HiDiffusion: Unlocking Higher-Resolution Creativity and Efficiency in Pretrained Diffusion Models
2311.17528
0
0
↗️
Abstract
Diffusion models have become a mainstream approach for high-resolution image synthesis. However, directly generating higher-resolution images from pretrained diffusion models will encounter unreasonable object duplication and exponentially increase the generation time. In this paper, we discover that object duplication arises from feature duplication in the deep blocks of the U-Net. Concurrently, We pinpoint the extended generation times to self-attention redundancy in U-Net's top blocks. To address these issues, we propose a tuning-free higher-resolution framework named HiDiffusion. Specifically, HiDiffusion contains Resolution-Aware U-Net (RAU-Net) that dynamically adjusts the feature map size to resolve object duplication and engages Modified Shifted Window Multi-head Self-Attention (MSW-MSA) that utilizes optimized window attention to reduce computations. we can integrate HiDiffusion into various pretrained diffusion models to scale image generation resolutions even to 4096x4096 at 1.5-6x the inference speed of previous methods. Extensive experiments demonstrate that our approach can address object duplication and heavy computation issues, achieving state-of-the-art performance on higher-resolution image synthesis tasks.
Create account to get full access
Overview
- Diffusion models have become a popular approach for generating high-resolution images, but directly scaling them up can lead to issues like object duplication and longer generation times.
- This paper proposes a framework called HiDiffusion that addresses these problems by dynamically adjusting the feature map size and using an optimized self-attention mechanism.
- HiDiffusion can be integrated with various pre-trained diffusion models to generate images up to 4096x4096 resolution, with faster inference speeds than previous methods.
Plain English Explanation
Diffusion models are a powerful technique for generating high-quality, high-resolution images. However, when you try to directly scale up the resolution of images produced by these models, two issues can arise:
- Object Duplication: The images may start to have duplicate or repeated objects, which looks unnatural.
- Slow Generation: The time it takes to generate the higher-resolution images can increase exponentially.
The researchers discovered that the object duplication problem comes from the way the diffusion model is processing the image features at different layers. And the longer generation times are due to inefficiencies in how the model is using self-attention, a key component for capturing long-range dependencies.
To address these problems, the researchers developed a new framework called HiDiffusion. HiDiffusion contains two key innovations:
- Resolution-Aware U-Net (RAU-Net): This dynamically adjusts the size of the feature maps in the diffusion model to prevent the object duplication issue.
- Modified Shifted Window Multi-head Self-Attention (MSW-MSA): This uses an optimized self-attention mechanism to reduce the computational burden and speed up generation.
By incorporating HiDiffusion, the researchers were able to take pre-trained diffusion models and scale the image resolution up to an impressive 4096x4096, while also making the generation process 1.5-6x faster than previous methods. This represents a significant advancement in the capabilities of diffusion models for high-resolution image synthesis.
Technical Explanation
The core challenges addressed in this paper are the object duplication and excessive computation issues that arise when scaling up the resolution of images generated by diffusion models.
The researchers first identify the root causes of these problems. They discover that the object duplication stems from feature duplication in the deep layers of the U-Net architecture, which is commonly used in diffusion models. The long generation times, on the other hand, are attributed to redundant self-attention computations in the top blocks of the U-Net.
To mitigate these issues, the authors propose the HiDiffusion framework, which contains two key innovations:
-
Resolution-Aware U-Net (RAU-Net): This modified U-Net architecture dynamically adjusts the feature map size to prevent object duplication. By keeping the feature map resolution aligned with the target output resolution, RAU-Net is able to generate higher-quality, higher-resolution images.
-
Modified Shifted Window Multi-head Self-Attention (MSW-MSA): This optimized self-attention mechanism reduces the computational burden of the diffusion model. By restricting the self-attention computations to local windows and using a shifted window approach, MSW-MSA can significantly speed up the generation process without sacrificing performance.
The researchers integrate HiDiffusion into various pre-trained diffusion models, enabling them to scale up the image resolution to an impressive 4096x4096. Extensive experiments show that HiDiffusion can address both the object duplication and heavy computation issues, achieving state-of-the-art performance on high-resolution image synthesis tasks.
Critical Analysis
The paper presents a well-designed and thorough solution to the challenges of scaling up diffusion models for high-resolution image generation. The core ideas behind the RAU-Net and MSW-MSA components are technically sound and the experimental results demonstrate the effectiveness of the HiDiffusion framework.
One potential limitation of the work is that it focuses solely on image synthesis, and the proposed techniques may not generalize as well to other diffusion model applications, such as text-to-image generation or medical image super-resolution. Additionally, the paper does not explore the memory and storage requirements of the higher-resolution outputs, which could be a practical concern for real-world deployment.
