Diffusion Model is a Good Pose Estimator from 3D RF-Vision

0

Sign in to get full access
Overview
- The paper proposes using a diffusion model as a pose estimator from 3D RF-vision data.
- Key findings include that diffusion models can outperform common pose estimation approaches on mmWave radar datasets.
- The authors conduct experiments to demonstrate the effectiveness of their approach.
Plain English Explanation
The research paper explores using a diffusion model, a type of machine learning technique, to estimate the 3D human pose from radio frequency (RF) vision data. Diffusion models are a family of AI models that can learn complex data distributions, such as the patterns in 3D human body poses.
The researchers found that diffusion models can be very effective at predicting human poses from mmWave radar sensor data. This is useful because mmWave radar can capture 3D information about people's movements, which is valuable for applications like human-computer interaction, sports analytics, and healthcare monitoring.
Compared to other common pose estimation methods, the diffusion model approach was able to more accurately predict the 3D positions of different body parts. The authors believe this is because diffusion models can better learn the complex patterns and relationships in human pose data.
Technical Explanation
The paper presents a diffusion model-based approach for 3D human pose estimation from mmWave radar data. Diffusion models are a type of generative AI model that can learn to produce realistic samples of complex data, such as human poses, by iteratively adding and removing noise.
The researchers train their diffusion model on 3D human poses extracted from mmWave radar data. During inference, the model takes in radar data and progressively refines an initial random pose guess to output the final estimated 3D pose. The authors compare this approach to other standard pose estimation techniques like 3D keypoint regression and show that the diffusion model achieves superior performance on benchmark mmWave datasets.
The key insight is that the diffusion process allows the model to effectively capture the rich structure and correlations present in human pose data, leading to more accurate 3D pose predictions compared to direct regression approaches. The authors also analyze the model's internal representations and find that it learns meaningful skeletal features that aid in the pose estimation task.
Critical Analysis
The paper provides a thorough evaluation of the diffusion model's pose estimation capabilities, including comparisons to several baseline methods on publicly available datasets. However, the authors do not deeply discuss potential limitations or caveats of their approach.
For example, it's unclear how the diffusion model would perform in real-world scenarios with partial occlusions, variable sensor placements, or diverse body types. The paper also does not explore the computational efficiency of the diffusion model compared to other pose estimation techniques, which could be an important practical consideration.
Additionally, the authors do not speculate on future research directions or potential applications beyond the specific task of 3D pose estimation from mmWave data. Exploring how this diffusion-based approach could be extended to other RF-vision problems or integrated with other sensing modalities could provide valuable insights.
Conclusion
This research demonstrates that diffusion models can be a powerful tool for 3D human pose estimation from mmWave radar data. By effectively learning the complex structure of human poses, the diffusion model outperforms more standard pose estimation techniques.
The results suggest that diffusion models may be a promising direction for advancing RF-based human sensing and interaction applications. Further research is needed to explore the broader applicability of this approach and address potential real-world challenges, but this work represents an important step forward in the field of 3D pose estimation from RF-vision data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diffusion Model is a Good Pose Estimator from 3D RF-Vision
Junqiao Fan, Jianfei Yang, Yuecong Xu, Lihua Xie
Human pose estimation (HPE) from Radio Frequency vision (RF-vision) performs human sensing using RF signals that penetrate obstacles without revealing privacy (e.g., facial information). Recently, mmWave radar has emerged as a promising RF-vision sensor, providing radar point clouds by processing RF signals. However, the mmWave radar has a limited resolution with severe noise, leading to inaccurate and inconsistent human pose estimation. This work proposes mmDiff, a novel diffusion-based pose estimator tailored for noisy radar data. Our approach aims to provide reliable guidance as conditions to diffusion models. Two key challenges are addressed by mmDiff: (1) miss-detection of parts of human bodies, which is addressed by a module that isolates feature extraction from different body parts, and (2) signal inconsistency due to environmental interference, which is tackled by incorporating prior knowledge of body structure and motion. Several modules are designed to achieve these goals, whose features work as the conditions for the subsequent diffusion model, eliminating the miss-detection and instability of HPE based on RF-vision. Extensive experiments demonstrate that mmDiff outperforms existing methods significantly, achieving state-of-the-art performances on public datasets.
Read more7/23/2024
🎲
0
ProbRadarM3F: mmWave Radar based Human Skeletal Pose Estimation with Probability Map Guided Multi-Format Feature Fusion
Bing Zhu, Zixin He, Weiyi Xiong, Guanhua Ding, Jianan Liu, Tao Huang, Wei Chen, Wei Xiang
Millimeter wave (mmWave) radar is a non-intrusive privacy and relatively convenient and inexpensive device, which has been demonstrated to be applicable in place of RGB cameras in human indoor pose estimation tasks. However, mmWave radar relies on the collection of reflected signals from the target, and the radar signals containing information is difficult to be fully applied. This has been a long-standing hindrance to the improvement of pose estimation accuracy. To address this major challenge, this paper introduces a probability map guided multi-format feature fusion model, ProbRadarM3F. This is a novel radar feature extraction framework using a traditional FFT method in parallel with a probability map based positional encoding method. ProbRadarM3F fuses the traditional heatmap features and the positional features, then effectively achieves the estimation of 14 keypoints of the human body. Experimental evaluation on the HuPR dataset proves the effectiveness of the model proposed in this paper, outperforming other methods experimented on this dataset with an AP of 69.9 %. The emphasis of our study is focusing on the position information that is not exploited before in radar singal. This provides direction to investigate other potential non-redundant information from mmWave rader.
