Diffusion-based Generative Modeling with Discriminative Guidance for Streamable Speech Enhancement

0

Sign in to get full access
Overview
- This paper introduces a new approach for speech enhancement using diffusion-based generative modeling with discriminative guidance.
- The proposed model leverages the strengths of diffusion models to generate high-quality enhanced speech, while using a discriminative model to provide guidance and improve performance.
- The model is designed to be streamable, allowing for real-time processing of audio signals.
Plain English Explanation
The researchers have developed a new way to improve the quality of speech recordings, such as removing background noise or enhancing the clarity of the speaker's voice. They use a type of machine learning model called a "diffusion model" to generate the enhanced speech. Diffusion models work by starting with random noise and gradually transforming it into something more structured, like speech.
To make the model work better, the researchers also incorporate a "discriminative" model. This means the model can distinguish between good and bad speech samples, and use that information to guide the diffusion process and produce higher-quality results. The key advantage of this approach is that it can process audio in real-time, allowing for immediate speech enhancement without delays.
Technical Explanation
The paper proposes a novel speech enhancement framework that combines diffusion-based generative modeling with discriminative guidance. Diffusion models are known for their ability to generate high-quality samples, while discriminative models excel at differentiating between clean and noisy speech. By integrating these two approaches, the authors aim to leverage the strengths of both to achieve state-of-the-art speech enhancement performance in a streamable setting.
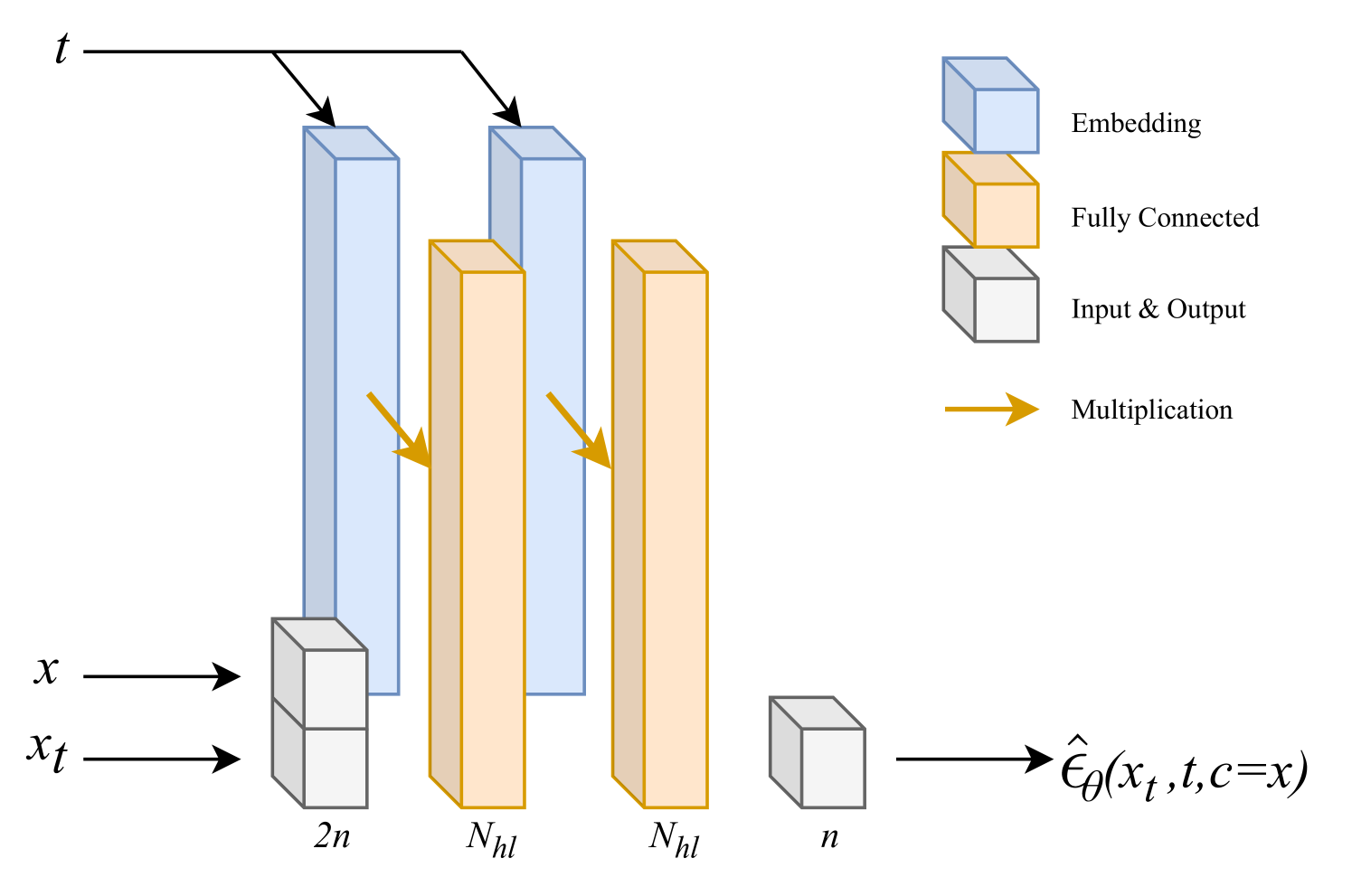
The model architecture consists of a diffusion-based generative model that generates the enhanced speech, and a discriminative model that provides guidance to the diffusion process. The discriminative model is trained to classify clean and noisy speech, and this information is used to guide the diffusion model towards generating more realistic and high-quality enhanced speech samples.
The authors also introduce a novel training strategy that combines self-supervised learning and feature-guided diffusion to further improve the model's performance.
Critical Analysis
The paper presents a promising approach for streamable speech enhancement, leveraging the strengths of both diffusion-based and discriminative models. The authors have carefully designed the model architecture and training process to address the challenges of real-time speech processing.
One potential limitation of the approach is the reliance on the discriminative model's ability to accurately classify clean and noisy speech samples. If the discriminative model is not well-trained or struggles with certain types of noise, this could introduce errors or biases into the diffusion process and the final enhanced speech output.
Additionally, the paper does not provide a detailed analysis of the computational complexity and latency of the proposed model, which are crucial factors for real-time speech enhancement applications. Further investigation into the trade-offs between performance and computational efficiency would be valuable.
Conclusion
This paper presents an innovative approach for speech enhancement that combines the strengths of diffusion-based generative modeling and discriminative guidance. By leveraging both generative and discriminative capabilities, the proposed model is able to generate high-quality enhanced speech in a streamable setting, potentially enabling real-time applications such as noise reduction in video conferencing or improving the clarity of voice assistants.
The research highlights the potential of hybrid models that integrate different machine learning techniques to solve complex problems. As the field of speech processing continues to evolve, approaches like the one described in this paper may pave the way for more advanced and practical speech enhancement solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diffusion-based Generative Modeling with Discriminative Guidance for Streamable Speech Enhancement
Chenda Li, Samuele Cornell, Shinji Watanabe, Yanmin Qian
Diffusion-based generative models (DGMs) have recently attracted attention in speech enhancement research (SE) as previous works showed a remarkable generalization capability. However, DGMs are also computationally intensive, as they usually require many iterations in the reverse diffusion process (RDP), making them impractical for streaming SE systems. In this paper, we propose to use discriminative scores from discriminative models in the first steps of the RDP. These discriminative scores require only one forward pass with the discriminative model for multiple RDP steps, thus greatly reducing computations. This approach also allows for performance improvements. We show that we can trade off between generative and discriminative capabilities as the number of steps with the discriminative score increases. Furthermore, we propose a novel streamable time-domain generative model with an algorithmic latency of 50 ms, which has no significant performance degradation compared to offline models.
Read more6/21/2024

