Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
2405.16759
0
0

Abstract
We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
Create account to get full access
Overview
- Presents a novel diffusion model architecture called "Greedy Growing" that enables high-resolution pixel-based image generation
- Achieves state-of-the-art performance on several high-resolution image datasets while being more computationally efficient than previous approaches
- Introduces a technique called "Greedy Growing" that allows the model to progressively grow in resolution and complexity during training
Plain English Explanation
The paper describes a new way to train diffusion models, which are a type of machine learning model used to generate images. Diffusion models work by gradually adding "noise" to an image, then learning to reverse that process to create new images.
The key innovation in this paper is a technique called "Greedy Growing." <a href="https://aimodels.fyi/papers/arxiv/upsample-guidance-scale-up-diffusion-models-without">Rather than training the model on a single fixed-resolution image</a>, the researchers start with a low-resolution image and gradually increase the resolution during training. This allows the model to learn how to generate high-quality images more efficiently.
The researchers show that their Greedy Growing approach outperforms previous state-of-the-art diffusion models on several challenging high-resolution image datasets. Their method is also more computationally efficient, meaning it can be trained and run more quickly than other techniques. This could make it easier to use diffusion models to create high-quality images at scale.
Technical Explanation
The researchers propose a novel diffusion model architecture called "Greedy Growing" that enables high-resolution pixel-based image generation. <a href="https://aimodels.fyi/papers/arxiv/scalability-diffusion-based-text-to-image-generation">Unlike previous diffusion models that operate on a fixed resolution</a>, their approach starts with a low-resolution image and progressively grows the resolution and complexity of the model during training.
This "Greedy Growing" technique involves gradually increasing the number of model layers and feature channels as the resolution increases. The model is trained to generate high-quality images at each resolution, with the lower-resolution versions serving as a starting point for the higher-resolution outputs.
Experiments on several high-resolution image datasets, including ImageNet-HQ, CelebA-HQ, and LSUN, show that the Greedy Growing model outperforms previous state-of-the-art diffusion models in terms of image quality and computational efficiency. <a href="https://aimodels.fyi/papers/arxiv/hidiffusion-unlocking-higher-resolution-creativity-efficiency-pretrained">The authors attribute this to the progressive training approach, which allows the model to learn a strong foundation at lower resolutions before scaling up.</a>
Critical Analysis
The paper presents a compelling and well-designed approach to enable high-resolution pixel-based image generation using diffusion models. The "Greedy Growing" technique is a novel and effective solution to the scalability challenges that have limited the use of diffusion models for high-resolution image synthesis in the past.
<a href="https://aimodels.fyi/papers/arxiv/generative-powers-ten">While the results demonstrate significant improvements over previous methods, the authors acknowledge that their approach is still limited in the maximum resolution it can achieve compared to some alternative techniques like GANs.</a> Further research may be needed to push the boundaries of what is possible with diffusion-based image generation.
Additionally, the paper does not delve into potential biases or fairness issues that could arise from the training data or model architecture. As with any powerful generative model, there are valid concerns about the responsible development and deployment of such technology.
Overall, this research represents an important step forward in the field of high-resolution image synthesis and highlights the potential of diffusion models to serve as a versatile and powerful tool for creative and industrial applications. <a href="https://aimodels.fyi/papers/arxiv/patchscaler-efficient-patch-independent-diffusion-model-super">Further advancements in this area could unlock new possibilities for generating high-quality, diverse, and scalable visual content.</a>
Conclusion
The "Greedy Growing" diffusion model architecture presented in this paper demonstrates a novel and effective approach to enabling high-resolution pixel-based image generation. By progressively growing the model's complexity and resolution during training, the researchers were able to achieve state-of-the-art performance on several challenging image datasets while maintaining computational efficiency.
