Diffusion Spectral Representation for Reinforcement Learning

0

Sign in to get full access
Overview
- This paper introduces a novel representation called the Diffusion Spectral Representation (DSR) for reinforcement learning.
- The DSR aims to capture the long-term behavior of Markov Decision Processes (MDPs) using the spectrum of the diffusion operator.
- The authors demonstrate that the DSR can be used to derive new RL algorithms with improved exploration and value estimation.
Plain English Explanation
The paper explores a new way to represent the environment in reinforcement learning (RL) problems. In RL, an agent interacts with an environment, taking actions and receiving rewards, with the goal of learning an optimal policy. The authors introduce the Diffusion Spectral Representation (DSR), which captures the long-term behavior of the environment using the mathematical concept of a diffusion operator.
The key idea is that the spectrum (or set of eigenvalues) of the diffusion operator can provide valuable information about the structure of the environment, such as the presence of bottlenecks or hierarchical organization. By incorporating this spectral information into the RL agent's representation of the environment, the authors show that it can lead to improved exploration and more accurate value estimation, ultimately resulting in better learning performance.
The paper demonstrates the benefits of the DSR approach through experiments on several RL benchmark tasks. The results suggest that the DSR can outperform traditional RL methods, particularly in environments with complex dynamics or sparse rewards, where the spectral information can help the agent navigate the environment more effectively.
Technical Explanation
The paper introduces the Diffusion Spectral Representation (DSR) for reinforcement learning. The DSR is based on the idea of capturing the long-term behavior of Markov Decision Processes (MDPs) using the spectrum of the diffusion operator associated with the MDP.
The authors first provide the necessary background on diffusion processes and their spectral representation. They then show how the spectrum of the diffusion operator can be used to derive a compact and informative representation of the MDP, which they call the DSR.
The key insight is that the eigenvalues and eigenfunctions of the diffusion operator encode important information about the structure of the MDP, such as the presence of bottlenecks, metastable states, and hierarchical organization. By incorporating this spectral information into the RL agent's representation of the environment, the authors demonstrate that it can lead to improved exploration strategies and more accurate value estimation.
The paper presents several RL algorithms that leverage the DSR, such as a variant of Q-learning and a policy gradient method. The authors evaluate these algorithms on a variety of benchmark RL tasks and show that they can outperform traditional RL methods, particularly in environments with complex dynamics or sparse rewards.
Critical Analysis
The paper presents a novel and promising approach to representation learning in reinforcement learning. The Diffusion Spectral Representation (DSR) is an interesting idea that has the potential to capture important structural information about the environment, which can be leveraged to improve RL performance.
One notable aspect of the DSR is its ability to handle complex environments with long-term dependencies and hierarchical structure. By focusing on the spectrum of the diffusion operator, the DSR can potentially identify important bottlenecks or metastable states in the environment, which can guide the agent's exploration and value estimation.
However, the paper does not provide a comprehensive analysis of the limitations or potential issues with the DSR approach. For example, the computational complexity of computing the diffusion operator and its spectrum may be a practical concern, particularly for large-scale or high-dimensional environments. Additionally, the reliance on the specific structure of the MDP may limit the generalizability of the DSR to more complex or partially observable environments.
Further research could explore the robustness of the DSR to noisy or uncertain environments, as well as its scalability to larger problem domains. Comparisons with other state-of-the-art representation learning techniques in RL, such as diffusion models for image super-resolution or multi-resolution diffusion for privacy-sensitive recommender systems, could also provide valuable insights.
Conclusion
The Diffusion Spectral Representation (DSR) introduced in this paper offers a novel and promising approach to representation learning in reinforcement learning. By capturing the long-term behavior of Markov Decision Processes using the spectrum of the diffusion operator, the DSR can potentially improve exploration and value estimation, leading to better overall performance.
The paper demonstrates the advantages of the DSR through experiments on several RL benchmark tasks, showing that it can outperform traditional RL methods, particularly in complex environments. While the DSR shows promise, further research is needed to address potential limitations, such as computational complexity and generalizability to more diverse environments.