0
New!Extract and Diffuse: Latent Integration for Improved Diffusion-based Speech and Vocal Enhancement
Yudong Yang, Zhan Liu, Wenyi Yu, Guangzhi Sun, Qiuqiang Kong, Chao Zhang
Diffusion-based generative models have recently achieved remarkable results in speech and vocal enhancement due to their ability to model complex speech data distributions. While these models generalize well to unseen acoustic environments, they may not achieve the same level of fidelity as the discriminative models specifically trained to enhance particular acoustic conditions. In this paper, we propose Ex-Diff, a novel score-based diffusion model that integrates the latent representations produced by a discriminative model to improve speech and vocal enhancement, which combines the strengths of both generative and discriminative models. Experimental results on the widely used MUSDB dataset show relative improvements of 3.7% in SI-SDR and 10.0% in SI-SIR compared to the baseline diffusion model for speech and vocal enhancement tasks, respectively. Additionally, case studies are provided to further illustrate and analyze the complementary nature of generative and discriminative models in this context.
Read more9/17/2024

0
Improving Discrete Diffusion Models via Structured Preferential Generation
Severi Rissanen, Markus Heinonen, Arno Solin
In the domains of image and audio, diffusion models have shown impressive performance. However, their application to discrete data types, such as language, has often been suboptimal compared to autoregressive generative models. This paper tackles the challenge of improving discrete diffusion models by introducing a structured forward process that leverages the inherent information hierarchy in discrete categories, such as words in text. Our approach biases the generative process to produce certain categories before others, resulting in a notable improvement in log-likelihood scores on the text8 dataset. This work paves the way for more advances in discrete diffusion models with potentially significant enhancements in performance.
Read more5/29/2024
0
Diffusion Models for Accurate Channel Distribution Generation
Muah Kim, Rick Fritschek, Rafael F. Schaefer
Strong generative models can accurately learn channel distributions. This could save recurring costs for physical measurements of the channel. Moreover, the resulting differentiable channel model supports training neural encoders by enabling gradient-based optimization. The initial approach in the literature draws upon the modern advancements in image generation, utilizing generative adversarial networks (GANs) or their enhanced variants to generate channel distributions. In this paper, we address this channel approximation challenge with diffusion models (DMs), which have demonstrated high sample quality and mode coverage in image generation. In addition to testing the generative performance of the channel distributions, we use an end-to-end (E2E) coded-modulation framework underpinned by DMs and propose an efficient training algorithm. Our simulations with various channel models show that a DM can accurately learn channel distributions, enabling an E2E framework to achieve near-optimal symbol error rates (SERs). Furthermore, we examine the trade-off between mode coverage and sampling speed through skipped sampling using sliced Wasserstein distance (SWD) and the E2E SER. We investigate the effect of noise scheduling on this trade-off, demonstrating that with an appropriate choice of parameters and techniques, sampling time can be significantly reduced with a minor increase in SWD and SER. Finally, we show that the DM can generate a correlated fading channel, whereas a strong GAN variant fails to learn the covariance. This paper highlights the potential benefits of using DMs for learning channel distributions, which could be further investigated for various channels and advanced techniques of DMs.
Read more6/12/2024