This work represents an important advancement in the field of diffusion-based generative modeling, which has the potential to revolutionize creative and industrial applications that require the synthesis of high-quality, diverse visual content. As the technology continues to evolve, it will be crucial to address potential issues around bias, fairness, and responsible development to ensure these powerful tools are used in service of the greater good.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DiffuseHigh: Training-free Progressive High-Resolution Image Synthesis through Structure Guidance
Younghyun Kim, Geunmin Hwang, Eunbyung Park
0
0
Recent surge in large-scale generative models has spurred the development of vast fields in computer vision. In particular, text-to-image diffusion models have garnered widespread adoption across diverse domain due to their potential for high-fidelity image generation. Nonetheless, existing large-scale diffusion models are confined to generate images of up to 1K resolution, which is far from meeting the demands of contemporary commercial applications. Directly sampling higher-resolution images often yields results marred by artifacts such as object repetition and distorted shapes. Addressing the aforementioned issues typically necessitates training or fine-tuning models on higher resolution datasets. However, this undertaking poses a formidable challenge due to the difficulty in collecting large-scale high-resolution contents and substantial computational resources. While several preceding works have proposed alternatives, they often fail to produce convincing results. In this work, we probe the generative ability of diffusion models at higher resolution beyond its original capability and propose a novel progressive approach that fully utilizes generated low-resolution image to guide the generation of higher resolution image. Our method obviates the need for additional training or fine-tuning which significantly lowers the burden of computational costs. Extensive experiments and results validate the efficiency and efficacy of our method.
6/27/2024
🏋️
Upsample Guidance: Scale Up Diffusion Models without Training
Juno Hwang, Yong-Hyun Park, Junghyo Jo
0
0
Diffusion models have demonstrated superior performance across various generative tasks including images, videos, and audio. However, they encounter difficulties in directly generating high-resolution samples. Previously proposed solutions to this issue involve modifying the architecture, further training, or partitioning the sampling process into multiple stages. These methods have the limitation of not being able to directly utilize pre-trained models as-is, requiring additional work. In this paper, we introduce upsample guidance, a technique that adapts pretrained diffusion model (e.g., $512^2$) to generate higher-resolution images (e.g., $1536^2$) by adding only a single term in the sampling process. Remarkably, this technique does not necessitate any additional training or relying on external models. We demonstrate that upsample guidance can be applied to various models, such as pixel-space, latent space, and video diffusion models. We also observed that the proper selection of guidance scale can improve image quality, fidelity, and prompt alignment.
