guidance: Scale Up Diffusion Models without Training
Juno Hwang, Yong-Hyun Park, Junghyo Jo
0
0
Diffusion models have demonstrated superior performance across various generative tasks including images, videos, and audio. However, they encounter difficulties in directly generating high-resolution samples. Previously proposed solutions to this issue involve modifying the architecture, further training, or partitioning the sampling process into multiple stages. These methods have the limitation of not being able to directly utilize pre-trained models as-is, requiring additional work. In this paper, we introduce upsample guidance, a technique that adapts pretrained diffusion model (e.g., $512^2$) to generate higher-resolution images (e.g., $1536^2$) by adding only a single term in the sampling process. Remarkably, this technique does not necessitate any additional training or relying on external models. We demonstrate that upsample guidance can be applied to various models, such as pixel-space, latent space, and video diffusion models. We also observed that the proper selection of guidance scale can improve image quality, fidelity, and prompt alignment.
4/3/2024

Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
Cristina N. Vasconcelos, Abdullah Rashwan Austin Waters, Trevor Walker, Keyang Xu, Jimmy Yan, Rui Qian, Shixin Luo, Zarana Parekh, Andrew Bunner, Hongliang Fei, Roopal Garg, Mandy Guo, Ivana Kajic, Yeqing Li, Henna Nandwani, Jordi Pont-Tuset, Yasumasa Onoe, Sarah Rosston, Su Wang, Wenlei Zhou, Kevin Swersky, David J. Fleet, Jason M. Baldridge, Oliver Wang
0
0
We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
5/28/2024
↗️
HiDiffusion: Unlocking Higher-Resolution Creativity and Efficiency in Pretrained Diffusion Models
Shen Zhang, Zhaowei Chen, Zhenyu Zhao, Yuhao Chen, Yao Tang, Jiajun Liang
0
0
Diffusion models have become a mainstream approach for high-resolution image synthesis. However, directly generating higher-resolution images from pretrained diffusion models will encounter unreasonable object duplication and exponentially increase the generation time. In this paper, we discover that object duplication arises from feature duplication in the deep blocks of the U-Net. Concurrently, We pinpoint the extended generation times to self-attention redundancy in U-Net's top blocks. To address these issues, we propose a tuning-free higher-resolution framework named HiDiffusion. Specifically, HiDiffusion contains Resolution-Aware U-Net (RAU-Net) that dynamically adjusts the feature map size to resolve object duplication and engages Modified Shifted Window Multi-head Self-Attention (MSW-MSA) that utilizes optimized window attention to reduce computations. we can integrate HiDiffusion into various pretrained diffusion models to scale image generation resolutions even to 4096x4096 at 1.5-6x the inference speed of previous methods. Extensive experiments demonstrate that our approach can address object duplication and heavy computation issues, achieving state-of-the-art performance on higher-resolution image synthesis tasks.
4/30/2024
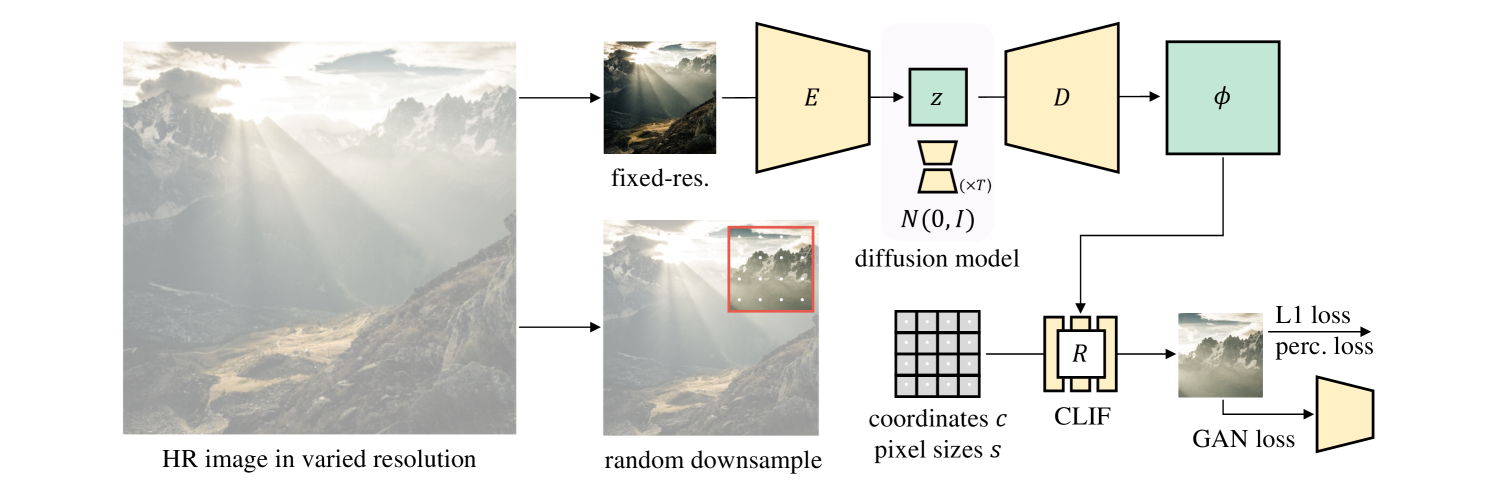
Image Neural Field Diffusion Models
Yinbo Chen, Oliver Wang, Richard Zhang, Eli Shechtman, Xiaolong Wang, Michael Gharbi
0
0
Diffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently.
6/12/2024