Diffusion Models With Learned Adaptive Noise
2312.13236
0
0
🚀
Abstract
Diffusion models have gained traction as powerful algorithms for synthesizing high-quality images. Central to these algorithms is the diffusion process, a set of equations which maps data to noise in a way that can significantly affect performance. In this paper, we explore whether the diffusion process can be learned from data. Our work is grounded in Bayesian inference and seeks to improve log-likelihood estimation by casting the learned diffusion process as an approximate variational posterior that yields a tighter lower bound (ELBO) on the likelihood. A widely held assumption is that the ELBO is invariant to the noise process: our work dispels this assumption and proposes multivariate learned adaptive noise (MULAN), a learned diffusion process that applies noise at different rates across an image. Specifically, our method relies on a multivariate noise schedule that is a function of the data to ensure that the ELBO is no longer invariant to the choice of the noise schedule as in previous works. Empirically, MULAN sets a new state-of-the-art in density estimation on CIFAR-10 and ImageNet and reduces the number of training steps by 50%. Code is available at https://github.com/s-sahoo/MuLAN
Create account to get full access
Overview
- Diffusion models are powerful algorithms for generating high-quality images
- The diffusion process, a set of equations that map data to noise, is central to these models
- This paper explores whether the diffusion process can be learned from data
- The goal is to improve log-likelihood estimation by casting the learned diffusion process as an approximate variational posterior
Plain English Explanation
Diffusion models are a type of artificial intelligence that can create realistic-looking images. At the heart of these models is the "diffusion process" - a set of mathematical equations that gradually transform the original data (like a photo) into random noise.
This paper investigates whether the diffusion process itself can be learned from data, rather than being pre-defined. The researchers believe that by learning the diffusion process, they can improve the models' ability to estimate the likelihood of the original data. This is important because it allows the models to generate images that are more true to the training data.
The key idea is to treat the learned diffusion process as an "approximate variational posterior" - a probability distribution that approximates the true, but unknown, distribution of the data. This leads to a tighter lower bound on the likelihood, meaning the model can better estimate how likely the original data is.
Importantly, the researchers challenge the assumption that the quality of this likelihood estimate is independent of the specific noise process used. Instead, they propose a "multivariate learned adaptive noise" (MULAN) approach, where the noise is applied at different rates across the image. This helps the model further improve its likelihood estimates.
Technical Explanation
The core of this work is centered around improving the log-likelihood estimation in diffusion models by learning the diffusion process itself. The authors ground their approach in Bayesian inference and cast the learned diffusion process as an approximate variational posterior. This yields a tighter lower bound (the ELBO) on the true data likelihood.
Previous work has assumed that the ELBO is invariant to the choice of noise process used in the diffusion. However, the authors show this assumption does not hold. They propose the MULAN method, which uses a multivariate noise schedule that adapts based on the input data. This ensures the ELBO is no longer invariant to the noise schedule, allowing for further improvements in density estimation.
Empirically, the authors demonstrate that MULAN sets a new state-of-the-art in density estimation on CIFAR-10 and ImageNet datasets. Additionally, their method reduces the number of training steps required by 50% compared to previous approaches.
The authors' work builds upon and extends several related efforts in this space, including physics-informed diffusion models, versatile diffusion transformer with mixture of noise levels, stimulating diffusion models for image denoising, and learning mixtures of Gaussians using diffusion models.
Critical Analysis
The paper makes a compelling case for learning the diffusion process in diffusion models, rather than relying on a pre-defined one. By treating the learned diffusion process as an approximate variational posterior, the authors are able to derive a tighter lower bound on the likelihood, which is a significant theoretical contribution.
However, the paper does not address some potential limitations of this approach. For example, the learned diffusion process may be more computationally expensive or harder to optimize than a pre-defined one. Additionally, the authors do not explore the potential for the learned diffusion process to over-fit the training data, which could limit the model's ability to generalize to new samples.