4/3/2024
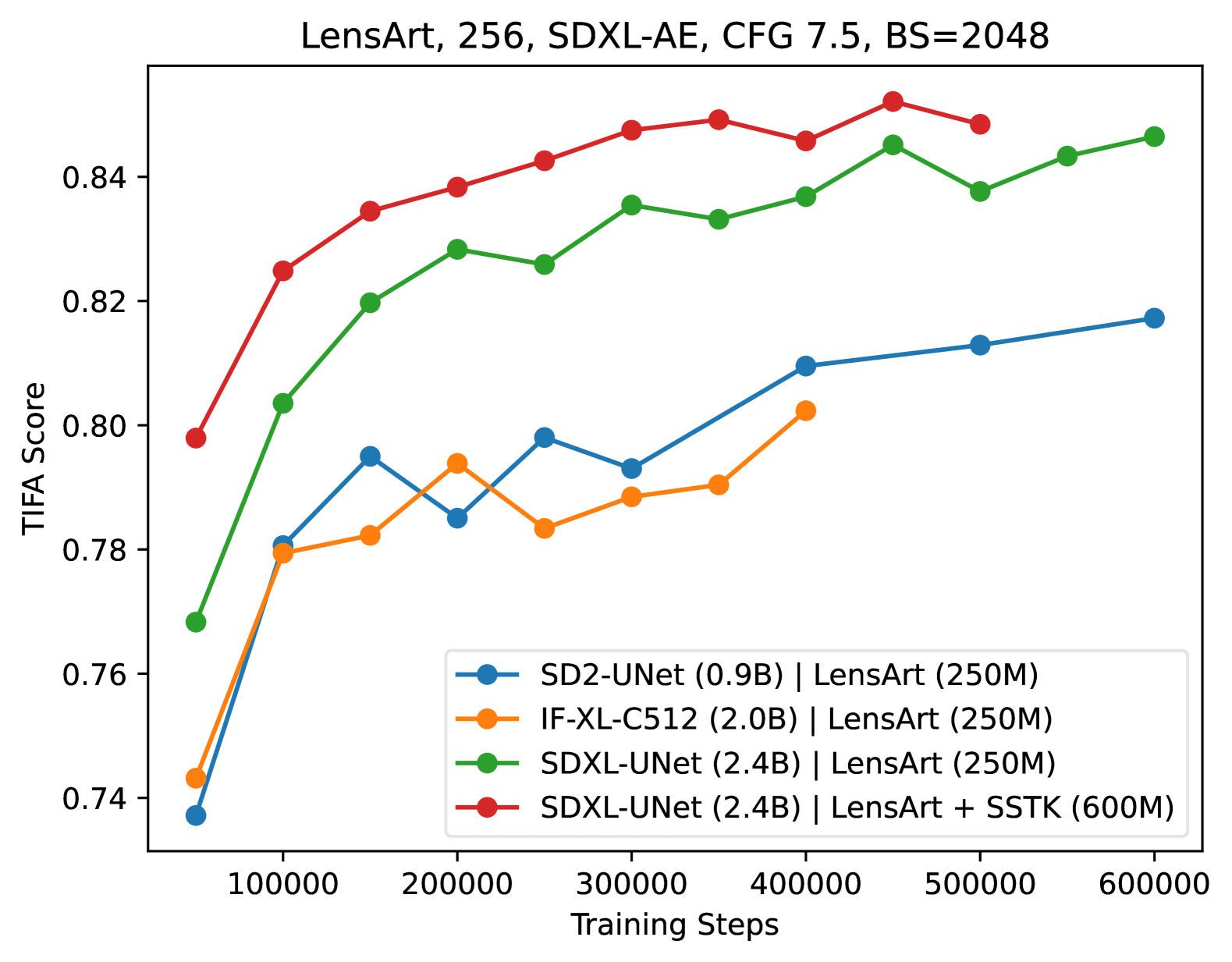
On the Scalability of Diffusion-based Text-to-Image Generation
Hao Li, Yang Zou, Ying Wang, Orchid Majumder, Yusheng Xie, R. Manmatha, Ashwin Swaminathan, Zhuowen Tu, Stefano Ermon, Stefano Soatto
0
0
Scaling up model and data size has been quite successful for the evolution of LLMs. However, the scaling law for the diffusion based text-to-image (T2I) models is not fully explored. It is also unclear how to efficiently scale the model for better performance at reduced cost. The different training settings and expensive training cost make a fair model comparison extremely difficult. In this work, we empirically study the scaling properties of diffusion based T2I models by performing extensive and rigours ablations on scaling both denoising backbones and training set, including training scaled UNet and Transformer variants ranging from 0.4B to 4B parameters on datasets upto 600M images. For model scaling, we find the location and amount of cross attention distinguishes the performance of existing UNet designs. And increasing the transformer blocks is more parameter-efficient for improving text-image alignment than increasing channel numbers. We then identify an efficient UNet variant, which is 45% smaller and 28% faster than SDXL's UNet. On the data scaling side, we show the quality and diversity of the training set matters more than simply dataset size. Increasing caption density and diversity improves text-image alignment performance and the learning efficiency. Finally, we provide scaling functions to predict the text-image alignment performance as functions of the scale of model size, compute and dataset size.
4/4/2024
↗️
HiDiffusion: Unlocking Higher-Resolution Creativity and Efficiency in Pretrained Diffusion Models
Shen Zhang, Zhaowei Chen, Zhenyu Zhao, Yuhao Chen, Yao Tang, Jiajun Liang
0
0
Diffusion models have become a mainstream approach for high-resolution image synthesis. However, directly generating higher-resolution images from pretrained diffusion models will encounter unreasonable object duplication and exponentially increase the generation time. In this paper, we discover that object duplication arises from feature duplication in the deep blocks of the U-Net. Concurrently, We pinpoint the extended generation times to self-attention redundancy in U-Net's top blocks. To address these issues, we propose a tuning-free higher-resolution framework named HiDiffusion. Specifically, HiDiffusion contains Resolution-Aware U-Net (RAU-Net) that dynamically adjusts the feature map size to resolve object duplication and engages Modified Shifted Window Multi-head Self-Attention (MSW-MSA) that utilizes optimized window attention to reduce computations. we can integrate HiDiffusion into various pretrained diffusion models to scale image generation resolutions even to 4096x4096 at 1.5-6x the inference speed of previous methods. Extensive experiments demonstrate that our approach can address object duplication and heavy computation issues, achieving state-of-the-art performance on higher-resolution image synthesis tasks.
4/30/2024