Read more7/1/2024
0
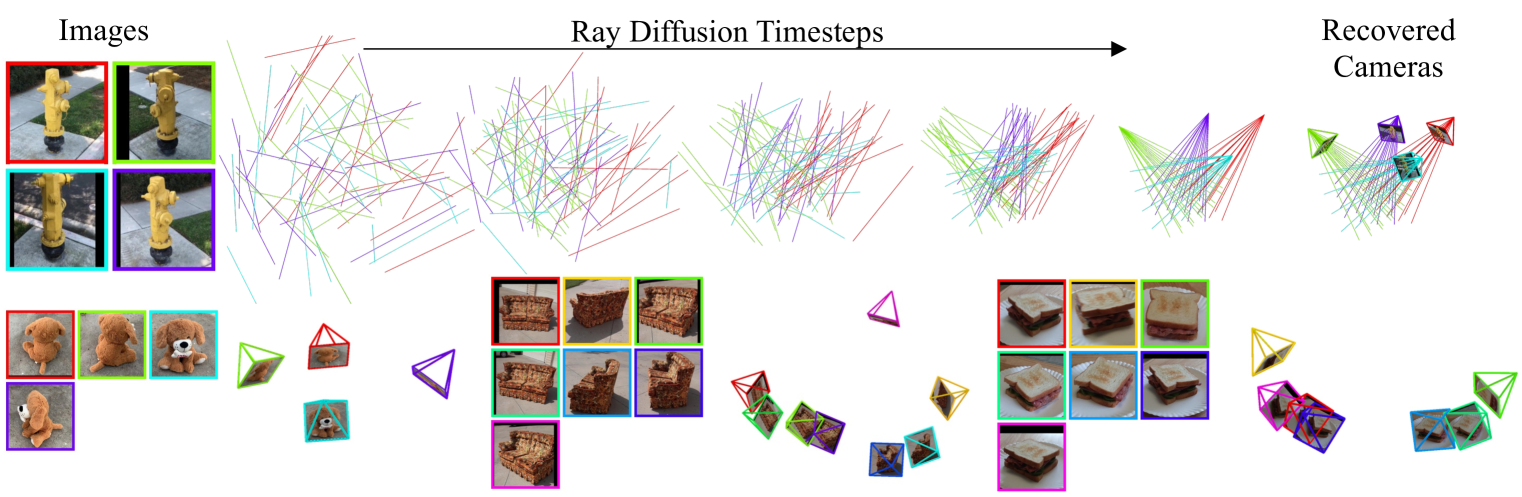
Cameras as Rays: Pose Estimation via Ray Diffusion
Jason Y. Zhang, Amy Lin, Moneish Kumar, Tzu-Hsuan Yang, Deva Ramanan, Shubham Tulsiani
Estimating camera poses is a fundamental task for 3D reconstruction and remains challenging given sparsely sampled views (<10). In contrast to existing approaches that pursue top-down prediction of global parametrizations of camera extrinsics, we propose a distributed representation of camera pose that treats a camera as a bundle of rays. This representation allows for a tight coupling with spatial image features improving pose precision. We observe that this representation is naturally suited for set-level transformers and develop a regression-based approach that maps image patches to corresponding rays. To capture the inherent uncertainties in sparse-view pose inference, we adapt this approach to learn a denoising diffusion model which allows us to sample plausible modes while improving performance. Our proposed methods, both regression- and diffusion-based, demonstrate state-of-the-art performance on camera pose estimation on CO3D while generalizing to unseen object categories and in-the-wild captures.
Read more4/5/2024
0
Object Pose Estimation via the Aggregation of Diffusion Features
Tianfu Wang, Guosheng Hu, Hongguang Wang
Estimating the pose of objects from images is a crucial task of 3D scene understanding, and recent approaches have shown promising results on very large benchmarks. However, these methods experience a significant performance drop when dealing with unseen objects. We believe that it results from the limited generalizability of image features. To address this problem, we have an in-depth analysis on the features of diffusion models, e.g. Stable Diffusion, which hold substantial potential for modeling unseen objects. Based on this analysis, we then innovatively introduce these diffusion features for object pose estimation. To achieve this, we propose three distinct architectures that can effectively capture and aggregate diffusion features of different granularity, greatly improving the generalizability of object pose estimation. Our approach outperforms the state-of-the-art methods by a considerable margin on three popular benchmark datasets, LM, O-LM, and T-LESS. In particular, our method achieves higher accuracy than the previous best arts on unseen objects: 98.2% vs. 93.5% on Unseen LM, 85.9% vs. 76.3% on Unseen O-LM, showing the strong generalizability of our method. Our code is released at https://github.com/Tianfu18/diff-feats-pose.
Read more6/4/2024