Another area for further research could be exploring the tradeoffs between generation speed, image quality, and computational efficiency. The paper demonstrates significant improvements in generation speed, but it would be interesting to see how these optimizations impact other performance metrics, such as perceptual quality or feature-level consistency.
Overall, the HiDiffusion framework represents an important step forward in the development of high-resolution diffusion models, and the technical insights provided in this paper could inspire further innovations in this rapidly evolving field.
Conclusion
This paper introduces the HiDiffusion framework, which addresses two critical challenges in scaling up diffusion models for high-resolution image synthesis: object duplication and excessive computational requirements. By proposing the RAU-Net architecture and the MSW-MSA self-attention mechanism, the researchers were able to integrate HiDiffusion with various pre-trained diffusion models and generate images up to 4096x4096 resolution, with significantly faster inference speeds than previous methods.
The successful development and evaluation of HiDiffusion demonstrates the potential of diffusion models to produce remarkably high-quality, high-resolution images, with important implications for a wide range of applications, from creative content generation to scientific visualization. As the field of diffusion modeling continues to evolve, the insights and techniques presented in this paper will likely inspire further advancements in the quest for ever-more-powerful and efficient image synthesis capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DiffuseHigh: Training-free Progressive High-Resolution Image Synthesis through Structure Guidance
Younghyun Kim, Geunmin Hwang, Eunbyung Park
0
0
Recent surge in large-scale generative models has spurred the development of vast fields in computer vision. In particular, text-to-image diffusion models have garnered widespread adoption across diverse domain due to their potential for high-fidelity image generation. Nonetheless, existing large-scale diffusion models are confined to generate images of up to 1K resolution, which is far from meeting the demands of contemporary commercial applications. Directly sampling higher-resolution images often yields results marred by artifacts such as object repetition and distorted shapes. Addressing the aforementioned issues typically necessitates training or fine-tuning models on higher resolution datasets. However, this undertaking poses a formidable challenge due to the difficulty in collecting large-scale high-resolution contents and substantial computational resources. While several preceding works have proposed alternatives, they often fail to produce convincing results. In this work, we probe the generative ability of diffusion models at higher resolution beyond its original capability and propose a novel progressive approach that fully utilizes generated low-resolution image to guide the generation of higher resolution image. Our method obviates the need for additional training or fine-tuning which significantly lowers the burden of computational costs. Extensive experiments and results validate the efficiency and efficacy of our method.
6/27/2024
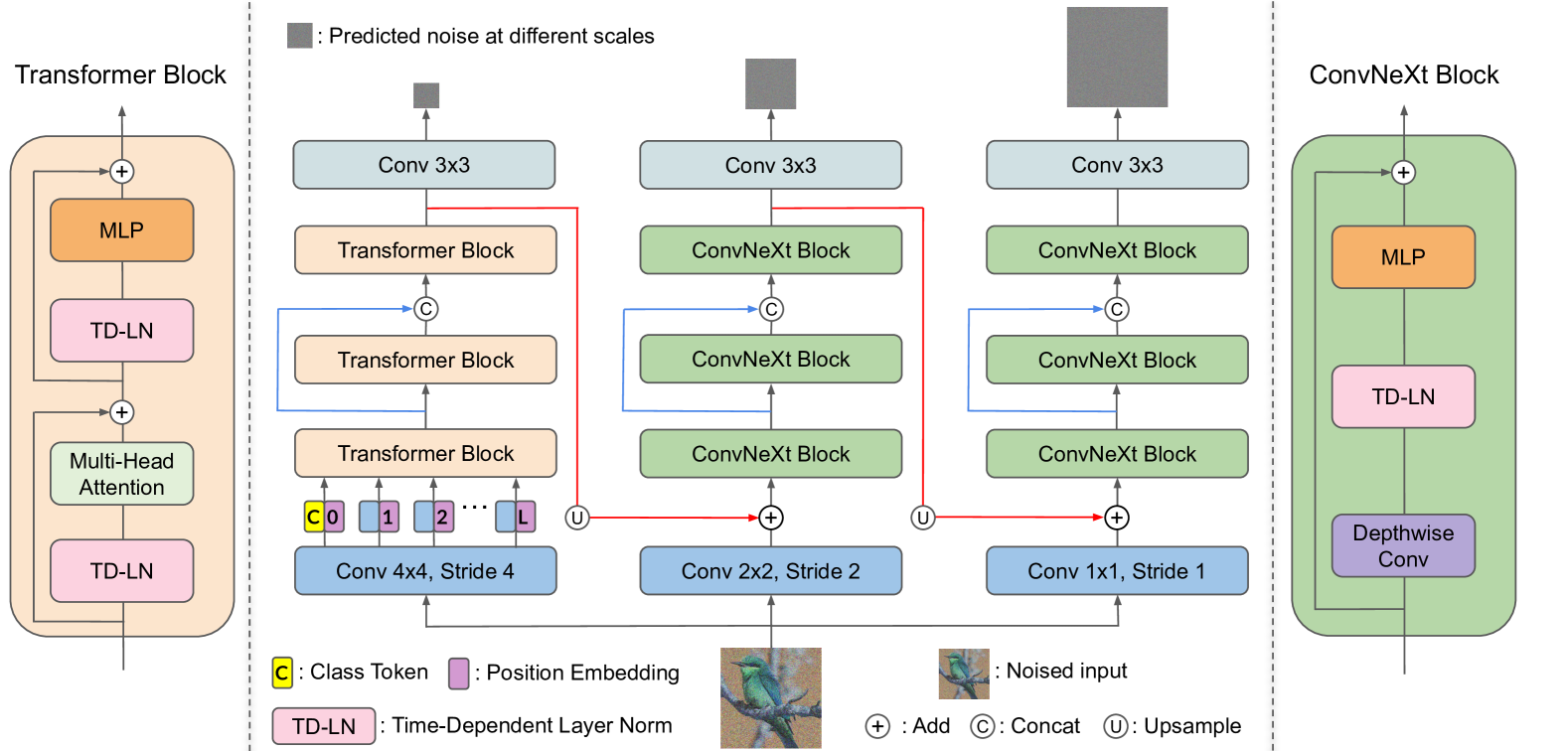
Alleviating Distortion in Image Generation via Multi-Resolution Diffusion Models
Qihao Liu, Zhanpeng Zeng, Ju He, Qihang Yu, Xiaohui Shen, Liang-Chieh Chen
0
0