Overall, the DSR represents an exciting development in the field of reinforcement learning, with the potential to unlock new insights and capabilities for agents navigating complex and challenging environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diffusion Spectral Representation for Reinforcement Learning
Dmitry Shribak, Chen-Xiao Gao, Yitong Li, Chenjun Xiao, Bo Dai
Diffusion-based models have achieved notable empirical successes in reinforcement learning (RL) due to their expressiveness in modeling complex distributions. Despite existing methods being promising, the key challenge of extending existing methods for broader real-world applications lies in the computational cost at inference time, i.e., sampling from a diffusion model is considerably slow as it often requires tens to hundreds of iterations to generate even one sample. To circumvent this issue, we propose to leverage the flexibility of diffusion models for RL from a representation learning perspective. In particular, by exploiting the connection between diffusion model and energy-based model, we develop Diffusion Spectral Representation (Diff-SR), a coherent algorithm framework that enables extracting sufficient representations for value functions in Markov decision processes (MDP) and partially observable Markov decision processes (POMDP). We further demonstrate how Diff-SR facilitates efficient policy optimization and practical algorithms while explicitly bypassing the difficulty and inference cost of sampling from the diffusion model. Finally, we provide comprehensive empirical studies to verify the benefits of Diff-SR in delivering robust and advantageous performance across various benchmarks with both fully and partially observable settings.
Read more6/26/2024

0
Diffusion Models and Representation Learning: A Survey
Michael Fuest, Pingchuan Ma, Ming Gui, Johannes S. Fischer, Vincent Tao Hu, Bjorn Ommer
Diffusion Models are popular generative modeling methods in various vision tasks, attracting significant attention. They can be considered a unique instance of self-supervised learning methods due to their independence from label annotation. This survey explores the interplay between diffusion models and representation learning. It provides an overview of diffusion models' essential aspects, including mathematical foundations, popular denoising network architectures, and guidance methods. Various approaches related to diffusion models and representation learning are detailed. These include frameworks that leverage representations learned from pre-trained diffusion models for subsequent recognition tasks and methods that utilize advancements in representation and self-supervised learning to enhance diffusion models. This survey aims to offer a comprehensive overview of the taxonomy between diffusion models and representation learning, identifying key areas of existing concerns and potential exploration. Github link: https://github.com/dongzhuoyao/Diffusion-Representation-Learning-Survey-Taxonomy
Read more7/2/2024

0
Feedback Efficient Online Fine-Tuning of Diffusion Models
Masatoshi Uehara, Yulai Zhao, Kevin Black, Ehsan Hajiramezanali, Gabriele Scalia, Nathaniel Lee Diamant, Alex M Tseng, Sergey Levine, Tommaso Biancalani
Diffusion models excel at modeling complex data distributions, including those of images, proteins, and small molecules. However, in many cases, our goal is to model parts of the distribution that maximize certain properties: for example, we may want to generate images with high aesthetic quality, or molecules with high bioactivity. It is natural to frame this as a reinforcement learning (RL) problem, in which the objective is to fine-tune a diffusion model to maximize a reward function that corresponds to some property. Even with access to online queries of the ground-truth reward function, efficiently discovering high-reward samples can be challenging: they might have a low probability in the initial distribution, and there might be many infeasible samples that do not even have a well-defined reward (e.g., unnatural images or physically impossible molecules). In this work, we propose a novel reinforcement learning procedure that efficiently explores on the manifold of feasible samples. We present a theoretical analysis providing a regret guarantee, as well as empirical validation across three domains: images, biological sequences, and molecules.