Another area for further research would be to investigate the interpretability of the learned diffusion process. Understanding how the model adapts the noise schedule based on the input data could lead to valuable insights about the underlying structure of the data and the diffusion process itself.
Overall, this paper represents an important step forward in the development of more powerful and flexible diffusion models. By challenging the assumption of ELBO invariance and proposing the MULAN method, the authors have made a significant contribution to the field of generative modeling.
Conclusion
This paper introduces a novel approach to improving the performance of diffusion models by learning the diffusion process itself, rather than using a pre-defined one. By casting the learned diffusion process as an approximate variational posterior, the authors are able to derive a tighter lower bound on the data likelihood, leading to better density estimation and faster training.
The key innovation is the MULAN method, which uses a multivariate noise schedule that adapts to the input data. This ensures the ELBO is no longer invariant to the choice of noise process, allowing for further improvements in the model's ability to capture the underlying data distribution.
Empirically, the authors show that MULAN sets a new state-of-the-art in density estimation on CIFAR-10 and ImageNet, while also reducing the number of training steps required by 50%. This represents a significant advancement in the field of generative modeling and could have important implications for a wide range of applications that rely on high-quality image synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
Physics-Informed Diffusion Models
Jan-Hendrik Bastek, WaiChing Sun, Dennis M. Kochmann
0
0
Generative models such as denoising diffusion models are quickly advancing their ability to approximate highly complex data distributions. They are also increasingly leveraged in scientific machine learning, where samples from the implied data distribution are expected to adhere to specific governing equations. We present a framework to inform denoising diffusion models of underlying constraints on such generated samples during model training. Our approach improves the alignment of the generated samples with the imposed constraints and significantly outperforms existing methods without affecting inference speed. Additionally, our findings suggest that incorporating such constraints during training provides a natural regularization against overfitting. Our framework is easy to implement and versatile in its applicability for imposing equality and inequality constraints as well as auxiliary optimization objectives.
5/24/2024
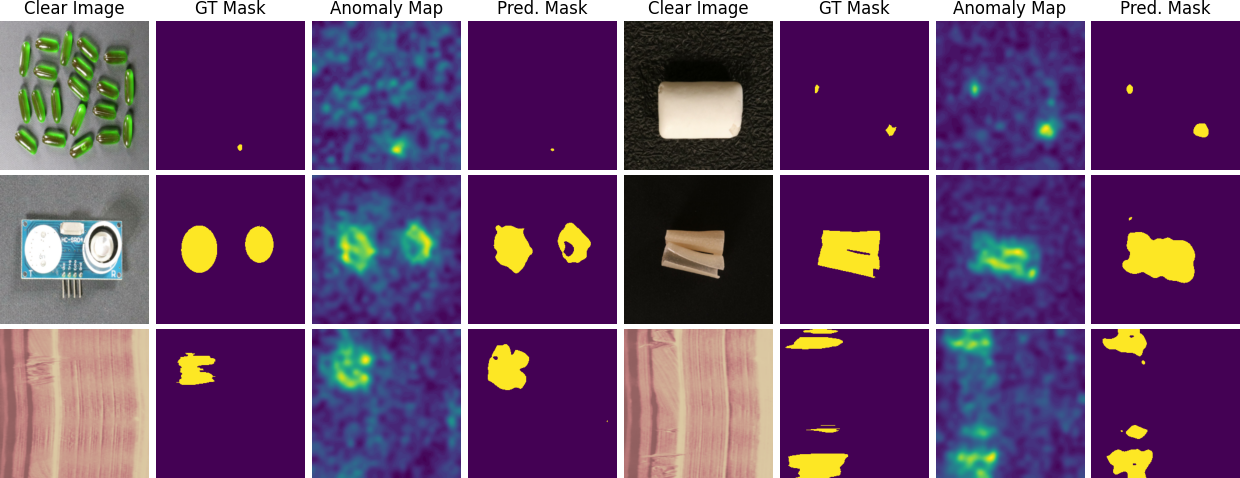
Dynamic Addition of Noise in a Diffusion Model for Anomaly Detection
Justin Tebbe, Jawad Tayyub
0
0
Diffusion models have found valuable applications in anomaly detection by capturing the nominal data distribution and identifying anomalies via reconstruction. Despite their merits, they struggle to localize anomalies of varying scales, especially larger anomalies such as entire missing components. Addressing this, we present a novel framework that enhances the capability of diffusion models, by extending the previous introduced implicit conditioning approach Meng et al. (2022) in three significant ways. First, we incorporate a dynamic step size computation that allows for variable noising steps in the forward process guided by an initial anomaly prediction. Second, we demonstrate that denoising an only scaled input, without any added noise, outperforms conventional denoising process. Third, we project images in a latent space to abstract away from fine details that interfere with reconstruction of large missing components. Additionally, we propose a fine-tuning mechanism that facilitates the model to effectively grasp the nuances of the target domain. Our method undergoes rigorous evaluation on prominent anomaly detection datasets VisA, BTAD and MVTec yielding strong performance. Importantly, our framework effectively localizes anomalies regardless of their scale, marking a pivotal advancement in diffusion-based anomaly detection.