This paper presents innovative enhancements to diffusion models by integrating a novel multi-resolution network and time-dependent layer normalization. Diffusion models have gained prominence for their effectiveness in high-fidelity image generation. While conventional approaches rely on convolutional U-Net architectures, recent Transformer-based designs have demonstrated superior performance and scalability. However, Transformer architectures, which tokenize input data (via patchification), face a trade-off between visual fidelity and computational complexity due to the quadratic nature of self-attention operations concerning token length. While larger patch sizes enable attention computation efficiency, they struggle to capture fine-grained visual details, leading to image distortions. To address this challenge, we propose augmenting the Diffusion model with the Multi-Resolution network (DiMR), a framework that refines features across multiple resolutions, progressively enhancing detail from low to high resolution. Additionally, we introduce Time-Dependent Layer Normalization (TD-LN), a parameter-efficient approach that incorporates time-dependent parameters into layer normalization to inject time information and achieve superior performance. Our method's efficacy is demonstrated on the class-conditional ImageNet generation benchmark, where DiMR-XL variants outperform prior diffusion models, setting new state-of-the-art FID scores of 1.70 on ImageNet 256 x 256 and 2.89 on ImageNet 512 x 512. Project page: https://qihao067.github.io/projects/DiMR
6/14/2024
🖼️
Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer
Zhuoyi Yang, Heyang Jiang, Wenyi Hong, Jiayan Teng, Wendi Zheng, Yuxiao Dong, Ming Ding, Jie Tang
0
0
Diffusion models have shown remarkable performance in image generation in recent years. However, due to a quadratic increase in memory during generating ultra-high-resolution images (e.g. 4096*4096), the resolution of generated images is often limited to 1024*1024. In this work. we propose a unidirectional block attention mechanism that can adaptively adjust the memory overhead during the inference process and handle global dependencies. Building on this module, we adopt the DiT structure for upsampling and develop an infinite super-resolution model capable of upsampling images of various shapes and resolutions. Comprehensive experiments show that our model achieves SOTA performance in generating ultra-high-resolution images in both machine and human evaluation. Compared to commonly used UNet structures, our model can save more than 5x memory when generating 4096*4096 images. The project URL is https://github.com/THUDM/Inf-DiT.
5/9/2024
🏋️
Upsample Guidance: Scale Up Diffusion Models without Training
Juno Hwang, Yong-Hyun Park, Junghyo Jo
0
0
Diffusion models have demonstrated superior performance across various generative tasks including images, videos, and audio. However, they encounter difficulties in directly generating high-resolution samples. Previously proposed solutions to this issue involve modifying the architecture, further training, or partitioning the sampling process into multiple stages. These methods have the limitation of not being able to directly utilize pre-trained models as-is, requiring additional work. In this paper, we introduce upsample guidance, a technique that adapts pretrained diffusion model (e.g., $512^2$) to generate higher-resolution images (e.g., $1536^2$) by adding only a single term in the sampling process. Remarkably, this technique does not necessitate any additional training or relying on external models. We demonstrate that upsample guidance can be applied to various models, such as pixel-space, latent space, and video diffusion models. We also observed that the proper selection of guidance scale can improve image quality, fidelity, and prompt alignment.
4/3/2024