Read more7/19/2024
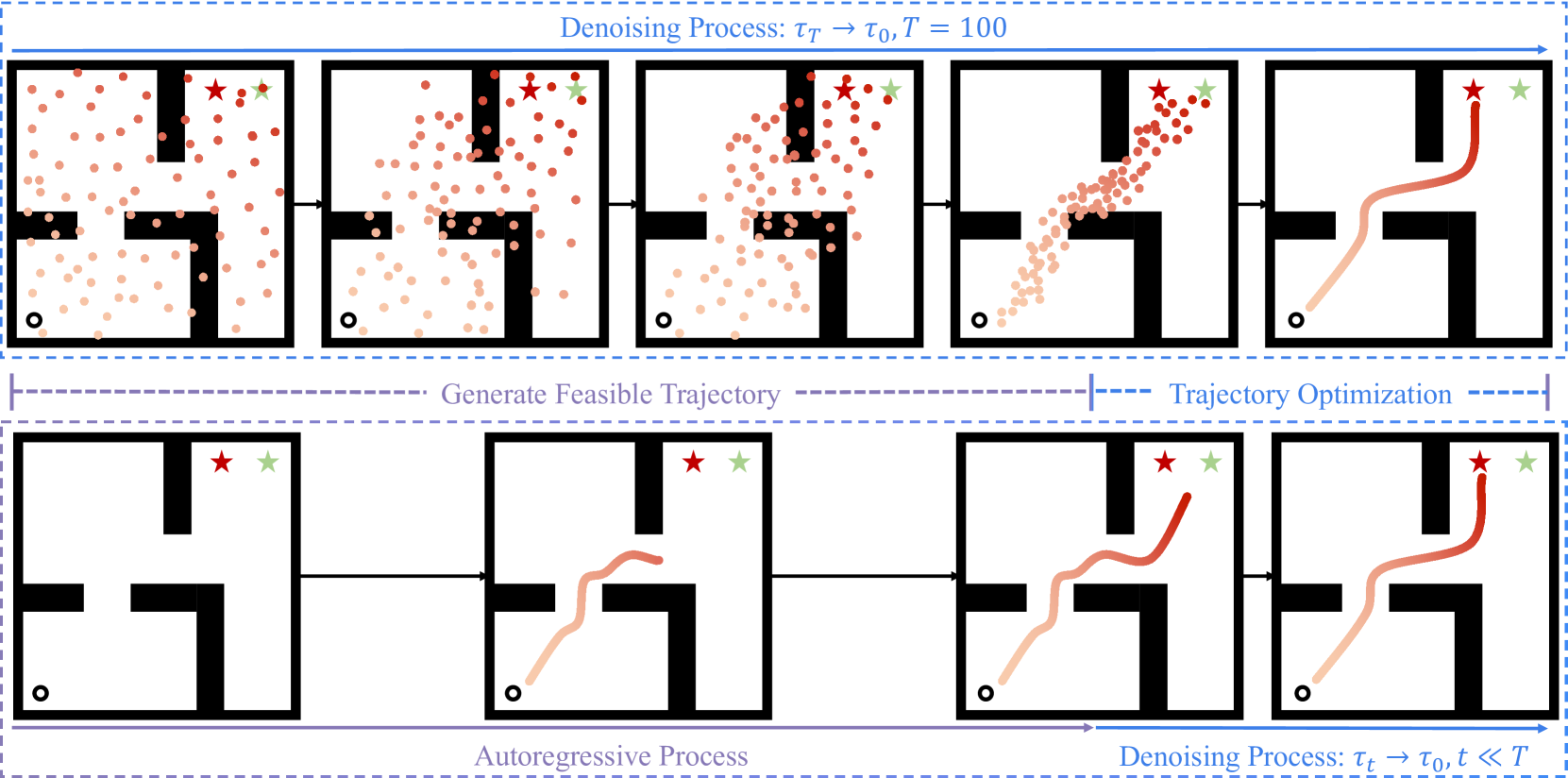
0
Diffusion Models as Optimizers for Efficient Planning in Offline RL
Renming Huang, Yunqiang Pei, Guoqing Wang, Yangming Zhang, Yang Yang, Peng Wang, Hengtao Shen
Diffusion models have shown strong competitiveness in offline reinforcement learning tasks by formulating decision-making as sequential generation. However, the practicality of these methods is limited due to the lengthy inference processes they require. In this paper, we address this problem by decomposing the sampling process of diffusion models into two decoupled subprocesses: 1) generating a feasible trajectory, which is a time-consuming process, and 2) optimizing the trajectory. With this decomposition approach, we are able to partially separate efficiency and quality factors, enabling us to simultaneously gain efficiency advantages and ensure quality assurance. We propose the Trajectory Diffuser, which utilizes a faster autoregressive model to handle the generation of feasible trajectories while retaining the trajectory optimization process of diffusion models. This allows us to achieve more efficient planning without sacrificing capability. To evaluate the effectiveness and efficiency of the Trajectory Diffuser, we conduct experiments on the D4RL benchmarks. The results demonstrate that our method achieves $it 3$-$it 10 times$ faster inference speed compared to previous sequence modeling methods, while also outperforming them in terms of overall performance. https://github.com/RenMing-Huang/TrajectoryDiffuser Keywords: Reinforcement Learning and Efficient Planning and Diffusion Model
Read more7/24/2024