6/26/2024
Stimulating the Diffusion Model for Image Denoising via Adaptive Embedding and Ensembling
Tong Li, Hansen Feng, Lizhi Wang, Zhiwei Xiong, Hua Huang
0
0
Image denoising is a fundamental problem in computational photography, where achieving high perception with low distortion is highly demanding. Current methods either struggle with perceptual quality or suffer from significant distortion. Recently, the emerging diffusion model has achieved state-of-the-art performance in various tasks and demonstrates great potential for image denoising. However, stimulating diffusion models for image denoising is not straightforward and requires solving several critical problems. For one thing, the input inconsistency hinders the connection between diffusion models and image denoising. For another, the content inconsistency between the generated image and the desired denoised image introduces distortion. To tackle these problems, we present a novel strategy called the Diffusion Model for Image Denoising (DMID) by understanding and rethinking the diffusion model from a denoising perspective. Our DMID strategy includes an adaptive embedding method that embeds the noisy image into a pre-trained unconditional diffusion model and an adaptive ensembling method that reduces distortion in the denoised image. Our DMID strategy achieves state-of-the-art performance on both distortion-based and perception-based metrics, for both Gaussian and real-world image denoising.The code is available at https://github.com/Li-Tong-621/DMID.
4/16/2024
A Versatile Diffusion Transformer with Mixture of Noise Levels for Audiovisual Generation
Gwanghyun Kim, Alonso Martinez, Yu-Chuan Su, Brendan Jou, Jos'e Lezama, Agrim Gupta, Lijun Yu, Lu Jiang, Aren Jansen, Jacob Walker, Krishna Somandepalli
0
0
Training diffusion models for audiovisual sequences allows for a range of generation tasks by learning conditional distributions of various input-output combinations of the two modalities. Nevertheless, this strategy often requires training a separate model for each task which is expensive. Here, we propose a novel training approach to effectively learn arbitrary conditional distributions in the audiovisual space.Our key contribution lies in how we parameterize the diffusion timestep in the forward diffusion process. Instead of the standard fixed diffusion timestep, we propose applying variable diffusion timesteps across the temporal dimension and across modalities of the inputs. This formulation offers flexibility to introduce variable noise levels for various portions of the input, hence the term mixture of noise levels. We propose a transformer-based audiovisual latent diffusion model and show that it can be trained in a task-agnostic fashion using our approach to enable a variety of audiovisual generation tasks at inference time. Experiments demonstrate the versatility of our method in tackling cross-modal and multimodal interpolation tasks in the audiovisual space. Notably, our proposed approach surpasses baselines in generating temporally and perceptually consistent samples conditioned on the input. Project page: avdit2024.github.io
5/24/2024